 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Image: Pushing the Boundaries of Generative Visual Intelligence
Apr 21, 2026We present Wan-Image, a unified visual generation system explicitly engineered to paradigm-shift image generation models from casual synthesizers into professional-grade productivity tools. While contemporary diffusion models excel at aesthetic generation, they frequently encounter critical bottlenecks in rigorous design workflows that demand absolute controllability, complex typography rendering, and strict identity preservation. To address these challenges, Wan-Image features a natively unified multi-modal architecture by synergizing the cognitive capabilities of large language models with the high-fidelity pixel synthesis of diffusion transformers, which seamlessly translates highly nuanced user intents into precise visual outputs. It is fundamentally powered by large-scale multi-modal data scaling, a systematic fine-grained annotation engine, and curated reinforcement learning data to surpass basic instruction following and unlock expert-level professional capabilities. These include ultra-long complex text rendering, hyper-diverse portrait generation, palette-guided generation, multi-subject identity preservation, coherent sequential visual generation, precise multi-modal interactive editing, native alpha-channel generation, and high-efficiency 4K synthesis. Across diverse human evaluations, Wan-Image exceeds Seedream 5.0 Lite and GPT Image 1.5 in overall performance, reaching parity with Nano Banana Pro in challenging tasks. Ultimately, Wan-Image revolutionizes visual content creation across e-commerce, entertainment, education, and personal productivity, redefining the boundaries of professional visual synthesis.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning
Aug 13, 2024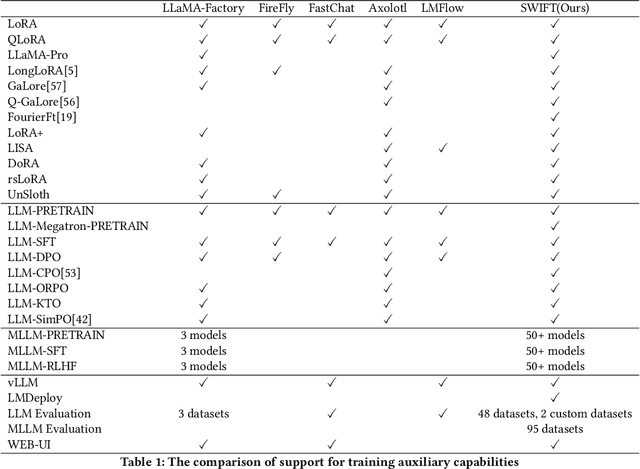
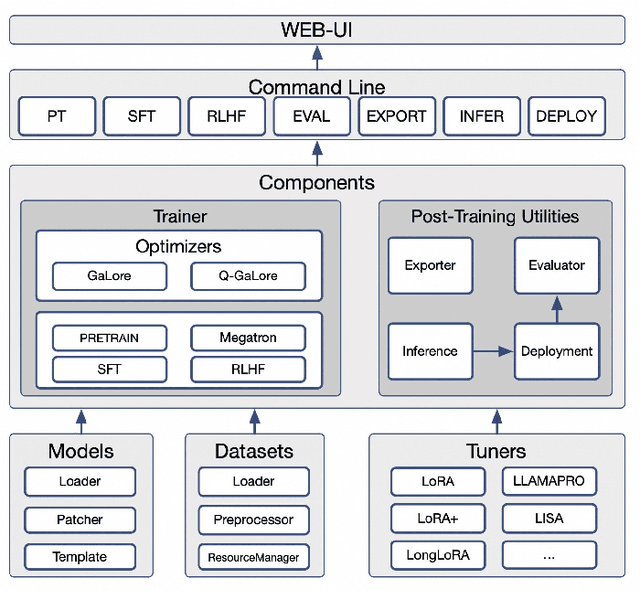


Recent development in Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) have leverage Attention-based Transformer architectures and achieved superior performance and generalization capabilities. They have since covered extensive areas of traditional learning tasks. For instance, text-based tasks such as text-classification and sequence-labeling, as well as multi-modal tasks like Visual Question Answering (VQA) and Optical Character Recognition (OCR), which were previously addressed using different models, can now be tackled based on one foundation model. Consequently, the training and lightweight fine-tuning of LLMs and MLLMs, especially those based on Transformer architecture, has become particularly important. In recognition of these overwhelming needs, we develop SWIFT, a customizable one-stop infrastructure for large models. With support of over $300+$ LLMs and $50+$ MLLMs, SWIFT stands as the open-source framework that provide the \textit{most comprehensive support} for fine-tuning large models. In particular, it is the first training framework that provides systematic support for MLLMs. In addition to the core functionalities of fine-tuning, SWIFT also integrates post-training processes such as inference, evaluation, and model quantization, to facilitate fast adoptions of large models in various application scenarios. With a systematic integration of various training techniques, SWIFT offers helpful utilities such as benchmark comparisons among different training techniques for large models. For fine-tuning models specialized in agent framework, we show that notable improvements on the ToolBench leader-board can be achieved by training with customized dataset on SWIFT, with an increase of 5.2%-21.8% in the Act.EM metric over various baseline models, a reduction in hallucination by 1.6%-14.1%, and an average performance improvement of 8%-17%.
Quiver: Supporting GPUs for Low-Latency, High-Throughput GNN Serving with Workload Awareness
May 18, 2023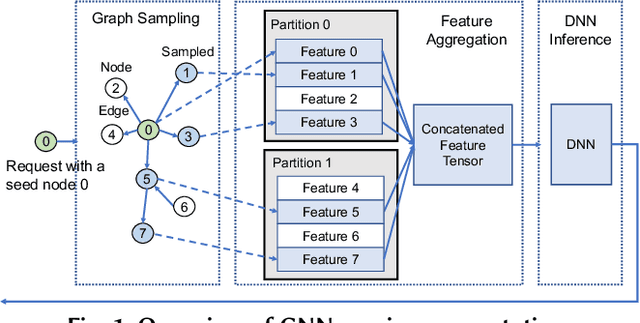
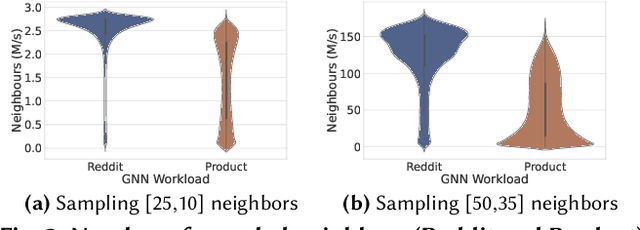
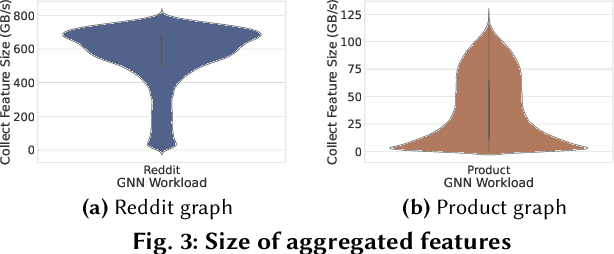
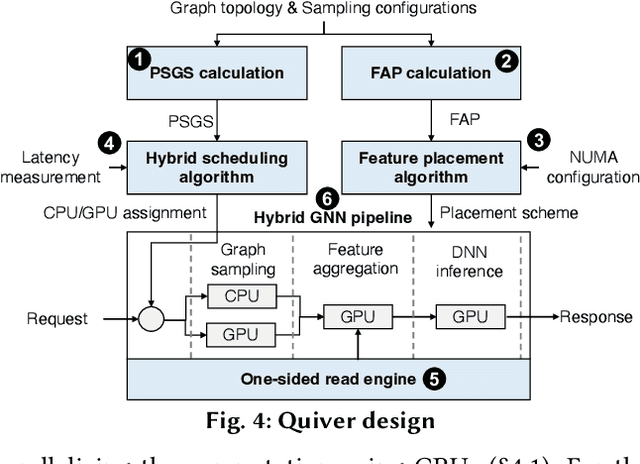
Systems for serving inference requests on graph neural networks (GNN) must combine low latency with high throughout, but they face irregular computation due to skew in the number of sampled graph nodes and aggregated GNN features. This makes it challenging to exploit GPUs effectively: using GPUs to sample only a few graph nodes yields lower performance than CPU-based sampling; and aggregating many features exhibits high data movement costs between GPUs and CPUs. Therefore, current GNN serving systems use CPUs for graph sampling and feature aggregation, limiting throughput. We describe Quiver, a distributed GPU-based GNN serving system with low-latency and high-throughput. Quiver's key idea is to exploit workload metrics for predicting the irregular computation of GNN requests, and governing the use of GPUs for graph sampling and feature aggregation: (1) for graph sampling, Quiver calculates the probabilistic sampled graph size, a metric that predicts the degree of parallelism in graph sampling. Quiver uses this metric to assign sampling tasks to GPUs only when the performance gains surpass CPU-based sampling; and (2) for feature aggregation, Quiver relies on the feature access probability to decide which features to partition and replicate across a distributed GPU NUMA topology. We show that Quiver achieves up to 35 times lower latency with an 8 times higher throughput compared to state-of-the-art GNN approaches (DGL and PyG).
Structure Enhanced Graph Neural Networks for Link Prediction
Jan 14, 2022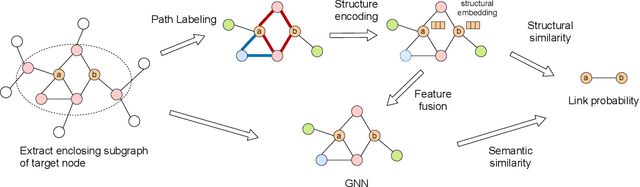
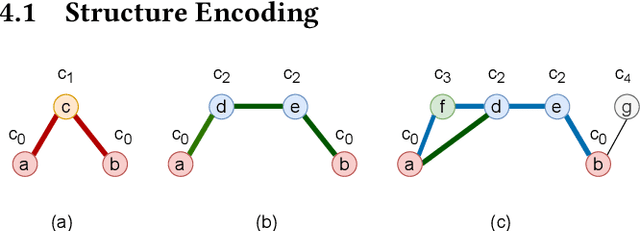
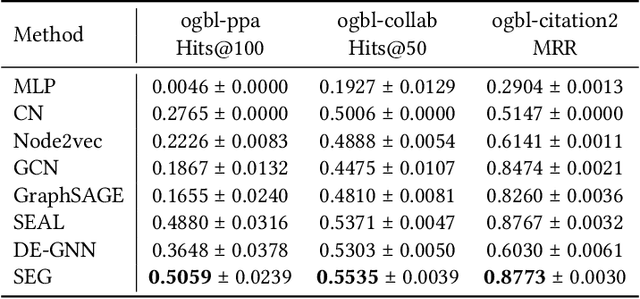
Graph Neural Networks (GNNs) have shown promising results in various tasks, among which link prediction is an important one. GNN models usually follow a node-centric message passing procedure that aggregates the neighborhood information to the central node recursively. Following this paradigm, features of nodes are passed through edges without caring about where the nodes are located and which role they played. However, the neglected topological information is shown to be valuable for link prediction tasks. In this paper, we propose Structure Enhanced Graph neural network (SEG) for link prediction. SEG introduces the path labeling method to capture surrounding topological information of target nodes and then incorporates the structure into an ordinary GNN model. By jointly training the structure encoder and deep GNN model, SEG fuses topological structures and node features to take full advantage of graph information. Experiments on the OGB link prediction datasets demonstrate that SEG achieves state-of-the-art results among all three public datasets.