 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatchGen: An Architecture for Scalable and Efficient Batch Inference
Jun 19, 2026Batch inference has become a central mode of AI computation, yet existing inference engines still rely on execution models designed for interactive serving. When scaled to millions of sequences, batch workloads reveal two fundamental requirements: the ability to handle extreme inter- and intra-sequence load variation that emerges only at runtime, and the ability to sustain high utilization across large fleets of GPUs. Existing systems fail to meet these requirements, losing substantial fractions of achievable throughput. We introduce a new architectural foundation for batch inference: the sequence coroutine compute model, which represents each sequence as a fine-grained, event-driven coroutine. This model exposes expressive primitives that allow the runtime to reorganize work dynamically, enabling larger expert-level batches, mitigating stragglers, reallocating work across devices, and maintaining utilization even on cost-effective or memory-constrained GPUs. Building on this abstraction, we implement BatchGen, a production-ready system that uses the coroutine model at cluster scale. On a 128-GPU cluster, BatchGen reduces batch completion time by up to $2.3\times$, and on memory-constrained accelerators it outperforms the strongest offloading baseline by up to $9.6\times$. We will open-source BatchGen at https://github.com/batchgen-project/batchgen
JustDiag!: A Diagnostic Justification Engine for Accountable Root Cause Analysis
Jun 17, 2026Large language models can produce fluent root cause analyses, but fluent final answers alone are insufficient evidence for accountability in high-stakes operations. In real incident response, engineers need to know what evidence supported a diagnosis, which alternatives were considered, where contradictions remained, and whether the system resolved the case or preserved uncertainty. We address this gap with JustDiag, a diagnostic justification engine for RCA that maintains an explicit process state over evidence, findings, competing hypotheses, conflicts, and next checks. We evaluated the system on 66 real-world incidents using a two-layer protocol that separately scores final-answer quality and process quality. Relative to a matched control without diagnostic justification, JustDiag achieved stronger outcome and process scores, while accepting slightly lower terminal completion due to more calibrated non-closure. These results suggest that accountable RCA requires explicit diagnostic justification artifacts and process-aware evaluation, not only fluent final answers.
MoE-CAP: Benchmarking Cost, Accuracy and Performance of Sparse Mixture-of-Experts Systems
May 16, 2025The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently, but it depends on heterogeneous compute and memory resources. These factors jointly affect system Cost, Accuracy, and Performance (CAP), making trade-offs inevitable. Existing benchmarks often fail to capture these trade-offs accurately, complicating practical deployment decisions. To address this, we introduce MoE-CAP, a benchmark specifically designed for MoE systems. Our analysis reveals that achieving an optimal balance across CAP is difficult with current hardware; MoE systems typically optimize two of the three dimensions at the expense of the third-a dynamic we term the MoE-CAP trade-off. To visualize this, we propose the CAP Radar Diagram. We further introduce sparsity-aware performance metrics-Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU)-to enable accurate performance benchmarking of MoE systems across diverse hardware platforms and deployment scenarios.
WaferLLM: A Wafer-Scale LLM Inference System
Feb 06, 2025Emerging AI accelerators increasingly adopt wafer-scale manufacturing technologies, integrating hundreds of thousands of AI cores in a mesh-based architecture with large distributed on-chip memory (tens of GB in total) and ultra-high on-chip memory bandwidth (tens of PB/s). However, current LLM inference systems, optimized for shared memory architectures like GPUs, fail to fully exploit these accelerators. We introduce WaferLLM, the first wafer-scale LLM inference system. WaferLLM is guided by a novel PLMR device model that captures the unique hardware characteristics of wafer-scale architectures. Leveraging this model, WaferLLM pioneers wafer-scale LLM parallelism, optimizing the utilization of hundreds of thousands of on-chip cores. It also introduces MeshGEMM and MeshGEMV, the first GEMM and GEMV implementations designed to scale effectively on wafer-scale accelerators. Evaluations show that WaferLLM achieves 200$\times$ better wafer-scale accelerator utilization than state-of-the-art systems. On a commodity wafer-scale accelerator, WaferLLM delivers 606$\times$ faster and 22$\times$ more energy-efficient GEMV compared to an advanced GPU. For LLMs, WaferLLM enables 39$\times$ faster decoding with 1.7$\times$ better energy efficiency. We anticipate these numbers will grow significantly as wafer-scale AI models, software, and hardware continue to mature.
MoE-CAP: Cost-Accuracy-Performance Benchmarking for Mixture-of-Experts Systems
Dec 10, 2024The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently; however, MoE systems rely on heterogeneous compute and memory resources. These factors collectively influence the system's Cost, Accuracy, and Performance (CAP), creating a challenging trade-off. Current benchmarks often fail to provide precise estimates of these effects, complicating practical considerations for deploying MoE systems. To bridge this gap, we introduce MoE-CAP, a benchmark specifically designed to evaluate MoE systems. Our findings highlight the difficulty of achieving an optimal balance of cost, accuracy, and performance with existing hardware capabilities. MoE systems often necessitate compromises on one factor to optimize the other two, a dynamic we term the MoE-CAP trade-off. To identify the best trade-off, we propose novel performance evaluation metrics - Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU) - and develop cost models that account for the heterogeneous compute and memory hardware integral to MoE systems. This benchmark is publicly available on HuggingFace: https://huggingface.co/spaces/sparse-generative-ai/open-moe-llm-leaderboard.
GEAR: A GPU-Centric Experience Replay System for Large Reinforcement Learning Models
Oct 08, 2023
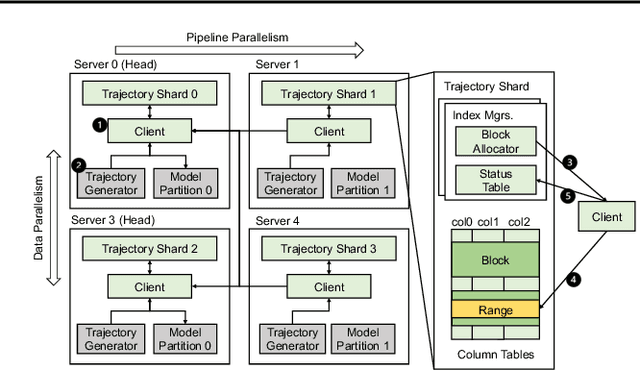


This paper introduces a distributed, GPU-centric experience replay system, GEAR, designed to perform scalable reinforcement learning (RL) with large sequence models (such as transformers). With such models, existing systems such as Reverb face considerable bottlenecks in memory, computation, and communication. GEAR, however, optimizes memory efficiency by enabling the memory resources on GPU servers (including host memory and device memory) to manage trajectory data. Furthermore, it facilitates decentralized GPU devices to expedite various trajectory selection strategies, circumventing computational bottlenecks. GEAR is equipped with GPU kernels capable of collecting trajectories using zero-copy access to host memory, along with remote-directed-memory access over InfiniBand, improving communication efficiency. Cluster experiments have shown that GEAR can achieve performance levels up to 6x greater than Reverb when training state-of-the-art large RL models. GEAR is open-sourced at https://github.com/bigrl-team/gear.
Quiver: Supporting GPUs for Low-Latency, High-Throughput GNN Serving with Workload Awareness
May 18, 2023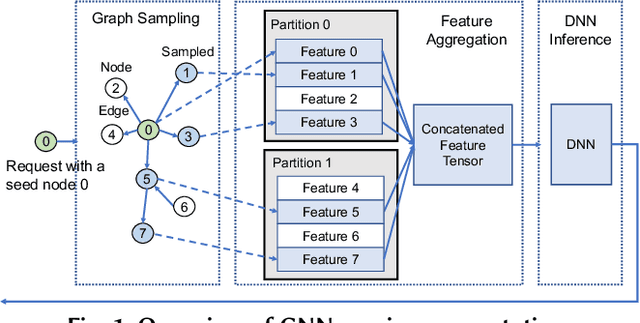
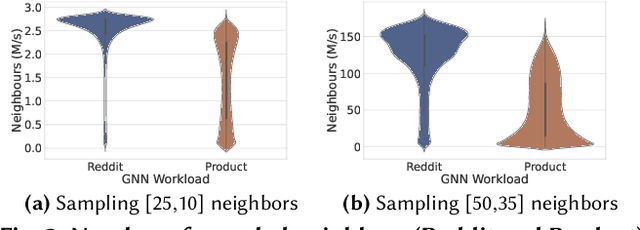
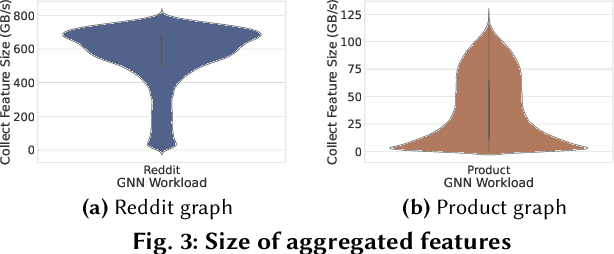
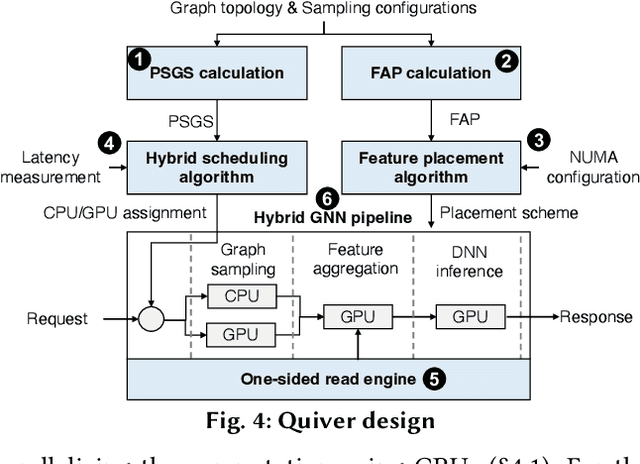
Systems for serving inference requests on graph neural networks (GNN) must combine low latency with high throughout, but they face irregular computation due to skew in the number of sampled graph nodes and aggregated GNN features. This makes it challenging to exploit GPUs effectively: using GPUs to sample only a few graph nodes yields lower performance than CPU-based sampling; and aggregating many features exhibits high data movement costs between GPUs and CPUs. Therefore, current GNN serving systems use CPUs for graph sampling and feature aggregation, limiting throughput. We describe Quiver, a distributed GPU-based GNN serving system with low-latency and high-throughput. Quiver's key idea is to exploit workload metrics for predicting the irregular computation of GNN requests, and governing the use of GPUs for graph sampling and feature aggregation: (1) for graph sampling, Quiver calculates the probabilistic sampled graph size, a metric that predicts the degree of parallelism in graph sampling. Quiver uses this metric to assign sampling tasks to GPUs only when the performance gains surpass CPU-based sampling; and (2) for feature aggregation, Quiver relies on the feature access probability to decide which features to partition and replicate across a distributed GPU NUMA topology. We show that Quiver achieves up to 35 times lower latency with an 8 times higher throughput compared to state-of-the-art GNN approaches (DGL and PyG).