 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASM: Adaptive Sample Mining for In-The-Wild Facial Expression Recognition
Oct 09, 2023Given the similarity between facial expression categories, the presence of compound facial expressions, and the subjectivity of annotators, facial expression recognition (FER) datasets often suffer from ambiguity and noisy labels. Ambiguous expressions are challenging to differentiate from expressions with noisy labels, which hurt the robustness of FER models. Furthermore, the difficulty of recognition varies across different expression categories, rendering a uniform approach unfair for all expressions. In this paper, we introduce a novel approach called Adaptive Sample Mining (ASM) to dynamically address ambiguity and noise within each expression category. First, the Adaptive Threshold Learning module generates two thresholds, namely the clean and noisy thresholds, for each category. These thresholds are based on the mean class probabilities at each training epoch. Next, the Sample Mining module partitions the dataset into three subsets: clean, ambiguity, and noise, by comparing the sample confidence with the clean and noisy thresholds. Finally, the Tri-Regularization module employs a mutual learning strategy for the ambiguity subset to enhance discrimination ability, and an unsupervised learning strategy for the noise subset to mitigate the impact of noisy labels. Extensive experiments prove that our method can effectively mine both ambiguity and noise, and outperform SOTA methods on both synthetic noisy and original datasets. The supplement material is available at https://github.com/zzzzzzyang/ASM.
Facial Affect Recognition based on Transformer Encoder and Audiovisual Fusion for the ABAW5 Challenge
Mar 20, 2023In this paper, we present our solutions for the 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW), which includes four sub-challenges of Valence-Arousal (VA) Estimation, Expression (Expr) Classification, Action Unit (AU) Detection and Emotional Reaction Intensity (ERI) Estimation. The 5th ABAW competition focuses on facial affect recognition utilizing different modalities and datasets. In our work, we extract powerful audio and visual features using a large number of sota models. These features are fused by Transformer Encoder and TEMMA. Besides, to avoid the possible impact of large dimensional differences between various features, we design an Affine Module to align different features to the same dimension. Extensive experiments demonstrate that the superiority of the proposed method. For the VA Estimation sub-challenge, our method obtains the mean Concordance Correlation Coefficient (CCC) of 0.6066. For the Expression Classification sub-challenge, the average F1 Score is 0.4055. For the AU Detection sub-challenge, the average F1 Score is 0.5296. For the Emotional Reaction Intensity Estimation sub-challenge, the average pearson's correlations coefficient on the validation set is 0.3968. All of the results of four sub-challenges outperform the baseline with a large margin.
Hybrid Multimodal Feature Extraction, Mining and Fusion for Sentiment Analysis
Aug 12, 2022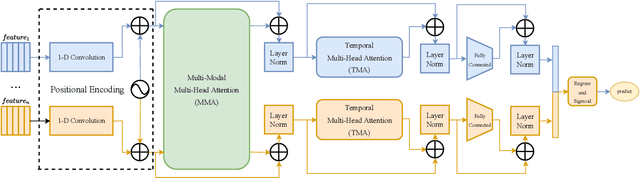
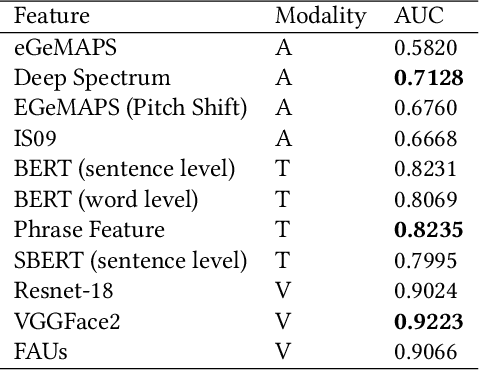
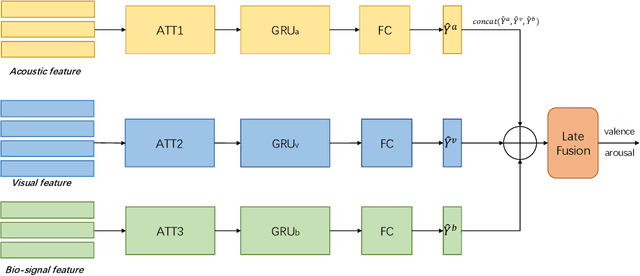
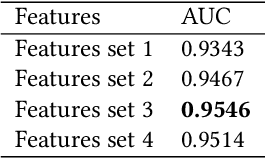
In this paper, we present our solutions for the Multimodal Sentiment Analysis Challenge (MuSe) 2022, which includes MuSe-Humor, MuSe-Reaction and MuSe-Stress Sub-challenges. The MuSe 2022 focuses on humor detection, emotional reactions and multimodal emotional stress utilizing different modalities and data sets. In our work, different kinds of multimodal features are extracted, including acoustic, visual, text and biological features. These features are fused by TEMMA and GRU with self-attention mechanism frameworks. In this paper, 1) several new audio features, facial expression features and paragraph-level text embeddings are extracted for accuracy improvement. 2) we substantially improve the accuracy and reliability of multimodal sentiment prediction by mining and blending the multimodal features. 3) effective data augmentation strategies are applied in model training to alleviate the problem of sample imbalance and prevent the model from learning biased subject characters. For the MuSe-Humor sub-challenge, our model obtains the AUC score of 0.8932. For the MuSe-Reaction sub-challenge, the Pearson's Correlations Coefficient of our approach on the test set is 0.3879, which outperforms all other participants. For the MuSe-Stress sub-challenge, our approach outperforms the baseline in both arousal and valence on the test dataset, reaching a final combined result of 0.5151.