 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacyRestore: Privacy-Preserving Inference in Large Language Models via Privacy Removal and Restoration
Jun 03, 2024



The widespread usage of online Large Language Models (LLMs) inference services has raised significant privacy concerns about the potential exposure of private information in user inputs to eavesdroppers or untrustworthy service providers. Existing privacy protection methods for LLMs suffer from insufficient privacy protection, performance degradation, or severe inference time overhead. In this paper, we propose PrivacyRestore to protect the privacy of user inputs during LLM inference. PrivacyRestore directly removes privacy spans in user inputs and restores privacy information via activation steering during inference. The privacy spans are encoded as restoration vectors. We propose Attention-aware Weighted Aggregation (AWA) which aggregates restoration vectors of all privacy spans in the input into a meta restoration vector. AWA not only ensures proper representation of all privacy spans but also prevents attackers from inferring the privacy spans from the meta restoration vector alone. This meta restoration vector, along with the query with privacy spans removed, is then sent to the server. The experimental results show that PrivacyRestore can protect private information while maintaining acceptable levels of performance and inference efficiency.
Eraser: Jailbreaking Defense in Large Language Models via Unlearning Harmful Knowledge
Apr 08, 2024



Jailbreaking attacks can enable Large Language Models (LLMs) to bypass the safeguard and generate harmful content. Existing jailbreaking defense methods have failed to address the fundamental issue that harmful knowledge resides within the model, leading to potential jailbreak risks for LLMs. In this paper, we propose a novel defense method called Eraser, which mainly includes three goals: unlearning harmful knowledge, retaining general knowledge, and maintaining safety alignment. The intuition is that if an LLM forgets the specific knowledge required to answer a harmful question, it will no longer have the ability to answer harmful questions. The training of Erase does not actually require the model's own harmful knowledge, and it can benefit from unlearning general answers related to harmful queries, which means it does not need assistance from the red team. The experimental results show that Eraser can significantly reduce the jailbreaking success rate for various attacks without compromising the general capabilities of the model.
Weakly Supervised Reasoning by Neuro-Symbolic Approaches
Sep 19, 2023



Deep learning has largely improved the performance of various natural language processing (NLP) tasks. However, most deep learning models are black-box machinery, and lack explicit interpretation. In this chapter, we will introduce our recent progress on neuro-symbolic approaches to NLP, which combines different schools of AI, namely, symbolism and connectionism. Generally, we will design a neural system with symbolic latent structures for an NLP task, and apply reinforcement learning or its relaxation to perform weakly supervised reasoning in the downstream task. Our framework has been successfully applied to various tasks, including table query reasoning, syntactic structure reasoning, information extraction reasoning, and rule reasoning. For each application, we will introduce the background, our approach, and experimental results.
Self-Balanced Dropout
Aug 06, 2019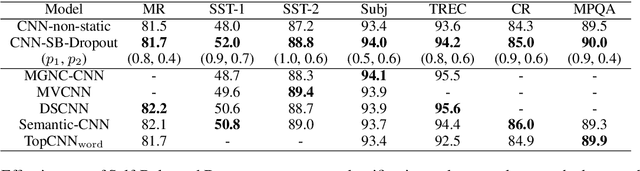
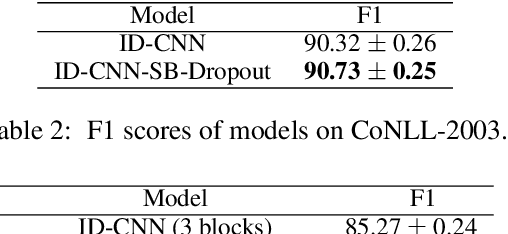
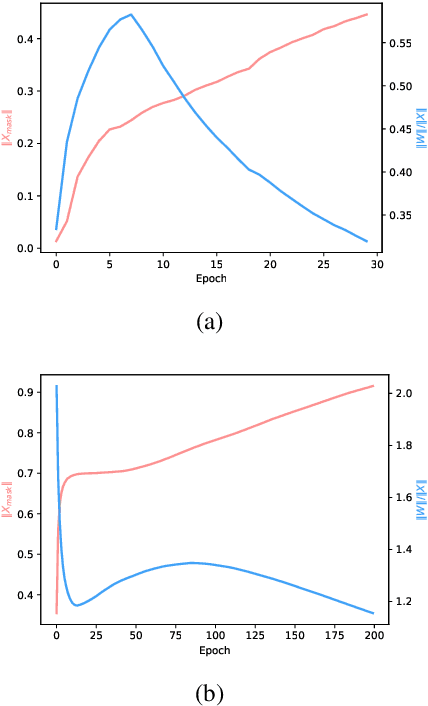
Dropout is known as an effective way to reduce overfitting via preventing co-adaptations of units. In this paper, we theoretically prove that the co-adaptation problem still exists after using dropout due to the correlations among the inputs. Based on the proof, we further propose Self-Balanced Dropout, a novel dropout method which uses a trainable variable to balance the influence of the input correlation on parameter update. We evaluate Self-Balanced Dropout on a range of tasks with both simple and complex models. The experimental results show that the mechanism can effectively solve the co-adaption problem to some extent and significantly improve the performance on all tasks.
Neural Entity Reasoner for Global Consistency in NER
Sep 30, 2018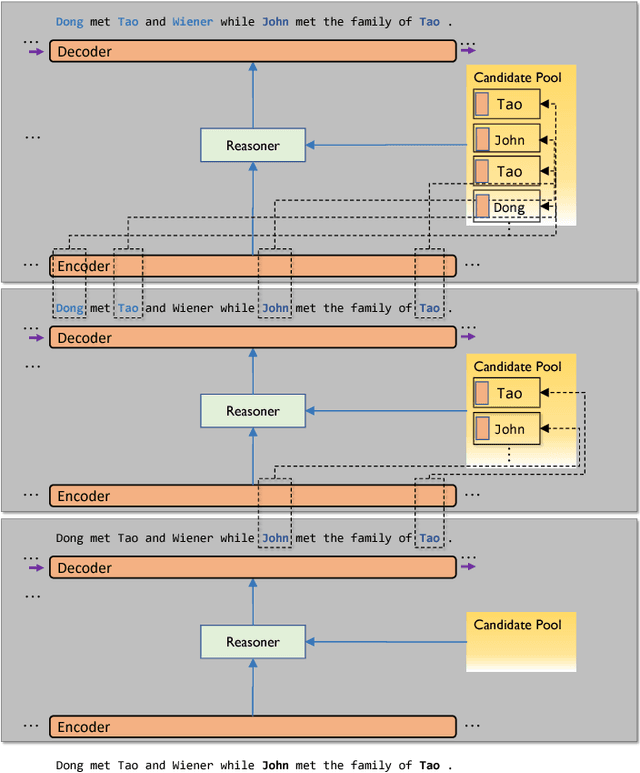
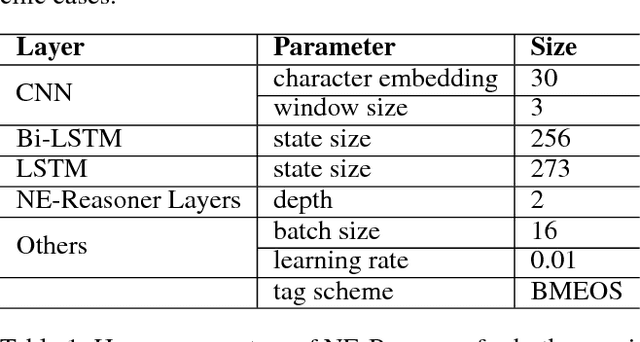
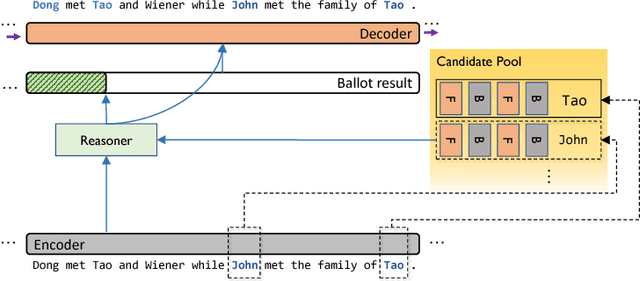
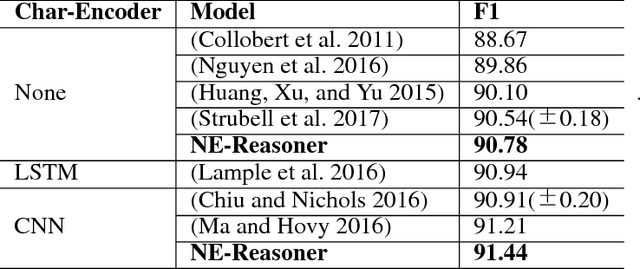
We propose Neural Entity Reasoner (NE-Reasoner), a framework to introduce global consistency of recognized entities into Neural Reasoner over Named Entity Recognition (NER) task. Given an input sentence, the NE-Reasoner layer can infer over multiple entities to increase the global consistency of output labels, which then be transfered into entities for the input of next layer. NE-Reasoner inherits and develops some features from Neural Reasoner 1) a symbolic memory, allowing it to exchange entities between layers. 2) the specific interaction-pooling mechanism, allowing it to connect each local word to multiple global entities, and 3) the deep architecture, allowing it to bootstrap the recognized entity set from coarse to fine. Like human beings, NE-Reasoner is able to accommodate ambiguous words and Name Entities that rarely or never met before. Despite the symbolic information the model introduced, NE-Reasoner can still be trained effectively in an end-to-end manner via parameter sharing strategy. NE-Reasoner can outperform conventional NER models in most cases on both English and Chinese NER datasets. For example, it achieves state-of-art on CoNLL-2003 English NER dataset.
Generalize Symbolic Knowledge With Neural Rule Engine
Sep 04, 2018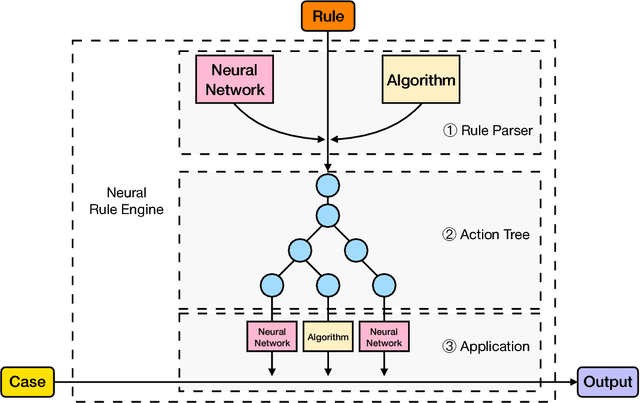


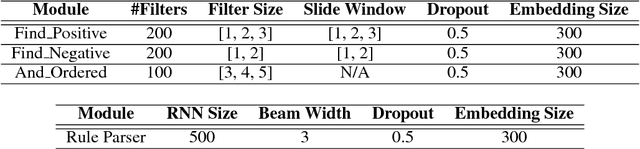
Neural-symbolic learning aims to take the advantages of both neural networks and symbolic knowledge to build better intelligent systems. As neural networks have dominated the state-of-the-art results in a wide range of NLP tasks, it attracts considerable attention to improve the performance of neural models by integrating symbolic knowledge. Different from existing works, this paper investigates the combination of these two powerful paradigms from the knowledge-driven side. We propose Neural Rule Engine (NRE), which can learn knowledge explicitly from logic rules and then generalize them implicitly with neural networks. NRE is implemented with neural module networks in which each module represents an action of the logic rule. The experiments show that NRE could greatly improve the generalization abilities of logic rules with a significant increase on recall. Meanwhile, the precision is still maintained at a high level.
Object-oriented Neural Programming (OONP) for Document Understanding
Jul 25, 2018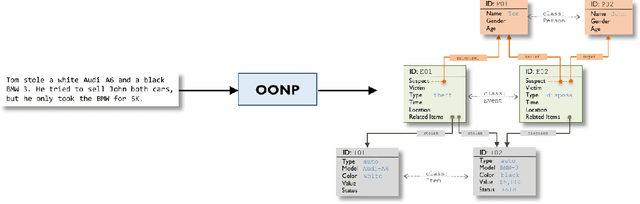

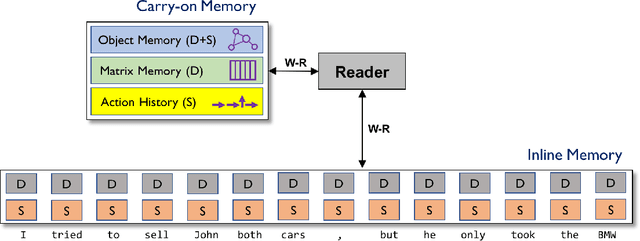

We propose Object-oriented Neural Programming (OONP), a framework for semantically parsing documents in specific domains. Basically, OONP reads a document and parses it into a predesigned object-oriented data structure (referred to as ontology in this paper) that reflects the domain-specific semantics of the document. An OONP parser models semantic parsing as a decision process: a neural net-based Reader sequentially goes through the document, and during the process it builds and updates an intermediate ontology to summarize its partial understanding of the text it covers. OONP supports a rich family of operations (both symbolic and differentiable) for composing the ontology, and a big variety of forms (both symbolic and differentiable) for representing the state and the document. An OONP parser can be trained with supervision of different forms and strength, including supervised learning (SL) , reinforcement learning (RL) and hybrid of the two. Our experiments on both synthetic and real-world document parsing tasks have shown that OONP can learn to handle fairly complicated ontology with training data of modest sizes.
JUMPER: Learning When to Make Classification Decisions in Reading
Jul 06, 2018
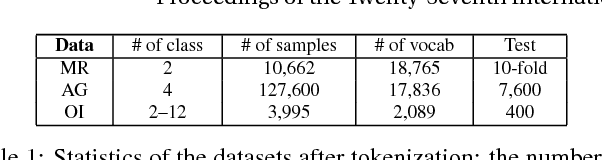
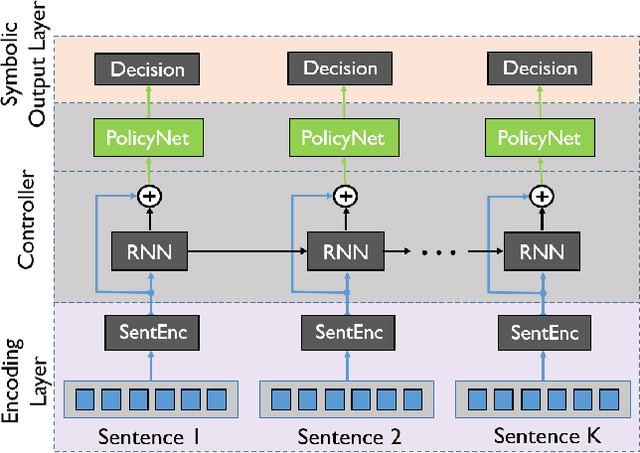
In early years, text classification is typically accomplished by feature-based machine learning models; recently, deep neural networks, as a powerful learning machine, make it possible to work with raw input as the text stands. However, exiting end-to-end neural networks lack explicit interpretation of the prediction. In this paper, we propose a novel framework, JUMPER, inspired by the cognitive process of text reading, that models text classification as a sequential decision process. Basically, JUMPER is a neural system that scans a piece of text sequentially and makes classification decisions at the time it wishes. Both the classification result and when to make the classification are part of the decision process, which is controlled by a policy network and trained with reinforcement learning. Experimental results show that a properly trained JUMPER has the following properties: (1) It can make decisions whenever the evidence is enough, therefore reducing total text reading by 30-40% and often finding the key rationale of prediction. (2) It achieves classification accuracy better than or comparable to state-of-the-art models in several benchmark and industrial datasets.
Event Identification as a Decision Process with Non-linear Representation of Text
Oct 03, 2017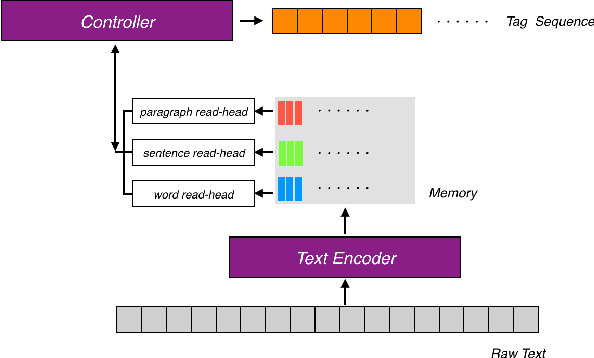

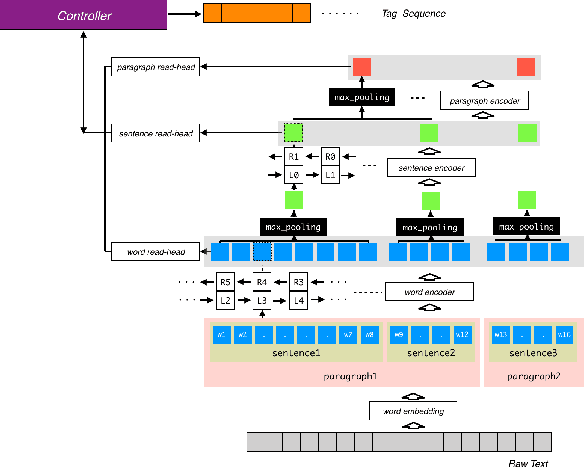

We propose scale-free Identifier Network(sfIN), a novel model for event identification in documents. In general, sfIN first encodes a document into multi-scale memory stacks, then extracts special events via conducting multi-scale actions, which can be considered as a special type of sequence labelling. The design of large scale actions makes it more efficient processing a long document. The whole model is trained with both supervised learning and reinforcement learning.
Coupling Distributed and Symbolic Execution for Natural Language Queries
Jun 16, 2017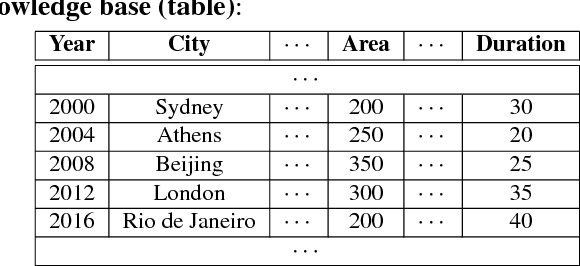
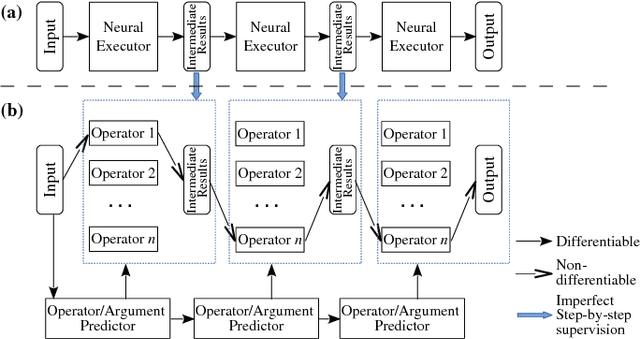
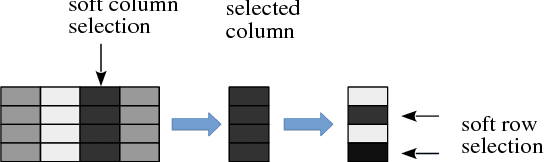
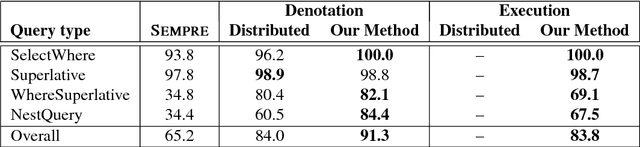
Building neural networks to query a knowledge base (a table) with natural language is an emerging research topic in deep learning. An executor for table querying typically requires multiple steps of execution because queries may have complicated structures. In previous studies, researchers have developed either fully distributed executors or symbolic executors for table querying. A distributed executor can be trained in an end-to-end fashion, but is weak in terms of execution efficiency and explicit interpretability. A symbolic executor is efficient in execution, but is very difficult to train especially at initial stages. In this paper, we propose to couple distributed and symbolic execution for natural language queries, where the symbolic executor is pretrained with the distributed executor's intermediate execution results in a step-by-step fashion. Experiments show that our approach significantly outperforms both distributed and symbolic executors, exhibiting high accuracy, high learning efficiency, high execution efficiency, and high interpretability.