 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Fuse or to Drop? Dual-Path Learning for Resolving Modality Conflicts in Multimodal Emotion Recognition
May 06, 2026Multimodal emotion recognition (MER) benefits from combining text, audio, and vision, yet standard fusion often fails when modalities conflict. Crucially, conflicts differ in resolvability: benign conflicts stem from missing, weak, or ambiguous cues and can be mitigated by cross-modal calibration, while severe conflicts arise from intrinsically contradictory (e.g., sarcasm) or misleading signals, for which forced fusion may amplify errors. Recognizing this, we propose Dual-Path Conflict Resolution (DCR), a unified framework that learns when to fuse and when to drop modalities. Path I (Affective Fusion Distiller, AFD) performs reverse distillation from audio/visual teachers to a textual student using temporally weighted class evidence, thereby enhancing representation-level calibration and improving fusion when alignment is beneficial. Path II (Affective Discernment Agent, ADA) formulates MER as a contextual bandit that selects among fusion and unimodal predictions based on a dual-view state and a calibration-aware reward, enabling decision-level arbitration under irreconcilable conflicts without requiring per-modality reliability labels. By taking into account the full multimodal context and coupling soft calibration with hard arbitration, DCR reconciles conflicts that can be aligned while bypassing misleading modalities when fusion is harmful. Across five benchmarks covering both dialogue-level and clip-level MER, DCR consistently outperforms competitive baselines or achieves highly competitive results. Further ablations, conflict-specific subset evaluation, and modality-selection analysis verify that AFD and ADA are complementary and jointly improve robust conflict-aware emotion recognition.
WebUncertainty: Dual-Level Uncertainty Driven Planning and Reasoning For Autonomous Web Agent
Apr 21, 2026Recent advancements in large language models (LLMs) have empowered autonomous web agents to execute natural language instructions directly on real-world webpages. However, existing agents often struggle with complex tasks involving dynamic interactions and long-horizon execution due to rigid planning strategies and hallucination-prone reasoning. To address these limitations, we propose WebUncertainty, a novel autonomous agent framework designed to tackle dual-level uncertainty in planning and reasoning. Specifically, we design a Task Uncertainty-Driven Adaptive Planning Mechanism that adaptively selects planning modes to navigate unknown environments. Furthermore, we introduce an Action Uncertainty-Driven Monte Carlo tree search (MCTS) Reasoning Mechanism. This mechanism incorporates the Confidence-induced Action Uncertainty (ConActU) strategy to quantify both aleatoric uncertainty (AU) and epistemic uncertainty (EU), thereby optimizing the search process and guiding robust decision-making. Experimental results on the WebArena and WebVoyager benchmarks demonstrate that WebUncertainty achieves superior performance compared to state-of-the-art baselines.
Tears or Cheers? Benchmarking LLMs via Culturally Elicited Distinct Affective Responses
Jan 19, 2026Culture serves as a fundamental determinant of human affective processing and profoundly shapes how individuals perceive and interpret emotional stimuli. Despite this intrinsic link extant evaluations regarding cultural alignment within Large Language Models primarily prioritize declarative knowledge such as geographical facts or established societal customs. These benchmarks remain insufficient to capture the subjective interpretative variance inherent to diverse sociocultural lenses. To address this limitation, we introduce CEDAR, a multimodal benchmark constructed entirely from scenarios capturing Culturally \underline{\textsc{E}}licited \underline{\textsc{D}}istinct \underline{\textsc{A}}ffective \underline{\textsc{R}}esponses. To construct CEDAR, we implement a novel pipeline that leverages LLM-generated provisional labels to isolate instances yielding cross-cultural emotional distinctions, and subsequently derives reliable ground-truth annotations through rigorous human evaluation. The resulting benchmark comprises 10,962 instances across seven languages and 14 fine-grained emotion categories, with each language including 400 multimodal and 1,166 text-only samples. Comprehensive evaluations of 17 representative multilingual models reveal a dissociation between language consistency and cultural alignment, demonstrating that culturally grounded affective understanding remains a significant challenge for current models.
PsychEthicsBench: Evaluating Large Language Models Against Australian Mental Health Ethics
Jan 07, 2026The increasing integration of large language models (LLMs) into mental health applications necessitates robust frameworks for evaluating professional safety alignment. Current evaluative approaches primarily rely on refusal-based safety signals, which offer limited insight into the nuanced behaviors required in clinical practice. In mental health, clinically inadequate refusals can be perceived as unempathetic and discourage help-seeking. To address this gap, we move beyond refusal-centric metrics and introduce \texttt{PsychEthicsBench}, the first principle-grounded benchmark based on Australian psychology and psychiatry guidelines, designed to evaluate LLMs' ethical knowledge and behavioral responses through multiple-choice and open-ended tasks with fine-grained ethicality annotations. Empirical results across 14 models reveal that refusal rates are poor indicators of ethical behavior, revealing a significant divergence between safety triggers and clinical appropriateness. Notably, we find that domain-specific fine-tuning can degrade ethical robustness, as several specialized models underperform their base backbones in ethical alignment. PsychEthicsBench provides a foundation for systematic, jurisdiction-aware evaluation of LLMs in mental health, encouraging more responsible development in this domain.
MentraSuite: Post-Training Large Language Models for Mental Health Reasoning and Assessment
Dec 16, 2025Mental health disorders affect hundreds of millions globally, and the Web now serves as a primary medium for accessing support, information, and assessment. Large language models (LLMs) offer scalable and accessible assistance, yet their deployment in mental-health settings remains risky when their reasoning is incomplete, inconsistent, or ungrounded. Existing psychological LLMs emphasize emotional understanding or knowledge recall but overlook the step-wise, clinically aligned reasoning required for appraisal, diagnosis, intervention planning, abstraction, and verification. To address these issues, we introduce MentraSuite, a unified framework for advancing reliable mental-health reasoning. We propose MentraBench, a comprehensive benchmark spanning five core reasoning aspects, six tasks, and 13 datasets, evaluating both task performance and reasoning quality across five dimensions: conciseness, coherence, hallucination avoidance, task understanding, and internal consistency. We further present Mindora, a post-trained model optimized through a hybrid SFT-RL framework with an inconsistency-detection reward to enforce faithful and coherent reasoning. To support training, we construct high-quality trajectories using a novel reasoning trajectory generation strategy, that strategically filters difficult samples and applies a structured, consistency-oriented rewriting process to produce concise, readable, and well-balanced trajectories. Across 20 evaluated LLMs, Mindora achieves the highest average performance on MentraBench and shows remarkable performances in reasoning reliability, demonstrating its effectiveness for complex mental-health scenarios.
Beyond Emotion Recognition: A Multi-Turn Multimodal Emotion Understanding and Reasoning Benchmark
Aug 23, 2025Multimodal large language models (MLLMs) have been widely applied across various fields due to their powerful perceptual and reasoning capabilities. In the realm of psychology, these models hold promise for a deeper understanding of human emotions and behaviors. However, recent research primarily focuses on enhancing their emotion recognition abilities, leaving the substantial potential in emotion reasoning, which is crucial for improving the naturalness and effectiveness of human-machine interactions. Therefore, in this paper, we introduce a multi-turn multimodal emotion understanding and reasoning (MTMEUR) benchmark, which encompasses 1,451 video data from real-life scenarios, along with 5,101 progressive questions. These questions cover various aspects, including emotion recognition, potential causes of emotions, future action prediction, etc. Besides, we propose a multi-agent framework, where each agent specializes in a specific aspect, such as background context, character dynamics, and event details, to improve the system's reasoning capabilities. Furthermore, we conduct experiments with existing MLLMs and our agent-based method on the proposed benchmark, revealing that most models face significant challenges with this task.
Add-One-In: Incremental Sample Selection for Large Language Models via a Choice-Based Greedy Paradigm
Mar 04, 2025Selecting high-quality and diverse training samples from extensive datasets plays a crucial role in reducing training overhead and enhancing the performance of Large Language Models (LLMs). However, existing studies fall short in assessing the overall value of selected data, focusing primarily on individual quality, and struggle to strike an effective balance between ensuring diversity and minimizing data point traversals. Therefore, this paper introduces a novel choice-based sample selection framework that shifts the focus from evaluating individual sample quality to comparing the contribution value of different samples when incorporated into the subset. Thanks to the advanced language understanding capabilities of LLMs, we utilize LLMs to evaluate the value of each option during the selection process. Furthermore, we design a greedy sampling process where samples are incrementally added to the subset, thereby improving efficiency by eliminating the need for exhaustive traversal of the entire dataset with the limited budget. Extensive experiments demonstrate that selected data from our method not only surpass the performance of the full dataset but also achieves competitive results with state-of-the-art (SOTA) studies, while requiring fewer selections. Moreover, we validate our approach on a larger medical dataset, highlighting its practical applicability in real-world applications.
Self-Instructed Derived Prompt Generation Meets In-Context Learning: Unlocking New Potential of Black-Box LLMs
Sep 03, 2024
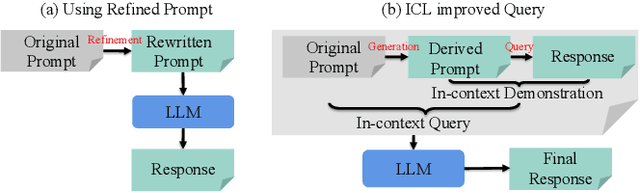
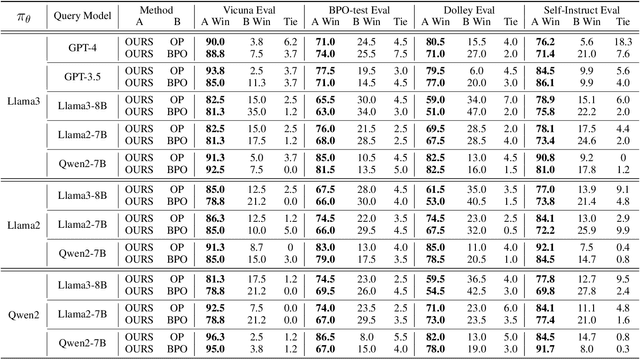
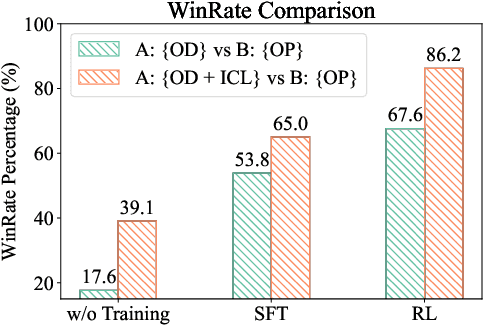
Large language models (LLMs) have shown success in generating high-quality responses. In order to achieve better alignment with LLMs with human preference, various works are proposed based on specific optimization process, which, however, is not suitable to Black-Box LLMs like GPT-4, due to inaccessible parameters. In Black-Box LLMs case, their performance is highly dependent on the quality of the provided prompts. Existing methods to enhance response quality often involve a prompt refinement model, yet these approaches potentially suffer from semantic inconsistencies between the refined and original prompts, and typically overlook the relationship between them. To address these challenges, we introduce a self-instructed in-context learning framework that empowers LLMs to deliver more effective responses by generating reliable derived prompts to construct informative contextual environments. Our approach incorporates a self-instructed reinforcement learning mechanism, enabling direct interaction with the response model during derived prompt generation for better alignment. We then formulate querying as an in-context learning task, using responses from LLMs combined with the derived prompts to establish a contextual demonstration for the original prompt. This strategy ensures alignment with the original query, reduces discrepancies from refined prompts, and maximizes the LLMs' in-context learning capability. Extensive experiments demonstrate that the proposed method not only generates more reliable derived prompts but also significantly enhances LLMs' ability to deliver more effective responses, including Black-Box models such as GPT-4.
PsycoLLM: Enhancing LLM for Psychological Understanding and Evaluation
Jul 08, 2024



Mental health has attracted substantial attention in recent years and LLM can be an effective technology for alleviating this problem owing to its capability in text understanding and dialogue. However, existing research in this domain often suffers from limitations, such as training on datasets lacking crucial prior knowledge and evidence, and the absence of comprehensive evaluation methods. In this paper, we propose a specialized psychological large language model (LLM), named PsycoLLM, trained on a proposed high-quality psychological dataset, including single-turn QA, multi-turn dialogues enriched with prior knowledge and knowledge-based QA. Additionally, to compare the performance of PsycoLLM with other LLMs, we develop a comprehensive psychological benchmark based on authoritative psychological counseling examinations in China, which includes assessments of professional ethics, theoretical proficiency, and case analysis. The experimental results on the benchmark illustrates the effectiveness of PsycoLLM, which demonstrates superior performance compared to other LLMs.
Is ChatGPT a Highly Fluent Grammatical Error Correction System? A Comprehensive Evaluation
Apr 04, 2023ChatGPT, a large-scale language model based on the advanced GPT-3.5 architecture, has shown remarkable potential in various Natural Language Processing (NLP) tasks. However, there is currently a dearth of comprehensive study exploring its potential in the area of Grammatical Error Correction (GEC). To showcase its capabilities in GEC, we design zero-shot chain-of-thought (CoT) and few-shot CoT settings using in-context learning for ChatGPT. Our evaluation involves assessing ChatGPT's performance on five official test sets in three different languages, along with three document-level GEC test sets in English. Our experimental results and human evaluations demonstrate that ChatGPT has excellent error detection capabilities and can freely correct errors to make the corrected sentences very fluent, possibly due to its over-correction tendencies and not adhering to the principle of minimal edits. Additionally, its performance in non-English and low-resource settings highlights its potential in multilingual GEC tasks. However, further analysis of various types of errors at the document-level has shown that ChatGPT cannot effectively correct agreement, coreference, tense errors across sentences, and cross-sentence boundary errors.