 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUMPER: Learning When to Make Classification Decisions in Reading
Paper and Code
Jul 06, 2018
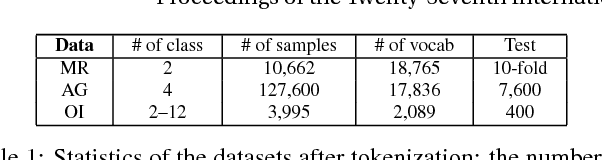
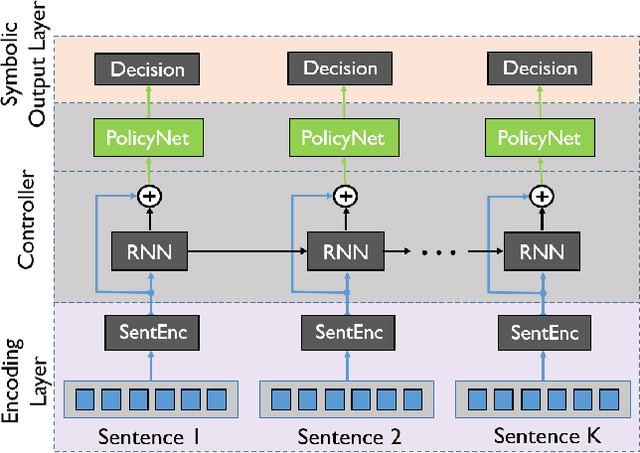
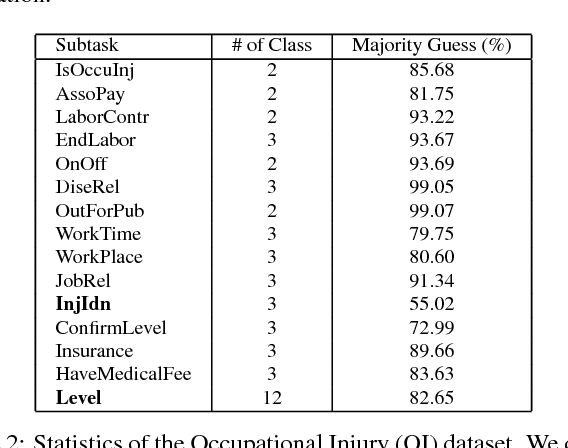
In early years, text classification is typically accomplished by feature-based machine learning models; recently, deep neural networks, as a powerful learning machine, make it possible to work with raw input as the text stands. However, exiting end-to-end neural networks lack explicit interpretation of the prediction. In this paper, we propose a novel framework, JUMPER, inspired by the cognitive process of text reading, that models text classification as a sequential decision process. Basically, JUMPER is a neural system that scans a piece of text sequentially and makes classification decisions at the time it wishes. Both the classification result and when to make the classification are part of the decision process, which is controlled by a policy network and trained with reinforcement learning. Experimental results show that a properly trained JUMPER has the following properties: (1) It can make decisions whenever the evidence is enough, therefore reducing total text reading by 30-40% and often finding the key rationale of prediction. (2) It achieves classification accuracy better than or comparable to state-of-the-art models in several benchmark and industrial datasets.