 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURPO: A Unified Reward & Policy Optimization Framework for Large Language Models
Jul 23, 2025Large-scale alignment pipelines typically pair a policy model with a separately trained reward model whose parameters remain frozen during reinforcement learning (RL). This separation creates a complex, resource-intensive pipeline and suffers from a performance ceiling due to a static reward signal. We propose a novel framework, Unified Reward & Policy Optimization (URPO), that unifies instruction-following ("player") and reward modeling ("referee") within a single model and a single training phase. Our method recasts all alignment data-including preference pairs, verifiable reasoning, and open-ended instructions-into a unified generative format optimized by a single Group-Relative Policy Optimization (GRPO) loop. This enables the model to learn from ground-truth preferences and verifiable logic while simultaneously generating its own rewards for open-ended tasks. Experiments on the Qwen2.5-7B model demonstrate URPO's superiority. Our unified model significantly outperforms a strong baseline using a separate generative reward model, boosting the instruction-following score on AlpacaEval from 42.24 to 44.84 and the composite reasoning average from 32.66 to 35.66. Furthermore, URPO cultivates a superior internal evaluator as a byproduct of training, achieving a RewardBench score of 85.15 and surpassing the dedicated reward model it replaces (83.55). By eliminating the need for a separate reward model and fostering a co-evolutionary dynamic between generation and evaluation, URPO presents a simpler, more efficient, and more effective path towards robustly aligned language models.
DeskVision: Large Scale Desktop Region Captioning for Advanced GUI Agents
Mar 14, 2025



The limitation of graphical user interface (GUI) data has been a significant barrier to the development of GUI agents today, especially for the desktop / computer use scenarios. To address this, we propose an automated GUI data generation pipeline, AutoCaptioner, which generates data with rich descriptions while minimizing human effort. Using AutoCaptioner, we created a novel large-scale desktop GUI dataset, DeskVision, along with the largest desktop test benchmark, DeskVision-Eval, which reflects daily usage and covers diverse systems and UI elements, each with rich descriptions. With DeskVision, we train a new GUI understanding model, GUIExplorer. Results show that GUIExplorer achieves state-of-the-art (SOTA) performance in understanding/grounding visual elements without the need for complex architectural designs. We further validated the effectiveness of the DeskVision dataset through ablation studies on various large visual language models (LVLMs). We believe that AutoCaptioner and DeskVision will significantly advance the development of GUI agents, and will open-source them for the community.
SEKI: Self-Evolution and Knowledge Inspiration based Neural Architecture Search via Large Language Models
Feb 27, 2025We introduce SEKI, a novel large language model (LLM)-based neural architecture search (NAS) method. Inspired by the chain-of-thought (CoT) paradigm in modern LLMs, SEKI operates in two key stages: self-evolution and knowledge distillation. In the self-evolution stage, LLMs initially lack sufficient reference examples, so we implement an iterative refinement mechanism that enhances architectures based on performance feedback. Over time, this process accumulates a repository of high-performance architectures. In the knowledge distillation stage, LLMs analyze common patterns among these architectures to generate new, optimized designs. Combining these two stages, SEKI greatly leverages the capacity of LLMs on NAS and without requiring any domain-specific data. Experimental results show that SEKI achieves state-of-the-art (SOTA) performance across various datasets and search spaces while requiring only 0.05 GPU-days, outperforming existing methods in both efficiency and accuracy. Furthermore, SEKI demonstrates strong generalization capabilities, achieving SOTA-competitive results across multiple tasks.
Round Attention: A Novel Round-Level Attention Mechanism to Accelerate LLM Inference
Feb 21, 2025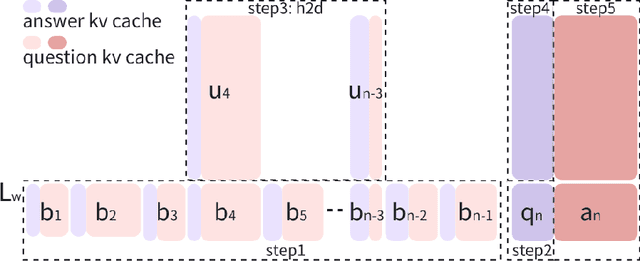
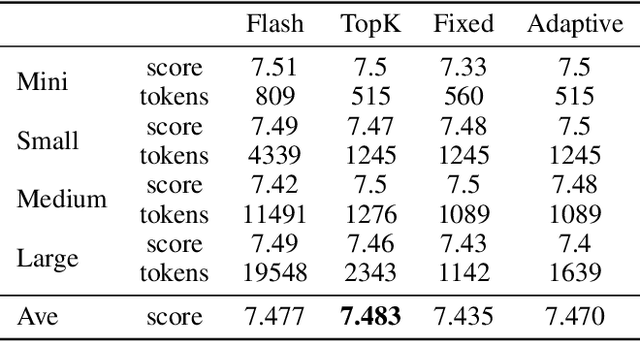
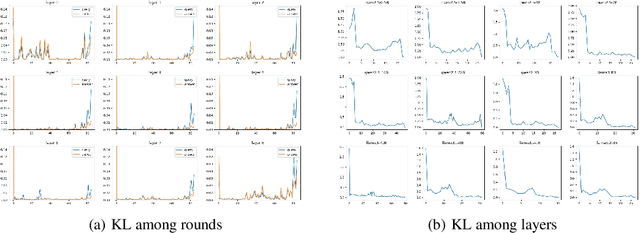
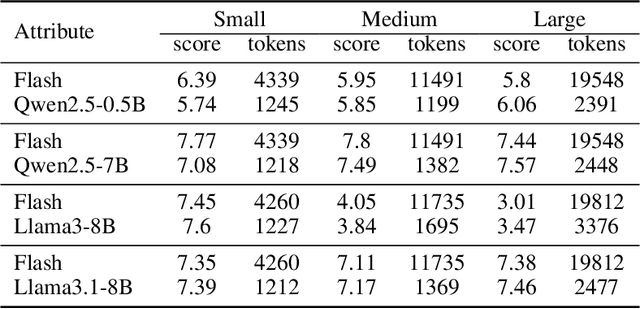
The increasing context window size in large language models (LLMs) has improved their ability to handle complex, long-text tasks. However, as the conversation rounds continue, it is required to store a large amount of KV cache in GPU memory, which significantly affects the efficiency and even availability of the model serving systems. This paper analyzes dialogue data from real users and discovers that the LLM inference manifests a watershed layer, after which the distribution of round-level attention shows notable similarity. We propose Round Attention, a novel round-level attention mechanism that only recalls and computes the KV cache of the most relevant rounds. The experiments show that our method saves 55\% memory usage without compromising model performance.
TurboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text
Oct 10, 2024



Current Retrieval-Augmented Generation (RAG) systems concatenate and process numerous retrieved document chunks for prefill which requires a large volume of computation, therefore leading to significant latency in time-to-first-token (TTFT). To reduce the computation overhead as well as TTFT, we introduce TurboRAG, a novel RAG system that redesigns the inference paradigm of the current RAG system by first pre-computing and storing the key-value (KV) caches of documents offline, and then directly retrieving the saved KV cache for prefill. Hence, online computation of KV caches is eliminated during inference. In addition, we provide a number of insights into the mask matrix and positional embedding mechanisms, plus fine-tune a pretrained language model to maintain model accuracy of TurboRAG. Our approach is applicable to most existing large language models and their applications without any requirement in modification of models and inference systems. Experimental results across a suite of RAG benchmarks demonstrate that TurboRAG reduces TTFT by up to 9.4x compared to the conventional RAG systems (on an average of 8.6x), but reserving comparable performance to the standard RAG systems.
A Full-duplex Speech Dialogue Scheme Based On Large Language Models
May 29, 2024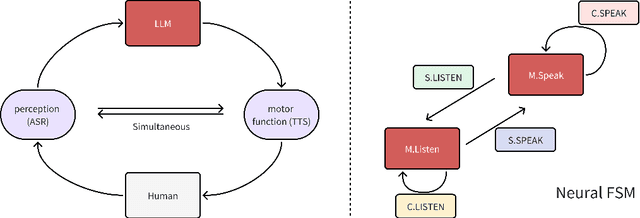


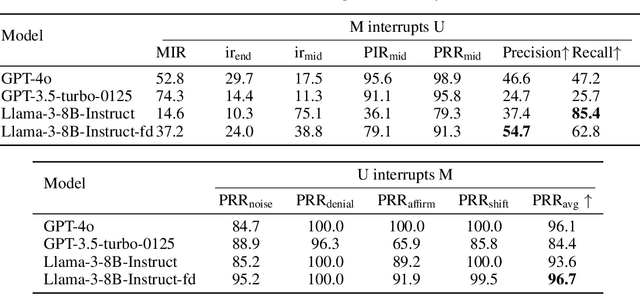
We present a generative dialogue system capable of operating in a full-duplex manner, allowing for seamless interaction. It is based on a large language model (LLM) carefully aligned to be aware of a perception module, a motor function module, and the concept of a simple finite state machine (called neural FSM) with two states. The perception and motor function modules operate simultaneously, allowing the system to simultaneously speak and listen to the user. The LLM generates textual tokens for inquiry responses and makes autonomous decisions to start responding to, wait for, or interrupt the user by emitting control tokens to the neural FSM. All these tasks of the LLM are carried out as next token prediction on a serialized view of the dialogue in real-time. In automatic quality evaluations simulating real-life interaction, the proposed system reduces the average conversation response latency by more than 3 folds compared with LLM-based half-duplex dialogue systems while responding within less than 500 milliseconds in more than 50% of evaluated interactions. Running a LLM with only 8 billion parameters, our system exhibits a 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.
CNN-based Realized Covariance Matrix Forecasting
Jul 22, 2021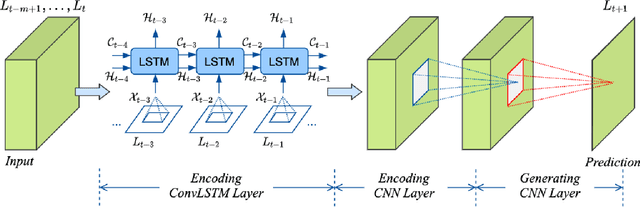
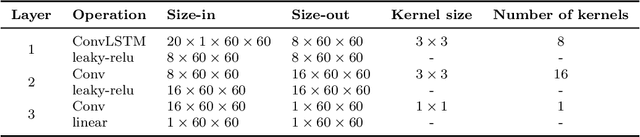
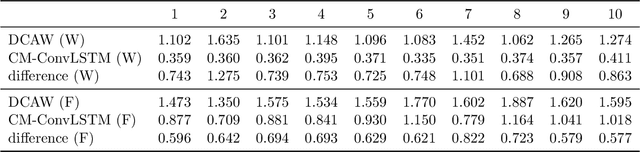
It is well known that modeling and forecasting realized covariance matrices of asset returns play a crucial role in the field of finance. The availability of high frequency intraday data enables the modeling of the realized covariance matrices directly. However, most of the models available in the literature depend on strong structural assumptions and they often suffer from the curse of dimensionality. We propose an end-to-end trainable model built on the CNN and Convolutional LSTM (ConvLSTM) which does not require to make any distributional or structural assumption but could handle high-dimensional realized covariance matrices consistently. The proposed model focuses on local structures and spatiotemporal correlations. It learns a nonlinear mapping that connect the historical realized covariance matrices to the future one. Our empirical studies on synthetic and real-world datasets demonstrate its excellent forecasting ability compared with several advanced volatility models.
Neural Machine Translation with External Phrase Memory
Jun 06, 2016
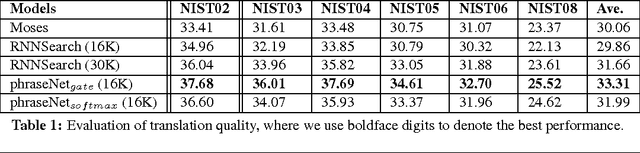


In this paper, we propose phraseNet, a neural machine translator with a phrase memory which stores phrase pairs in symbolic form, mined from corpus or specified by human experts. For any given source sentence, phraseNet scans the phrase memory to determine the candidate phrase pairs and integrates tagging information in the representation of source sentence accordingly. The decoder utilizes a mixture of word-generating component and phrase-generating component, with a specifically designed strategy to generate a sequence of multiple words all at once. The phraseNet not only approaches one step towards incorporating external knowledge into neural machine translation, but also makes an effort to extend the word-by-word generation mechanism of recurrent neural network. Our empirical study on Chinese-to-English translation shows that, with carefully-chosen phrase table in memory, phraseNet yields 3.45 BLEU improvement over the generic neural machine translator.