 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEO-TFV: Escape-Explore Optimizer for Web-Scale Time-Series Forecasting and Vision Analysis
Jan 30, 2026Transformer-based foundation models have achieved remarkable progress in tasks such as time-series forecasting and image segmentation. However, they frequently suffer from error accumulation in multivariate long-sequence prediction and exhibit vulnerability to out-of-distribution samples in image-related tasks. Furthermore, these challenges become particularly pronounced in large-scale Web data analysis tasks, which typically involve complex temporal patterns and multimodal features. This complexity substantially increases optimization difficulty, rendering models prone to stagnation at saddle points within high-dimensional parameter spaces. To address these issues, we propose a lightweight Transformer architecture in conjunction with a novel Escape-Explore Optimizer (EEO). The optimizer enhances both exploration and generalization while effectively avoiding sharp minima and saddle-point traps. Experimental results show that, in representative Web data scenarios, our method achieves performance on par with state-of-the-art models across 11 time-series benchmark datasets and the Synapse medical image segmentation task. Moreover, it demonstrates superior generalization and stability, thereby validating its potential as a versatile cross-task foundation model for Web-scale data mining and analysis.
From Trial to Deployment: A SEM Analysis of Traveler Adoptions to Fully Operational Autonomous Taxis
Dec 31, 2025Autonomous taxi services represent a transformative advancement in urban mobility, offering safety, efficiency, and round-the-clock operations. While existing literature has explored user acceptance of autonomous taxis through stated preference experiments and hypothetical scenarios, few studies have investigated actual user behavior based on operational AV services. This study addresses that gap by leveraging survey data from Wuhan, China, where Baidu's Apollo Robotaxi service operates at scale. We design a realistic survey incorporating actual service attributes and collect 336 valid responses from actual users. Using Structural Equation Modeling, we identify six latent psychological constructs, namely Trust \& Policy Support, Cost Sensitivity, Performance, Behavioral Intention, Lifestyle, and Education. Their influences on adoption behavior, measured by the selection frequency of autonomous taxis in ten scenarios, are examined and interpreted. Results show that Cost Sensitivity and Behavioral Intention are the strongest positive predictors of adoption, while other latent constructs play more nuanced roles. The model demonstrates strong goodness-of-fit across multiple indices. Our findings offer empirical evidence to support policymaking, fare design, and public outreach strategies for scaling autonomous taxis deployments in real-world urban settings.
Effective Attention-Guided Multi-Scale Medical Network for Skin Lesion Segmentation
Dec 08, 2025In the field of healthcare, precise skin lesion segmentation is crucial for the early detection and accurate diagnosis of skin diseases. Despite significant advances in deep learning for image processing, existing methods have yet to effectively address the challenges of irregular lesion shapes and low contrast. To address these issues, this paper proposes an innovative encoder-decoder network architecture based on multi-scale residual structures, capable of extracting rich feature information from different receptive fields to effectively identify lesion areas. By introducing a Multi-Resolution Multi-Channel Fusion (MRCF) module, our method captures cross-scale features, enhancing the clarity and accuracy of the extracted information. Furthermore, we propose a Cross-Mix Attention Module (CMAM), which redefines the attention scope and dynamically calculates weights across multiple contexts, thus improving the flexibility and depth of feature capture and enabling deeper exploration of subtle features. To overcome the information loss caused by skip connections in traditional U-Net, an External Attention Bridge (EAB) is introduced, facilitating the effective utilization of information in the decoder and compensating for the loss during upsampling. Extensive experimental evaluations on several skin lesion segmentation datasets demonstrate that the proposed model significantly outperforms existing transformer and convolutional neural network-based models, showcasing exceptional segmentation accuracy and robustness.
URPO: A Unified Reward & Policy Optimization Framework for Large Language Models
Jul 23, 2025Large-scale alignment pipelines typically pair a policy model with a separately trained reward model whose parameters remain frozen during reinforcement learning (RL). This separation creates a complex, resource-intensive pipeline and suffers from a performance ceiling due to a static reward signal. We propose a novel framework, Unified Reward & Policy Optimization (URPO), that unifies instruction-following ("player") and reward modeling ("referee") within a single model and a single training phase. Our method recasts all alignment data-including preference pairs, verifiable reasoning, and open-ended instructions-into a unified generative format optimized by a single Group-Relative Policy Optimization (GRPO) loop. This enables the model to learn from ground-truth preferences and verifiable logic while simultaneously generating its own rewards for open-ended tasks. Experiments on the Qwen2.5-7B model demonstrate URPO's superiority. Our unified model significantly outperforms a strong baseline using a separate generative reward model, boosting the instruction-following score on AlpacaEval from 42.24 to 44.84 and the composite reasoning average from 32.66 to 35.66. Furthermore, URPO cultivates a superior internal evaluator as a byproduct of training, achieving a RewardBench score of 85.15 and surpassing the dedicated reward model it replaces (83.55). By eliminating the need for a separate reward model and fostering a co-evolutionary dynamic between generation and evaluation, URPO presents a simpler, more efficient, and more effective path towards robustly aligned language models.
ABG-NAS: Adaptive Bayesian Genetic Neural Architecture Search for Graph Representation Learning
Apr 30, 2025Effective and efficient graph representation learning is essential for enabling critical downstream tasks, such as node classification, link prediction, and subgraph search. However, existing graph neural network (GNN) architectures often struggle to adapt to diverse and complex graph structures, limiting their ability to provide robust and generalizable representations. To address this challenge, we propose ABG-NAS, a novel framework for automated graph neural network architecture search tailored for efficient graph representation learning. ABG-NAS encompasses three key components: a Comprehensive Architecture Search Space (CASS), an Adaptive Genetic Optimization Strategy (AGOS), and a Bayesian-Guided Tuning Module (BGTM). CASS systematically explores diverse propagation (P) and transformation (T) operations, enabling the discovery of GNN architectures capable of capturing intricate graph characteristics. AGOS dynamically balances exploration and exploitation, ensuring search efficiency and preserving solution diversity. BGTM further optimizes hyperparameters periodically, enhancing the scalability and robustness of the resulting architectures. Empirical evaluations on benchmark datasets (Cora, PubMed, Citeseer, and CoraFull) demonstrate that ABG-NAS consistently outperforms both manually designed GNNs and state-of-the-art neural architecture search (NAS) methods. These results highlight the potential of ABG-NAS to advance graph representation learning by providing scalable and adaptive solutions for diverse graph structures. Our code is publicly available at https://github.com/sserranw/ABG-NAS.
DeskVision: Large Scale Desktop Region Captioning for Advanced GUI Agents
Mar 14, 2025



The limitation of graphical user interface (GUI) data has been a significant barrier to the development of GUI agents today, especially for the desktop / computer use scenarios. To address this, we propose an automated GUI data generation pipeline, AutoCaptioner, which generates data with rich descriptions while minimizing human effort. Using AutoCaptioner, we created a novel large-scale desktop GUI dataset, DeskVision, along with the largest desktop test benchmark, DeskVision-Eval, which reflects daily usage and covers diverse systems and UI elements, each with rich descriptions. With DeskVision, we train a new GUI understanding model, GUIExplorer. Results show that GUIExplorer achieves state-of-the-art (SOTA) performance in understanding/grounding visual elements without the need for complex architectural designs. We further validated the effectiveness of the DeskVision dataset through ablation studies on various large visual language models (LVLMs). We believe that AutoCaptioner and DeskVision will significantly advance the development of GUI agents, and will open-source them for the community.
SEKI: Self-Evolution and Knowledge Inspiration based Neural Architecture Search via Large Language Models
Feb 27, 2025We introduce SEKI, a novel large language model (LLM)-based neural architecture search (NAS) method. Inspired by the chain-of-thought (CoT) paradigm in modern LLMs, SEKI operates in two key stages: self-evolution and knowledge distillation. In the self-evolution stage, LLMs initially lack sufficient reference examples, so we implement an iterative refinement mechanism that enhances architectures based on performance feedback. Over time, this process accumulates a repository of high-performance architectures. In the knowledge distillation stage, LLMs analyze common patterns among these architectures to generate new, optimized designs. Combining these two stages, SEKI greatly leverages the capacity of LLMs on NAS and without requiring any domain-specific data. Experimental results show that SEKI achieves state-of-the-art (SOTA) performance across various datasets and search spaces while requiring only 0.05 GPU-days, outperforming existing methods in both efficiency and accuracy. Furthermore, SEKI demonstrates strong generalization capabilities, achieving SOTA-competitive results across multiple tasks.
Transfer Learning Assisted Fast Design Migration Over Technology Nodes: A Study on Transformer Matching Network
Feb 25, 2025In this study, we introduce an innovative methodology for the design of mm-Wave passive networks that leverages knowledge transfer from a pre-trained synthesis neural network (NN) model in one technology node and achieves swift and reliable design adaptation across different integrated circuit (IC) technologies, operating frequencies, and metal options. We prove this concept through simulation-based demonstrations focusing on the training and comparison of the coefficient of determination (R2) of synthesis NNs for 1:1 on-chip transformers in GlobalFoundries(GF) 22nm FDX+ (target domain), with and without transfer learning from a model trained in GF 45nm SOI (source domain). In the experiments, we explore varying target data densities of 0.5%, 1%, 5%, and 100% with a complete dataset of 0.33 million in GF 22FDX+, and for comparative analysis, apply source data densities of 25%, 50%, 75%, and 100% with a complete dataset of 2.5 million in GF 45SOI. With the source data only at 30GHz, the experiments span target data from two metal options in GF 22FDX+ at frequencies of 30 and 39 GHz. The results prove that the transfer learning with the source domain knowledge (GF 45SOI) can both accelerate the training process in the target domain (GF 22FDX+) and improve the R2 values compared to models without knowledge transfer. Furthermore, it is observed that a model trained with just 5% of target data and augmented by transfer learning achieves R2 values superior to a model trained with 20% of the data without transfer, validating the advantage seen from 1% to 5% data density. This demonstrates a notable reduction of 4X in the necessary dataset size highlighting the efficacy of utilizing transfer learning to mm-Wave passive network design. The PyTorch learning and testing code is publicly available at https://github.com/ChenhaoChu/RFIC-TL.
Round Attention: A Novel Round-Level Attention Mechanism to Accelerate LLM Inference
Feb 21, 2025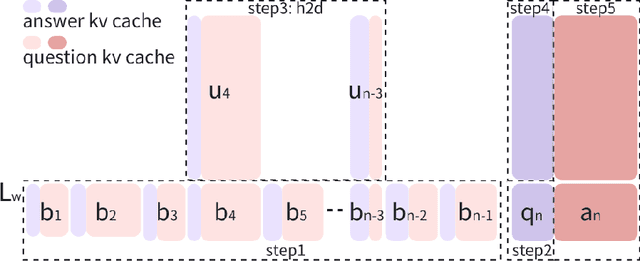
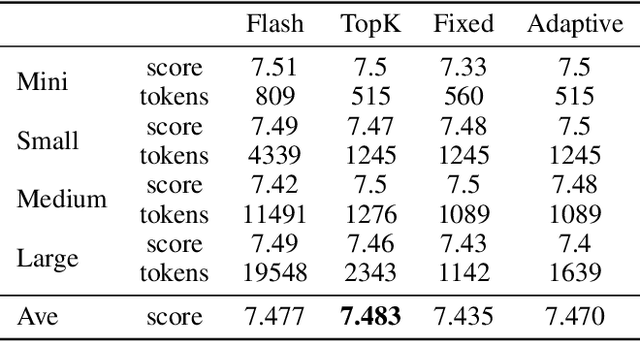
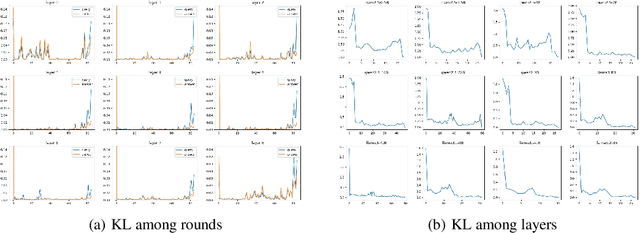
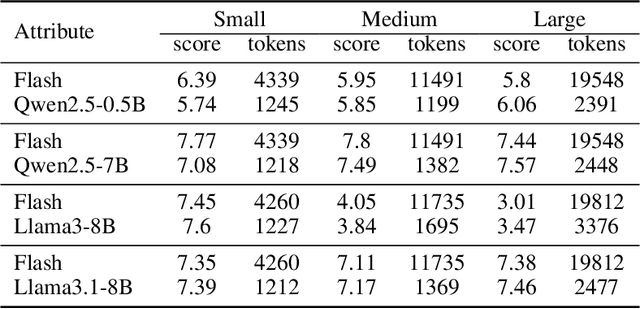
The increasing context window size in large language models (LLMs) has improved their ability to handle complex, long-text tasks. However, as the conversation rounds continue, it is required to store a large amount of KV cache in GPU memory, which significantly affects the efficiency and even availability of the model serving systems. This paper analyzes dialogue data from real users and discovers that the LLM inference manifests a watershed layer, after which the distribution of round-level attention shows notable similarity. We propose Round Attention, a novel round-level attention mechanism that only recalls and computes the KV cache of the most relevant rounds. The experiments show that our method saves 55\% memory usage without compromising model performance.
Gradient-Guided Conditional Diffusion Models for Private Image Reconstruction: Analyzing Adversarial Impacts of Differential Privacy and Denoising
Nov 05, 2024
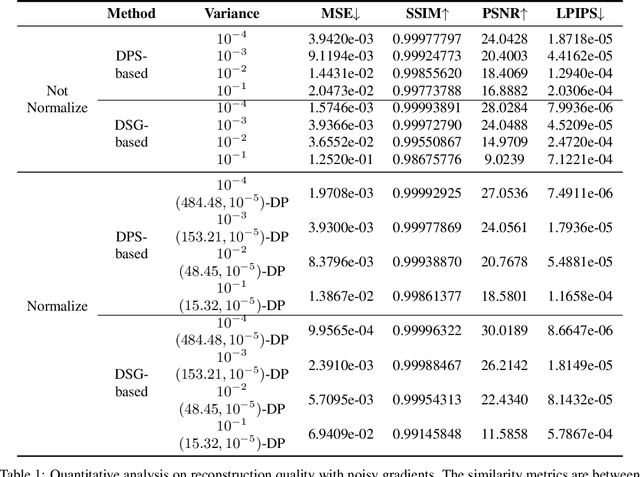
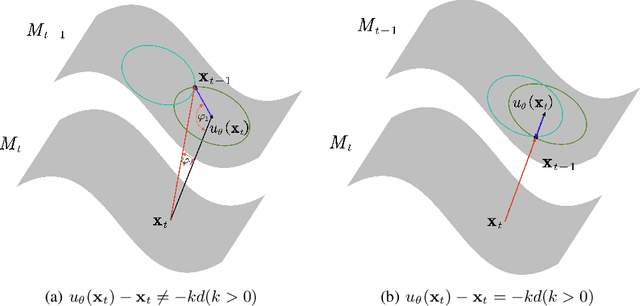
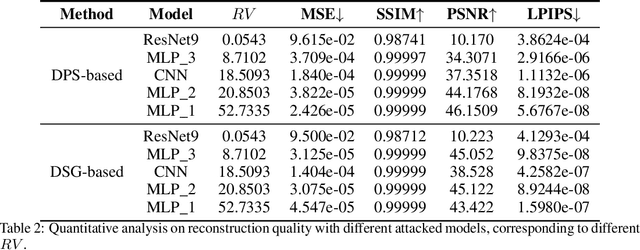
We investigate the construction of gradient-guided conditional diffusion models for reconstructing private images, focusing on the adversarial interplay between differential privacy noise and the denoising capabilities of diffusion models. While current gradient-based reconstruction methods struggle with high-resolution images due to computational complexity and prior knowledge requirements, we propose two novel methods that require minimal modifications to the diffusion model's generation process and eliminate the need for prior knowledge. Our approach leverages the strong image generation capabilities of diffusion models to reconstruct private images starting from randomly generated noise, even when a small amount of differentially private noise has been added to the gradients. We also conduct a comprehensive theoretical analysis of the impact of differential privacy noise on the quality of reconstructed images, revealing the relationship among noise magnitude, the architecture of attacked models, and the attacker's reconstruction capability. Additionally, extensive experiments validate the effectiveness of our proposed methods and the accuracy of our theoretical findings, suggesting new directions for privacy risk auditing using conditional diffusion models.