 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs and Social Media to Understand User Perception of Smartphone-Based Earthquake Early Warnings
Mar 24, 2026Android's Earthquake Alert (AEA) system provided timely early warnings to millions during the Mw 6.2 Marmara Ereglisi, Türkiye earthquake on April 23, 2025. This event, the largest in the region in 25 years, served as a critical real-world test for smartphone-based Earthquake Early Warning (EEW) systems. The AEA system successfully delivered alerts to users with high precision, offering over a minute of warning before the strongest shaking reached urban areas. This study leveraged Large Language Models (LLMs) to analyze more than 500 public social media posts from the X platform, extracting 42 distinct attributes related to user experience and behavior. Statistical analyses revealed significant relationships, notably a strong correlation between user trust and alert timeliness. Our results indicate a distinction between engineering and the user-centric definition of system accuracy. We found that timeliness is accuracy in the user's mind. Overall, this study provides actionable insights for optimizing alert design, public education campaigns, and future behavioral research to improve the effectiveness of such systems in seismically active regions.
Towards Cold-Start Drafting and Continual Refining: A Value-Driven Memory Approach with Application to NPU Kernel Synthesis
Mar 11, 2026Deploying Large Language Models to data-scarce programming domains poses significant challenges, particularly for kernel synthesis on emerging Domain-Specific Architectures where a "Data Wall" limits available training data. While models excel on data-rich platforms like CUDA, they suffer catastrophic performance drops on data-scarce ecosystems such as NPU programming. To overcome this cold-start barrier without expensive fine-tuning, we introduce EvoKernel, a self-evolving agentic framework that automates the lifecycle of kernel synthesis from initial drafting to continual refining. EvoKernel addresses this by formulating the synthesis process as a memory-based reinforcement learning task. Through a novel value-driven retrieval mechanism, it learns stage-specific Q-values that prioritize experiences based on their contribution to the current objective, whether bootstrapping a feasible draft or iteratively refining latency. Furthermore, by enabling cross-task memory sharing, the agent generalizes insights from simple to complex operators. By building an NPU variant of KernelBench and evaluating on it, EvoKernel improves frontier models' correctness from 11.0% to 83.0% and achieves a median speedup of 3.60x over initial drafts through iterative refinement. This demonstrates that value-guided experience accumulation allows general-purpose models to master the kernel synthesis task on niche hardware ecosystems. Our official page is available at https://evokernel.zhuo.li.
ReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning
Mar 12, 2025Recent research on Reasoning of Large Language Models (LLMs) has sought to further enhance their performance by integrating meta-thinking -- enabling models to monitor, evaluate, and control their reasoning processes for more adaptive and effective problem-solving. However, current single-agent work lacks a specialized design for acquiring meta-thinking, resulting in low efficacy. To address this challenge, we introduce Reinforced Meta-thinking Agents (ReMA), a novel framework that leverages Multi-Agent Reinforcement Learning (MARL) to elicit meta-thinking behaviors, encouraging LLMs to think about thinking. ReMA decouples the reasoning process into two hierarchical agents: a high-level meta-thinking agent responsible for generating strategic oversight and plans, and a low-level reasoning agent for detailed executions. Through iterative reinforcement learning with aligned objectives, these agents explore and learn collaboration, leading to improved generalization and robustness. Experimental results demonstrate that ReMA outperforms single-agent RL baselines on complex reasoning tasks, including competitive-level mathematical benchmarks and LLM-as-a-Judge benchmarks. Comprehensive ablation studies further illustrate the evolving dynamics of each distinct agent, providing valuable insights into how the meta-thinking reasoning process enhances the reasoning capabilities of LLMs.
Boost, Disentangle, and Customize: A Robust System2-to-System1 Pipeline for Code Generation
Feb 18, 2025
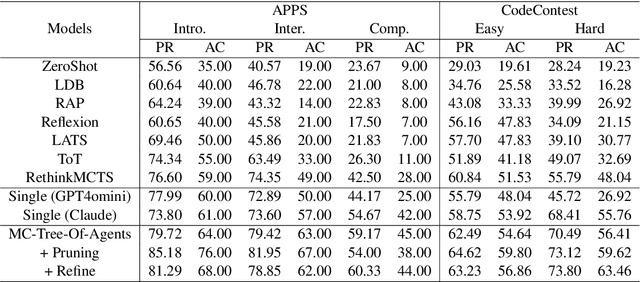
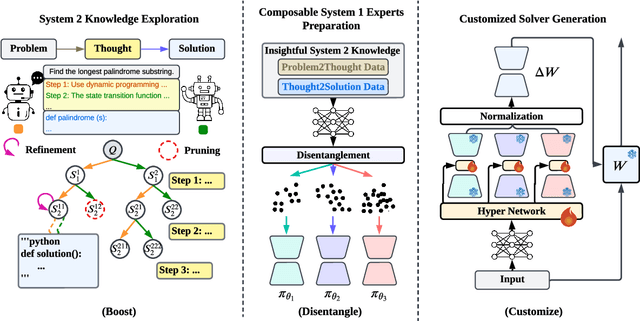
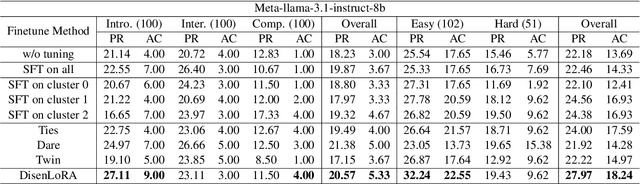
Large language models (LLMs) have demonstrated remarkable capabilities in various domains, particularly in system 1 tasks, yet the intricacies of their problem-solving mechanisms in system 2 tasks are not sufficiently explored. Recent research on System2-to-System1 methods surge, exploring the System 2 reasoning knowledge via inference-time computation and compressing the explored knowledge into System 1 process. In this paper, we focus on code generation, which is a representative System 2 task, and identify two primary challenges: (1) the complex hidden reasoning processes and (2) the heterogeneous data distributions that complicate the exploration and training of robust LLM solvers. To tackle these issues, we propose a novel BDC framework that explores insightful System 2 knowledge of LLMs using a MC-Tree-Of-Agents algorithm with mutual \textbf{B}oosting, \textbf{D}isentangles the heterogeneous training data for composable LoRA-experts, and obtain \textbf{C}ustomized problem solver for each data instance with an input-aware hypernetwork to weight over the LoRA-experts, offering effectiveness, flexibility, and robustness. This framework leverages multiple LLMs through mutual verification and boosting, integrated into a Monte-Carlo Tree Search process enhanced by reflection-based pruning and refinement. Additionally, we introduce the DisenLora algorithm, which clusters heterogeneous data to fine-tune LLMs into composable Lora experts, enabling the adaptive generation of customized problem solvers through an input-aware hypernetwork. This work lays the groundwork for advancing LLM capabilities in complex reasoning tasks, offering a novel System2-to-System1 solution.
Epistemic Uncertainty Quantification For Pre-trained Neural Network
Apr 15, 2024


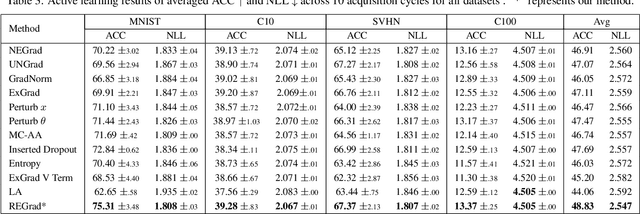
Epistemic uncertainty quantification (UQ) identifies where models lack knowledge. Traditional UQ methods, often based on Bayesian neural networks, are not suitable for pre-trained non-Bayesian models. Our study addresses quantifying epistemic uncertainty for any pre-trained model, which does not need the original training data or model modifications and can ensure broad applicability regardless of network architectures or training techniques. Specifically, we propose a gradient-based approach to assess epistemic uncertainty, analyzing the gradients of outputs relative to model parameters, and thereby indicating necessary model adjustments to accurately represent the inputs. We first explore theoretical guarantees of gradient-based methods for epistemic UQ, questioning the view that this uncertainty is only calculable through differences between multiple models. We further improve gradient-driven UQ by using class-specific weights for integrating gradients and emphasizing distinct contributions from neural network layers. Additionally, we enhance UQ accuracy by combining gradient and perturbation methods to refine the gradients. We evaluate our approach on out-of-distribution detection, uncertainty calibration, and active learning, demonstrating its superiority over current state-of-the-art UQ methods for pre-trained models.
GEAR: A GPU-Centric Experience Replay System for Large Reinforcement Learning Models
Oct 08, 2023
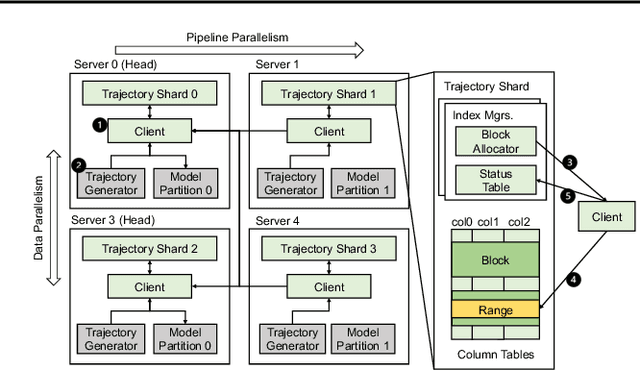


This paper introduces a distributed, GPU-centric experience replay system, GEAR, designed to perform scalable reinforcement learning (RL) with large sequence models (such as transformers). With such models, existing systems such as Reverb face considerable bottlenecks in memory, computation, and communication. GEAR, however, optimizes memory efficiency by enabling the memory resources on GPU servers (including host memory and device memory) to manage trajectory data. Furthermore, it facilitates decentralized GPU devices to expedite various trajectory selection strategies, circumventing computational bottlenecks. GEAR is equipped with GPU kernels capable of collecting trajectories using zero-copy access to host memory, along with remote-directed-memory access over InfiniBand, improving communication efficiency. Cluster experiments have shown that GEAR can achieve performance levels up to 6x greater than Reverb when training state-of-the-art large RL models. GEAR is open-sourced at https://github.com/bigrl-team/gear.
Body Knowledge and Uncertainty Modeling for Monocular 3D Human Body Reconstruction
Aug 01, 2023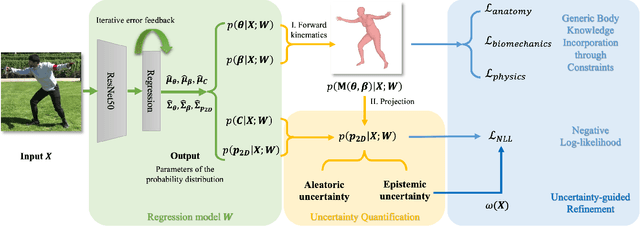



While 3D body reconstruction methods have made remarkable progress recently, it remains difficult to acquire the sufficiently accurate and numerous 3D supervisions required for training. In this paper, we propose \textbf{KNOWN}, a framework that effectively utilizes body \textbf{KNOW}ledge and u\textbf{N}certainty modeling to compensate for insufficient 3D supervisions. KNOWN exploits a comprehensive set of generic body constraints derived from well-established body knowledge. These generic constraints precisely and explicitly characterize the reconstruction plausibility and enable 3D reconstruction models to be trained without any 3D data. Moreover, existing methods typically use images from multiple datasets during training, which can result in data noise (\textit{e.g.}, inconsistent joint annotation) and data imbalance (\textit{e.g.}, minority images representing unusual poses or captured from challenging camera views). KNOWN solves these problems through a novel probabilistic framework that models both aleatoric and epistemic uncertainty. Aleatoric uncertainty is encoded in a robust Negative Log-Likelihood (NLL) training loss, while epistemic uncertainty is used to guide model refinement. Experiments demonstrate that KNOWN's body reconstruction outperforms prior weakly-supervised approaches, particularly on the challenging minority images.
Large Sequence Models for Sequential Decision-Making: A Survey
Jun 24, 2023Transformer architectures have facilitated the development of large-scale and general-purpose sequence models for prediction tasks in natural language processing and computer vision, e.g., GPT-3 and Swin Transformer. Although originally designed for prediction problems, it is natural to inquire about their suitability for sequential decision-making and reinforcement learning problems, which are typically beset by long-standing issues involving sample efficiency, credit assignment, and partial observability. In recent years, sequence models, especially the Transformer, have attracted increasing interest in the RL communities, spawning numerous approaches with notable effectiveness and generalizability. This survey presents a comprehensive overview of recent works aimed at solving sequential decision-making tasks with sequence models such as the Transformer, by discussing the connection between sequential decision-making and sequence modeling, and categorizing them based on the way they utilize the Transformer. Moreover, this paper puts forth various potential avenues for future research intending to improve the effectiveness of large sequence models for sequential decision-making, encompassing theoretical foundations, network architectures, algorithms, and efficient training systems. As this article has been accepted by the Frontiers of Computer Science, here is an early version, and the most up-to-date version can be found at https://journal.hep.com.cn/fcs/EN/10.1007/s11704-023-2689-5
Gradient-based Uncertainty Attribution for Explainable Bayesian Deep Learning
Apr 10, 2023
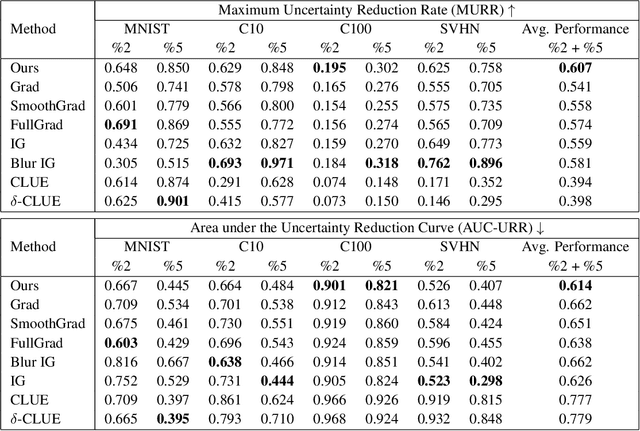


Predictions made by deep learning models are prone to data perturbations, adversarial attacks, and out-of-distribution inputs. To build a trusted AI system, it is therefore critical to accurately quantify the prediction uncertainties. While current efforts focus on improving uncertainty quantification accuracy and efficiency, there is a need to identify uncertainty sources and take actions to mitigate their effects on predictions. Therefore, we propose to develop explainable and actionable Bayesian deep learning methods to not only perform accurate uncertainty quantification but also explain the uncertainties, identify their sources, and propose strategies to mitigate the uncertainty impacts. Specifically, we introduce a gradient-based uncertainty attribution method to identify the most problematic regions of the input that contribute to the prediction uncertainty. Compared to existing methods, the proposed UA-Backprop has competitive accuracy, relaxed assumptions, and high efficiency. Moreover, we propose an uncertainty mitigation strategy that leverages the attribution results as attention to further improve the model performance. Both qualitative and quantitative evaluations are conducted to demonstrate the effectiveness of our proposed methods.
MALib: A Parallel Framework for Population-based Multi-agent Reinforcement Learning
Jun 05, 2021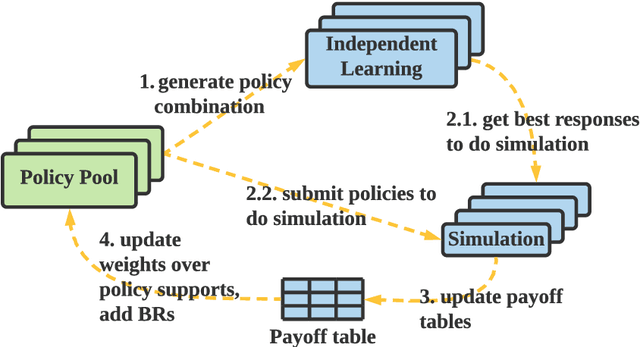

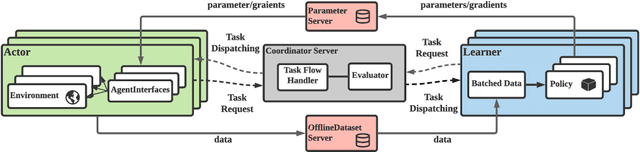

Population-based multi-agent reinforcement learning (PB-MARL) refers to the series of methods nested with reinforcement learning (RL) algorithms, which produces a self-generated sequence of tasks arising from the coupled population dynamics. By leveraging auto-curricula to induce a population of distinct emergent strategies, PB-MARL has achieved impressive success in tackling multi-agent tasks. Despite remarkable prior arts of distributed RL frameworks, PB-MARL poses new challenges for parallelizing the training frameworks due to the additional complexity of multiple nested workloads between sampling, training and evaluation involved with heterogeneous policy interactions. To solve these problems, we present MALib, a scalable and efficient computing framework for PB-MARL. Our framework is comprised of three key components: (1) a centralized task dispatching model, which supports the self-generated tasks and scalable training with heterogeneous policy combinations; (2) a programming architecture named Actor-Evaluator-Learner, which achieves high parallelism for both training and sampling, and meets the evaluation requirement of auto-curriculum learning; (3) a higher-level abstraction of MARL training paradigms, which enables efficient code reuse and flexible deployments on different distributed computing paradigms. Experiments on a series of complex tasks such as multi-agent Atari Games show that MALib achieves throughput higher than 40K FPS on a single machine with $32$ CPU cores; 5x speedup than RLlib and at least 3x speedup than OpenSpiel in multi-agent training tasks. MALib is publicly available at https://github.com/sjtu-marl/malib.