 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-resolution imaging using super-oscillatory diffractive neural networks
Jun 27, 2024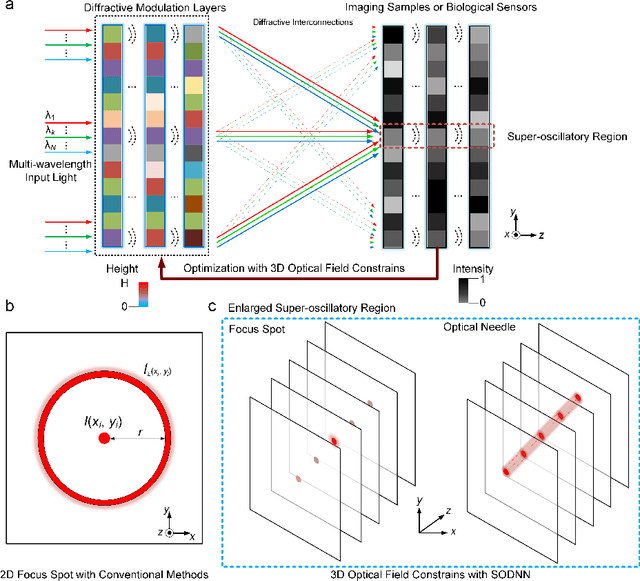
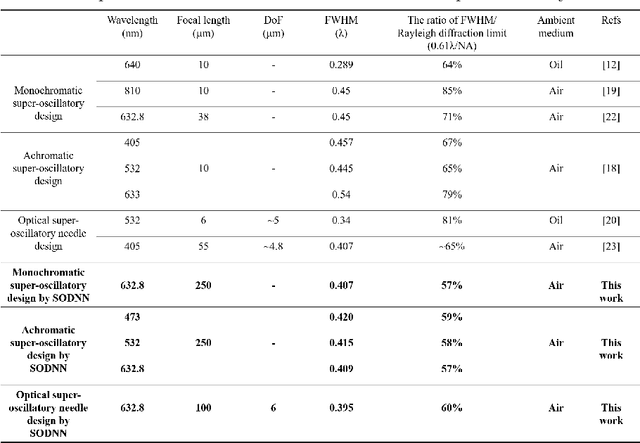
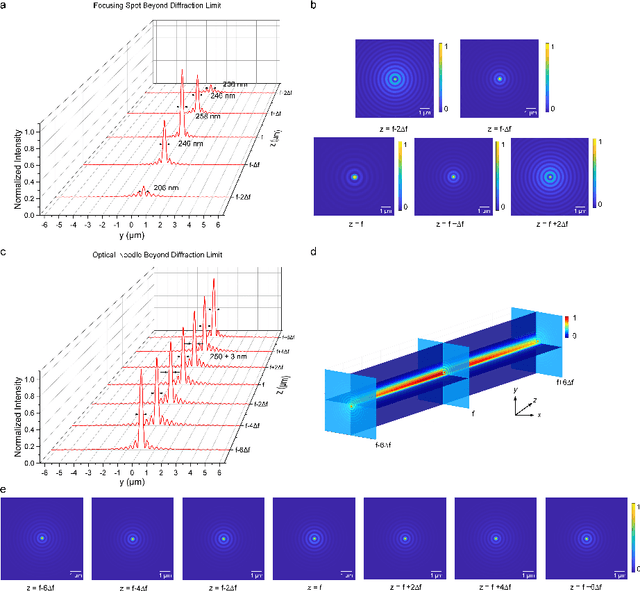
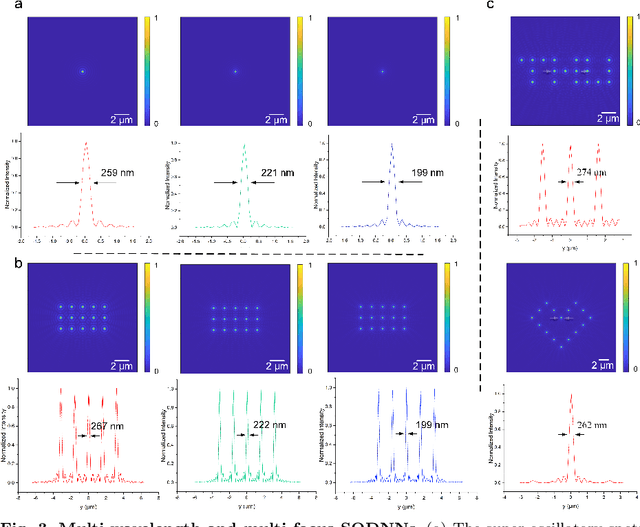
Optical super-oscillation enables far-field super-resolution imaging beyond diffraction limits. However, the existing super-oscillatory lens for the spatial super-resolution imaging system still confronts critical limitations in performance due to the lack of a more advanced design method and the limited design degree of freedom. Here, we propose an optical super-oscillatory diffractive neural network, i.e., SODNN, that can achieve super-resolved spatial resolution for imaging beyond the diffraction limit with superior performance over existing methods. SODNN is constructed by utilizing diffractive layers to implement optical interconnections and imaging samples or biological sensors to implement nonlinearity, which modulates the incident optical field to create optical super-oscillation effects in 3D space and generate the super-resolved focal spots. By optimizing diffractive layers with 3D optical field constraints under an incident wavelength size of $\lambda$, we achieved a super-oscillatory spot with a full width at half maximum of 0.407$\lambda$ in the far field distance over 400$\lambda$ without side-lobes over the field of view, having a long depth of field over 10$\lambda$. Furthermore, the SODNN implements a multi-wavelength and multi-focus spot array that effectively avoids chromatic aberrations. Our research work will inspire the development of intelligent optical instruments to facilitate the applications of imaging, sensing, perception, etc.
Revolutionizing Forensic Toolmark Analysis: An Objective and Transparent Comparison Algorithm
Nov 19, 2023



Forensic toolmark comparisons are currently performed subjectively by humans, which leads to a lack of consistency and accuracy. There is little evidence that examiners can determine whether pairs of marks were made by the same tool or different tools. There is also little evidence that they can make this classification when marks are made under different conditions, such as different angles of attack or direction of mark generation. We generate original toolmark data in 3D, extract the signal from each toolmarks, and train an algorithm to compare toolmark signals objectively. We find that toolmark signals cluster by tool, and not by angle or direction. That is, the variability within tool, regardless of angle/direction, is smaller than the variability between tools. The known-match and known-non-match densities of the similarities of pairs of marks have a small overlap, even when accounting for dependencies in the data, making them a useful instrument for determining whether a new pair of marks was made by the same tool. We provide a likelihood ratio approach as a formal method for comparing toolmark signals with a measure of uncertainty. This empirically trained, open-source method can be used by forensic examiners to compare toolmarks objectively and thus improve the reliability of toolmark comparisons. This can, in turn, reduce miscarriages of justice in the criminal justice system.
DP-HyPO: An Adaptive Private Hyperparameter Optimization Framework
Jun 09, 2023Hyperparameter optimization, also known as hyperparameter tuning, is a widely recognized technique for improving model performance. Regrettably, when training private ML models, many practitioners often overlook the privacy risks associated with hyperparameter optimization, which could potentially expose sensitive information about the underlying dataset. Currently, the sole existing approach to allow privacy-preserving hyperparameter optimization is to uniformly and randomly select hyperparameters for a number of runs, subsequently reporting the best-performing hyperparameter. In contrast, in non-private settings, practitioners commonly utilize "adaptive" hyperparameter optimization methods such as Gaussian process-based optimization, which select the next candidate based on information gathered from previous outputs. This substantial contrast between private and non-private hyperparameter optimization underscores a critical concern. In our paper, we introduce DP-HyPO, a pioneering framework for "adaptive" private hyperparameter optimization, aiming to bridge the gap between private and non-private hyperparameter optimization. To accomplish this, we provide a comprehensive differential privacy analysis of our framework. Furthermore, we empirically demonstrate the effectiveness of DP-HyPO on a diverse set of real-world and synthetic datasets.
Dual adaptive training of photonic neural networks
Dec 09, 2022Photonic neural network (PNN) is a remarkable analog artificial intelligence (AI) accelerator that computes with photons instead of electrons to feature low latency, high energy efficiency, and high parallelism. However, the existing training approaches cannot address the extensive accumulation of systematic errors in large-scale PNNs, resulting in a significant decrease in model performance in physical systems. Here, we propose dual adaptive training (DAT) that allows the PNN model to adapt to substantial systematic errors and preserves its performance during the deployment. By introducing the systematic error prediction networks with task-similarity joint optimization, DAT achieves the high similarity mapping between the PNN numerical models and physical systems and high-accurate gradient calculations during the dual backpropagation training. We validated the effectiveness of DAT by using diffractive PNNs and interference-based PNNs on image classification tasks. DAT successfully trained large-scale PNNs under major systematic errors and preserved the model classification accuracies comparable to error-free systems. The results further demonstrated its superior performance over the state-of-the-art in situ training approaches. DAT provides critical support for constructing large-scale PNNs to achieve advanced architectures and can be generalized to other types of AI systems with analog computing errors.
Hybrid Multimodal Feature Extraction, Mining and Fusion for Sentiment Analysis
Aug 12, 2022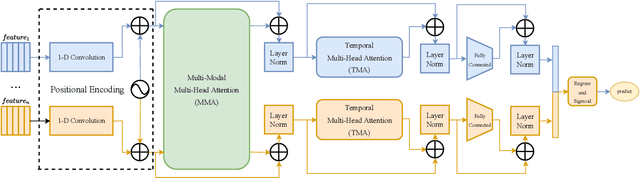
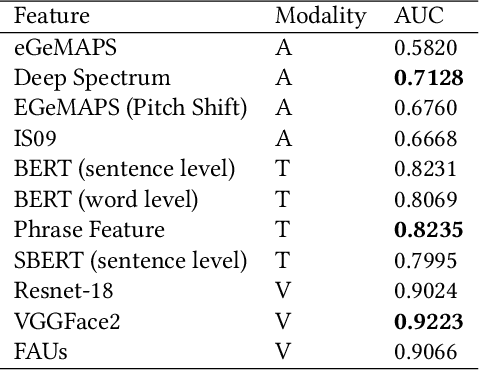
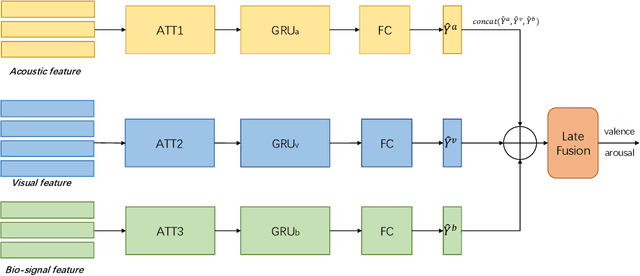
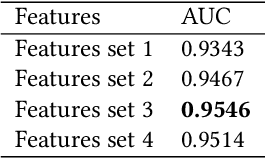
In this paper, we present our solutions for the Multimodal Sentiment Analysis Challenge (MuSe) 2022, which includes MuSe-Humor, MuSe-Reaction and MuSe-Stress Sub-challenges. The MuSe 2022 focuses on humor detection, emotional reactions and multimodal emotional stress utilizing different modalities and data sets. In our work, different kinds of multimodal features are extracted, including acoustic, visual, text and biological features. These features are fused by TEMMA and GRU with self-attention mechanism frameworks. In this paper, 1) several new audio features, facial expression features and paragraph-level text embeddings are extracted for accuracy improvement. 2) we substantially improve the accuracy and reliability of multimodal sentiment prediction by mining and blending the multimodal features. 3) effective data augmentation strategies are applied in model training to alleviate the problem of sample imbalance and prevent the model from learning biased subject characters. For the MuSe-Humor sub-challenge, our model obtains the AUC score of 0.8932. For the MuSe-Reaction sub-challenge, the Pearson's Correlations Coefficient of our approach on the test set is 0.3879, which outperforms all other participants. For the MuSe-Stress sub-challenge, our approach outperforms the baseline in both arousal and valence on the test dataset, reaching a final combined result of 0.5151.
Analytical Composition of Differential Privacy via the Edgeworth Accountant
Jun 09, 2022

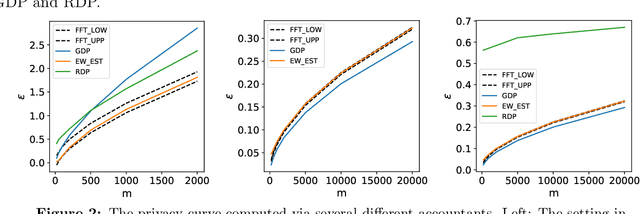

Many modern machine learning algorithms are composed of simple private algorithms; thus, an increasingly important problem is to efficiently compute the overall privacy loss under composition. In this study, we introduce the Edgeworth Accountant, an analytical approach to composing differential privacy guarantees of private algorithms. The Edgeworth Accountant starts by losslessly tracking the privacy loss under composition using the $f$-differential privacy framework, which allows us to express the privacy guarantees using privacy-loss log-likelihood ratios (PLLRs). As the name suggests, this accountant next uses the Edgeworth expansion to the upper and lower bounds the probability distribution of the sum of the PLLRs. Moreover, by relying on a technique for approximating complex distributions using simple ones, we demonstrate that the Edgeworth Accountant can be applied to the composition of any noise-addition mechanism. Owing to certain appealing features of the Edgeworth expansion, the $(\epsilon, \delta)$-differential privacy bounds offered by this accountant are non-asymptotic, with essentially no extra computational cost, as opposed to the prior approaches in, wherein the running times increase with the number of compositions. Finally, we demonstrate that our upper and lower $(\epsilon, \delta)$-differential privacy bounds are tight in federated analytics and certain regimes of training private deep learning models.
Sparse GCA and Thresholded Gradient Descent
Jul 01, 2021
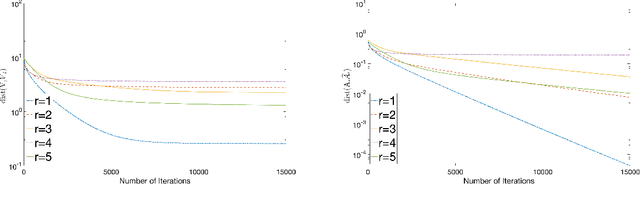


Generalized correlation analysis (GCA) is concerned with uncovering linear relationships across multiple datasets. It generalizes canonical correlation analysis that is designed for two datasets. We study sparse GCA when there are potentially multiple generalized correlation tuples in data and the loading matrix has a small number of nonzero rows. It includes sparse CCA and sparse PCA of correlation matrices as special cases. We first formulate sparse GCA as generalized eigenvalue problems at both population and sample levels via a careful choice of normalization constraints. Based on a Lagrangian form of the sample optimization problem, we propose a thresholded gradient descent algorithm for estimating GCA loading vectors and matrices in high dimensions. We derive tight estimation error bounds for estimators generated by the algorithm with proper initialization. We also demonstrate the prowess of the algorithm on a number of synthetic datasets.
LiteGEM: Lite Geometry Enhanced Molecular Representation Learning for Quantum Property Prediction
Jun 28, 2021

In this report, we (SuperHelix team) present our solution to KDD Cup 2021-PCQM4M-LSC, a large-scale quantum chemistry dataset on predicting HOMO-LUMO gap of molecules. Our solution, Lite Geometry Enhanced Molecular representation learning (LiteGEM) achieves a mean absolute error (MAE) of 0.1204 on the test set with the help of deep graph neural networks and various self-supervised learning tasks. The code of the framework can be found in https://github.com/PaddlePaddle/PaddleHelix/tree/dev/competition/kddcup2021-PCQM4M-LSC/.
A Joint Model for Dropped Pronoun Recovery and Conversational Discourse Parsing in Chinese Conversational Speech
Jun 07, 2021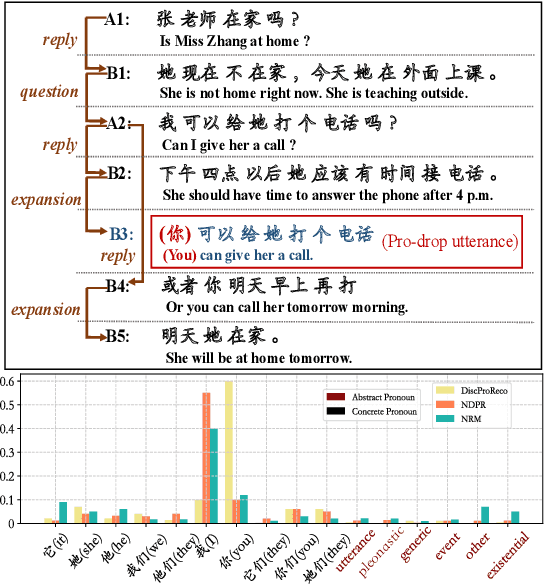
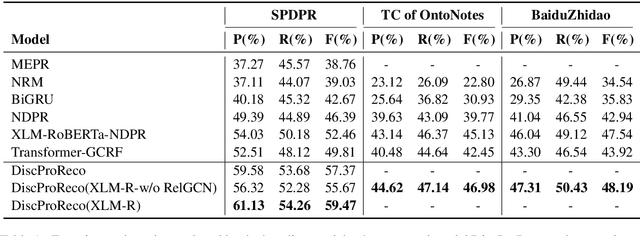
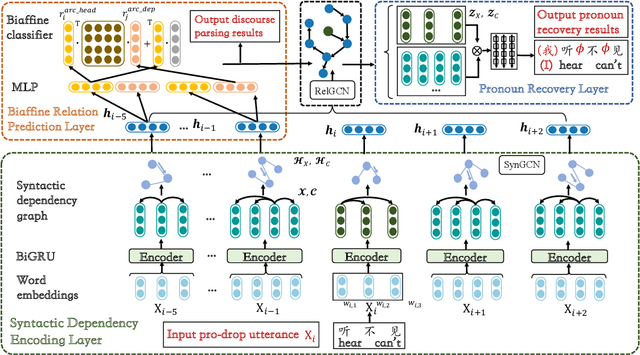
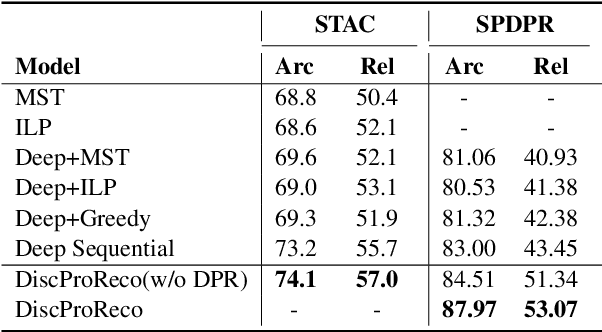
In this paper, we present a neural model for joint dropped pronoun recovery (DPR) and conversational discourse parsing (CDP) in Chinese conversational speech. We show that DPR and CDP are closely related, and a joint model benefits both tasks. We refer to our model as DiscProReco, and it first encodes the tokens in each utterance in a conversation with a directed Graph Convolutional Network (GCN). The token states for an utterance are then aggregated to produce a single state for each utterance. The utterance states are then fed into a biaffine classifier to construct a conversational discourse graph. A second (multi-relational) GCN is then applied to the utterance states to produce a discourse relation-augmented representation for the utterances, which are then fused together with token states in each utterance as input to a dropped pronoun recovery layer. The joint model is trained and evaluated on a new Structure Parsing-enhanced Dropped Pronoun Recovery (SPDPR) dataset that we annotated with both two types of information. Experimental results on the SPDPR dataset and other benchmarks show that DiscProReco significantly outperforms the state-of-the-art baselines of both tasks.
Noisy-Labeled NER with Confidence Estimation
Apr 12, 2021
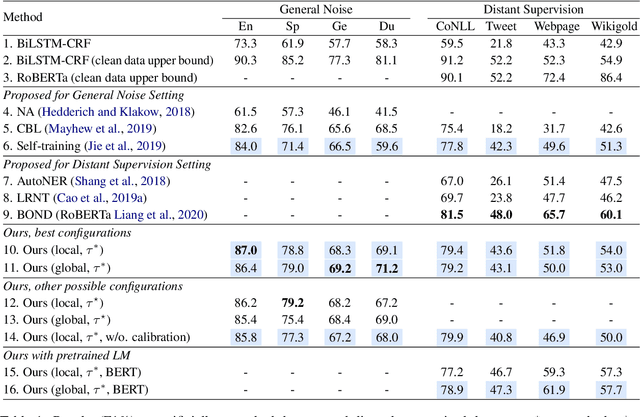
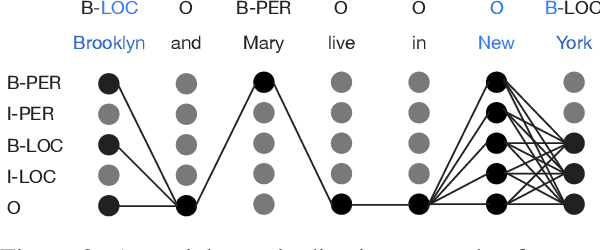
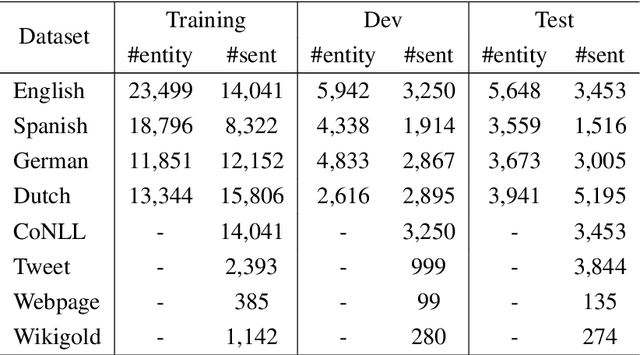
Recent studies in deep learning have shown significant progress in named entity recognition (NER). Most existing works assume clean data annotation, yet a fundamental challenge in real-world scenarios is the large amount of noise from a variety of sources (e.g., pseudo, weak, or distant annotations). This work studies NER under a noisy labeled setting with calibrated confidence estimation. Based on empirical observations of different training dynamics of noisy and clean labels, we propose strategies for estimating confidence scores based on local and global independence assumptions. We partially marginalize out labels of low confidence with a CRF model. We further propose a calibration method for confidence scores based on the structure of entity labels. We integrate our approach into a self-training framework for boosting performance. Experiments in general noisy settings with four languages and distantly labeled settings demonstrate the effectiveness of our method. Our code can be found at https://github.com/liukun95/Noisy-NER-Confidence-Estimation