 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALib: A Parallel Framework for Population-based Multi-agent Reinforcement Learning
Paper and Code
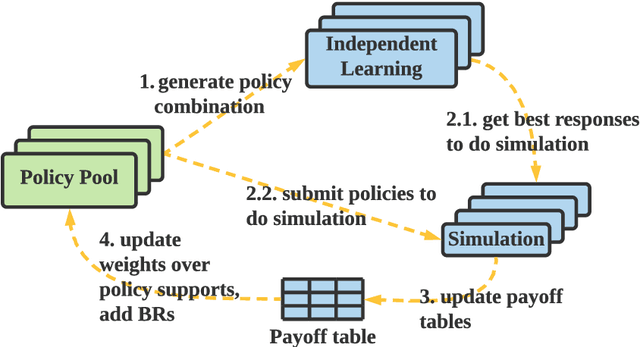

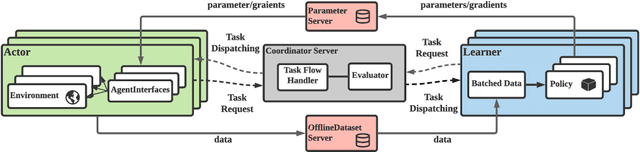

Population-based multi-agent reinforcement learning (PB-MARL) refers to the series of methods nested with reinforcement learning (RL) algorithms, which produces a self-generated sequence of tasks arising from the coupled population dynamics. By leveraging auto-curricula to induce a population of distinct emergent strategies, PB-MARL has achieved impressive success in tackling multi-agent tasks. Despite remarkable prior arts of distributed RL frameworks, PB-MARL poses new challenges for parallelizing the training frameworks due to the additional complexity of multiple nested workloads between sampling, training and evaluation involved with heterogeneous policy interactions. To solve these problems, we present MALib, a scalable and efficient computing framework for PB-MARL. Our framework is comprised of three key components: (1) a centralized task dispatching model, which supports the self-generated tasks and scalable training with heterogeneous policy combinations; (2) a programming architecture named Actor-Evaluator-Learner, which achieves high parallelism for both training and sampling, and meets the evaluation requirement of auto-curriculum learning; (3) a higher-level abstraction of MARL training paradigms, which enables efficient code reuse and flexible deployments on different distributed computing paradigms. Experiments on a series of complex tasks such as multi-agent Atari Games show that MALib achieves throughput higher than 40K FPS on a single machine with $32$ CPU cores; 5x speedup than RLlib and at least 3x speedup than OpenSpiel in multi-agent training tasks. MALib is publicly available at https://github.com/sjtu-marl/malib.