 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Sight: Enhancing LLM-Based Agents via Conflict-Aware Meta-Verification and Trustworthy Reasoning with Structured Facts
Oct 24, 2025Long-horizon reasoning in LLM-based agents often fails not from generative weakness but from insufficient verification of intermediate reasoning. Co-Sight addresses this challenge by turning reasoning into a falsifiable and auditable process through two complementary mechanisms: Conflict-Aware Meta-Verification (CAMV) and Trustworthy Reasoning with Structured Facts (TRSF). CAMV reformulates verification as conflict identification and targeted falsification, allocating computation only to disagreement hotspots among expert agents rather than to full reasoning chains. This bounds verification cost to the number of inconsistencies and improves efficiency and reliability. TRSF continuously organizes, validates, and synchronizes evidence across agents through a structured facts module. By maintaining verified, traceable, and auditable knowledge, it ensures that all reasoning is grounded in consistent, source-verified information and supports transparent verification throughout the reasoning process. Together, TRSF and CAMV form a closed verification loop, where TRSF supplies structured facts and CAMV selectively falsifies or reinforces them, yielding transparent and trustworthy reasoning. Empirically, Co-Sight achieves state-of-the-art accuracy on GAIA (84.4%) and Humanity's Last Exam (35.5%), and strong results on Chinese-SimpleQA (93.8%). Ablation studies confirm that the synergy between structured factual grounding and conflict-aware verification drives these improvements. Co-Sight thus offers a scalable paradigm for reliable long-horizon reasoning in LLM-based agents. Code is available at https://github.com/ZTE-AICloud/Co-Sight/tree/cosight2.0_benchmarks.
Exploiting Ensemble Learning for Cross-View Isolated Sign Language Recognition
Feb 04, 2025



In this paper, we present our solution to the Cross-View Isolated Sign Language Recognition (CV-ISLR) challenge held at WWW 2025. CV-ISLR addresses a critical issue in traditional Isolated Sign Language Recognition (ISLR), where existing datasets predominantly capture sign language videos from a frontal perspective, while real-world camera angles often vary. To accurately recognize sign language from different viewpoints, models must be capable of understanding gestures from multiple angles, making cross-view recognition challenging. To address this, we explore the advantages of ensemble learning, which enhances model robustness and generalization across diverse views. Our approach, built on a multi-dimensional Video Swin Transformer model, leverages this ensemble strategy to achieve competitive performance. Finally, our solution ranked 3rd in both the RGB-based ISLR and RGB-D-based ISLR tracks, demonstrating the effectiveness in handling the challenges of cross-view recognition. The code is available at: https://github.com/Jiafei127/CV_ISLR_WWW2025.
PsycoLLM: Enhancing LLM for Psychological Understanding and Evaluation
Jul 08, 2024



Mental health has attracted substantial attention in recent years and LLM can be an effective technology for alleviating this problem owing to its capability in text understanding and dialogue. However, existing research in this domain often suffers from limitations, such as training on datasets lacking crucial prior knowledge and evidence, and the absence of comprehensive evaluation methods. In this paper, we propose a specialized psychological large language model (LLM), named PsycoLLM, trained on a proposed high-quality psychological dataset, including single-turn QA, multi-turn dialogues enriched with prior knowledge and knowledge-based QA. Additionally, to compare the performance of PsycoLLM with other LLMs, we develop a comprehensive psychological benchmark based on authoritative psychological counseling examinations in China, which includes assessments of professional ethics, theoretical proficiency, and case analysis. The experimental results on the benchmark illustrates the effectiveness of PsycoLLM, which demonstrates superior performance compared to other LLMs.
Spatial-temporal Transformer for Affective Behavior Analysis
Mar 19, 2023The in-the-wild affective behavior analysis has been an important study. In this paper, we submit our solutions for the 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW), which includes V-A Estimation, Facial Expression Classification and AU Detection Sub-challenges. We propose a Transformer Encoder with Multi-Head Attention framework to learn the distribution of both the spatial and temporal features. Besides, there are virious effective data augmentation strategies employed to alleviate the problems of sample imbalance during model training. The results fully demonstrate the effectiveness of our proposed model based on the Aff-Wild2 dataset.
Hybrid Multimodal Feature Extraction, Mining and Fusion for Sentiment Analysis
Aug 12, 2022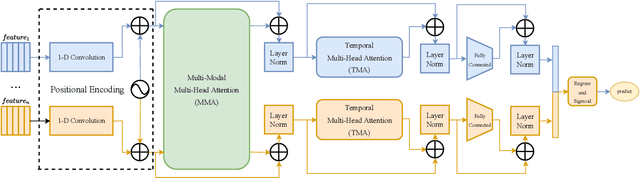
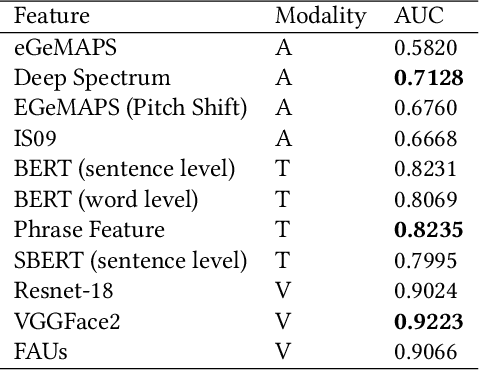
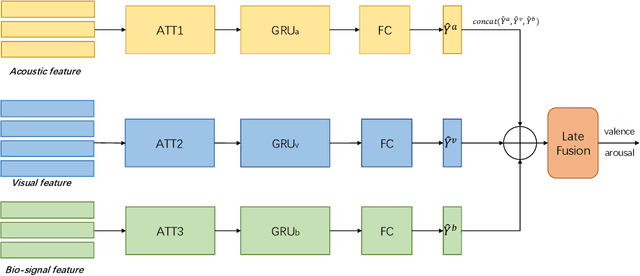
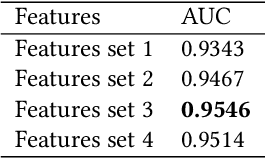
In this paper, we present our solutions for the Multimodal Sentiment Analysis Challenge (MuSe) 2022, which includes MuSe-Humor, MuSe-Reaction and MuSe-Stress Sub-challenges. The MuSe 2022 focuses on humor detection, emotional reactions and multimodal emotional stress utilizing different modalities and data sets. In our work, different kinds of multimodal features are extracted, including acoustic, visual, text and biological features. These features are fused by TEMMA and GRU with self-attention mechanism frameworks. In this paper, 1) several new audio features, facial expression features and paragraph-level text embeddings are extracted for accuracy improvement. 2) we substantially improve the accuracy and reliability of multimodal sentiment prediction by mining and blending the multimodal features. 3) effective data augmentation strategies are applied in model training to alleviate the problem of sample imbalance and prevent the model from learning biased subject characters. For the MuSe-Humor sub-challenge, our model obtains the AUC score of 0.8932. For the MuSe-Reaction sub-challenge, the Pearson's Correlations Coefficient of our approach on the test set is 0.3879, which outperforms all other participants. For the MuSe-Stress sub-challenge, our approach outperforms the baseline in both arousal and valence on the test dataset, reaching a final combined result of 0.5151.