 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrat-Reasoner: Reinforcing Strategic Reasoning of LLMs in Multi-Agent Games
May 06, 2026While Large Language Models (LLMs) excel in certain reasoning tasks, they struggle in multi-agent games where the final outcome depends on the joint strategies of all agents. In multi-agent games, the non-stationarity of other agents brings significant challenges on the evaluation of the reasoning process and the credit assignment over multiple reasoning steps. Existing single-agent reinforcement learning (RL) approaches and their multi-agent extensions fail to address these challenges as they do not incorporate other agents in the reasoning process. In this work, we propose Strat-Reasoner, a novel RL-based framework that improves LLMs' strategic reasoning ability in multi-agent games. We introduce a novel recursive reasoning paradigm where an agent's reasoning also integrates other agents' reasoning processes. To provide effective reward signals for the intermediate reasoning sequences, we employ a centralized Chain-of-Thought (CoT) comparison module to evaluate the reasoning quality. Finally, we compute an accurate hybrid advantage and develop a group-relative RL approach to optimize the LLM policy. Experimental results show that Strat-Reasoner substantially improves strategic abilities of underlying LLMs, achieving 22.1\% average performance improvements across various multi-agent games.
Beyond the Node: Clade-level Selection for Efficient MCTS in Automatic Heuristic Design
Jan 31, 2026While Monte Carlo Tree Search (MCTS) shows promise in Large Language Model (LLM) based Automatic Heuristic Design (AHD), it suffers from a critical over-exploitation tendency under the limited computational budgets required for heuristic evaluation. To address this limitation, we propose Clade-AHD, an efficient framework that replaces node-level point estimates with clade-level Bayesian beliefs. By aggregating descendant evaluations into Beta distributions and performing Thompson Sampling over these beliefs, Clade-AHD explicitly models uncertainty to guide exploration, enabling more reliable decision-making under sparse and noisy evaluations. Extensive experiments on complex combinatorial optimization problems demonstrate that Clade-AHD consistently outperforms state-of-the-art methods while significantly reducing computational cost. The source code is publicly available at: https://github.com/Mriya0306/Clade-AHD.
SEKI: Self-Evolution and Knowledge Inspiration based Neural Architecture Search via Large Language Models
Feb 27, 2025We introduce SEKI, a novel large language model (LLM)-based neural architecture search (NAS) method. Inspired by the chain-of-thought (CoT) paradigm in modern LLMs, SEKI operates in two key stages: self-evolution and knowledge distillation. In the self-evolution stage, LLMs initially lack sufficient reference examples, so we implement an iterative refinement mechanism that enhances architectures based on performance feedback. Over time, this process accumulates a repository of high-performance architectures. In the knowledge distillation stage, LLMs analyze common patterns among these architectures to generate new, optimized designs. Combining these two stages, SEKI greatly leverages the capacity of LLMs on NAS and without requiring any domain-specific data. Experimental results show that SEKI achieves state-of-the-art (SOTA) performance across various datasets and search spaces while requiring only 0.05 GPU-days, outperforming existing methods in both efficiency and accuracy. Furthermore, SEKI demonstrates strong generalization capabilities, achieving SOTA-competitive results across multiple tasks.
Evolutionary Verbalizer Search for Prompt-based Few Shot Text Classification
Jun 18, 2023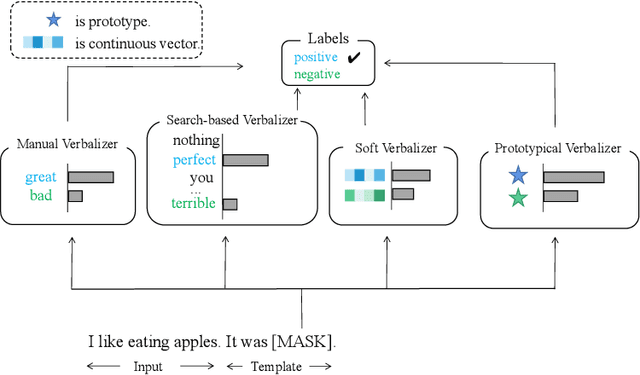
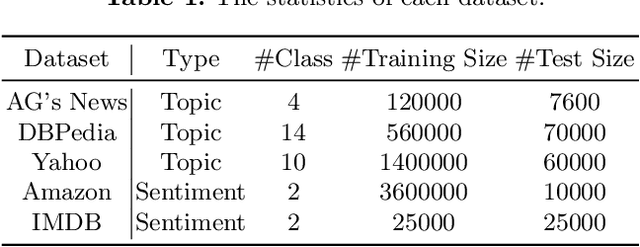
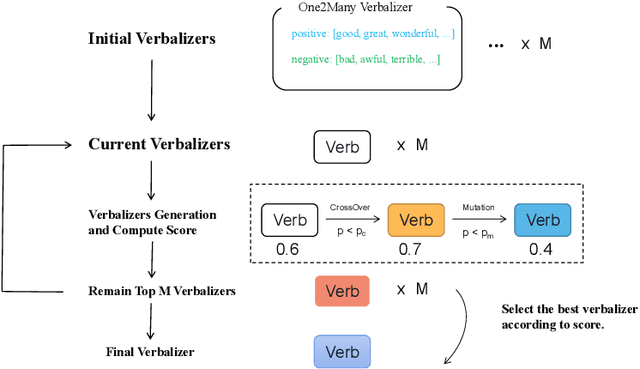
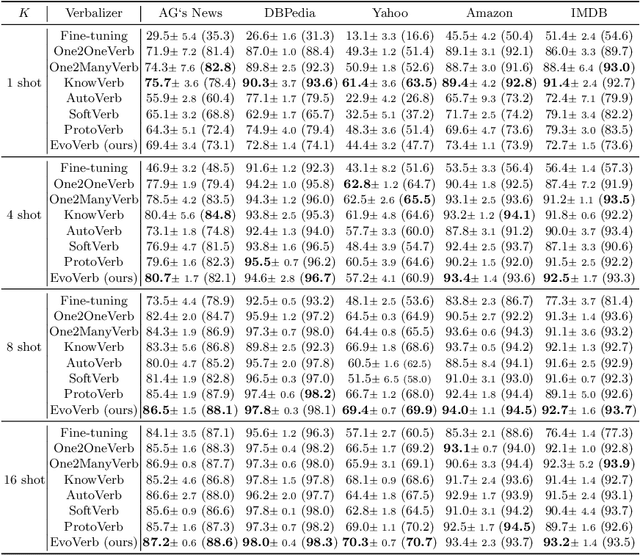
Recent advances for few-shot text classification aim to wrap textual inputs with task-specific prompts to cloze questions. By processing them with a masked language model to predict the masked tokens and using a verbalizer that constructs the mapping between predicted words and target labels. This approach of using pre-trained language models is called prompt-based tuning, which could remarkably outperform conventional fine-tuning approach in the low-data scenario. As the core of prompt-based tuning, the verbalizer is usually handcrafted with human efforts or suboptimally searched by gradient descent. In this paper, we focus on automatically constructing the optimal verbalizer and propose a novel evolutionary verbalizer search (EVS) algorithm, to improve prompt-based tuning with the high-performance verbalizer. Specifically, inspired by evolutionary algorithm (EA), we utilize it to automatically evolve various verbalizers during the evolutionary procedure and select the best one after several iterations. Extensive few-shot experiments on five text classification datasets show the effectiveness of our method.