 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Linear Contextual Bandits with User-level Differential Privacy
Jun 09, 2023

This paper studies federated linear contextual bandits under the notion of user-level differential privacy (DP). We first introduce a unified federated bandits framework that can accommodate various definitions of DP in the sequential decision-making setting. We then formally introduce user-level central DP (CDP) and local DP (LDP) in the federated bandits framework, and investigate the fundamental trade-offs between the learning regrets and the corresponding DP guarantees in a federated linear contextual bandits model. For CDP, we propose a federated algorithm termed as $\texttt{ROBIN}$ and show that it is near-optimal in terms of the number of clients $M$ and the privacy budget $\varepsilon$ by deriving nearly-matching upper and lower regret bounds when user-level DP is satisfied. For LDP, we obtain several lower bounds, indicating that learning under user-level $(\varepsilon,\delta)$-LDP must suffer a regret blow-up factor at least $\min\{1/\varepsilon,M\}$ or $\min\{1/\sqrt{\varepsilon},\sqrt{M}\}$ under different conditions.
DP-HyPO: An Adaptive Private Hyperparameter Optimization Framework
Jun 09, 2023Hyperparameter optimization, also known as hyperparameter tuning, is a widely recognized technique for improving model performance. Regrettably, when training private ML models, many practitioners often overlook the privacy risks associated with hyperparameter optimization, which could potentially expose sensitive information about the underlying dataset. Currently, the sole existing approach to allow privacy-preserving hyperparameter optimization is to uniformly and randomly select hyperparameters for a number of runs, subsequently reporting the best-performing hyperparameter. In contrast, in non-private settings, practitioners commonly utilize "adaptive" hyperparameter optimization methods such as Gaussian process-based optimization, which select the next candidate based on information gathered from previous outputs. This substantial contrast between private and non-private hyperparameter optimization underscores a critical concern. In our paper, we introduce DP-HyPO, a pioneering framework for "adaptive" private hyperparameter optimization, aiming to bridge the gap between private and non-private hyperparameter optimization. To accomplish this, we provide a comprehensive differential privacy analysis of our framework. Furthermore, we empirically demonstrate the effectiveness of DP-HyPO on a diverse set of real-world and synthetic datasets.
Analytical Composition of Differential Privacy via the Edgeworth Accountant
Jun 09, 2022

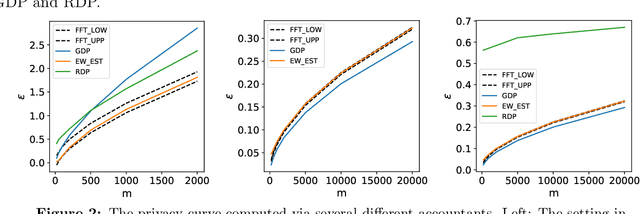

Many modern machine learning algorithms are composed of simple private algorithms; thus, an increasingly important problem is to efficiently compute the overall privacy loss under composition. In this study, we introduce the Edgeworth Accountant, an analytical approach to composing differential privacy guarantees of private algorithms. The Edgeworth Accountant starts by losslessly tracking the privacy loss under composition using the $f$-differential privacy framework, which allows us to express the privacy guarantees using privacy-loss log-likelihood ratios (PLLRs). As the name suggests, this accountant next uses the Edgeworth expansion to the upper and lower bounds the probability distribution of the sum of the PLLRs. Moreover, by relying on a technique for approximating complex distributions using simple ones, we demonstrate that the Edgeworth Accountant can be applied to the composition of any noise-addition mechanism. Owing to certain appealing features of the Edgeworth expansion, the $(\epsilon, \delta)$-differential privacy bounds offered by this accountant are non-asymptotic, with essentially no extra computational cost, as opposed to the prior approaches in, wherein the running times increase with the number of compositions. Finally, we demonstrate that our upper and lower $(\epsilon, \delta)$-differential privacy bounds are tight in federated analytics and certain regimes of training private deep learning models.