 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeExp: Explanatory Code Document Generation
Nov 25, 2022Developing models that can automatically generate detailed code explanation can greatly benefit software maintenance and programming education. However, existing code-to-text generation models often produce only high-level summaries of code that do not capture implementation-level choices essential for these scenarios. To fill in this gap, we propose the code explanation generation task. We first conducted a human study to identify the criteria for high-quality explanatory docstring for code. Based on that, we collected and refined a large-scale code docstring corpus and formulated automatic evaluation metrics that best match human assessments. Finally, we present a multi-stage fine-tuning strategy and baseline models for the task. Our experiments show that (1) our refined training dataset lets models achieve better performance in the explanation generation tasks compared to larger unrefined data (15x larger), and (2) fine-tuned models can generate well-structured long docstrings comparable to human-written ones. We envision our training dataset, human-evaluation protocol, recommended metrics, and fine-tuning strategy can boost future code explanation research. The code and annotated data are available at https://github.com/subercui/CodeExp.
Execution-based Evaluation for Data Science Code Generation Models
Nov 17, 2022
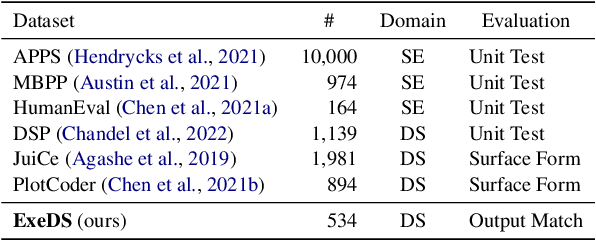
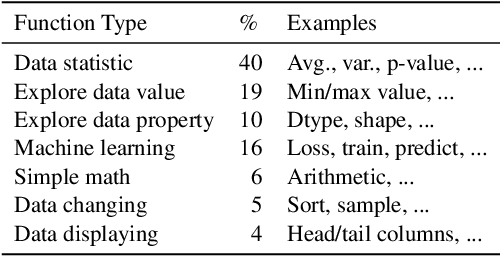
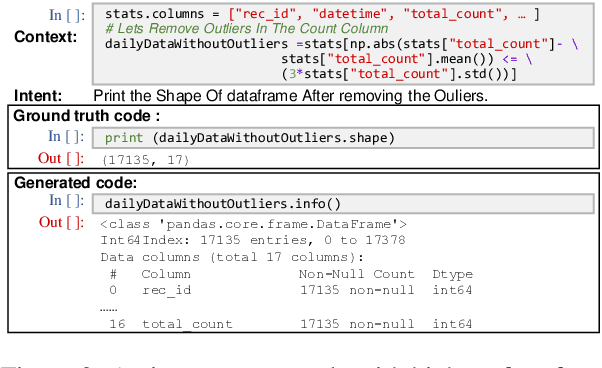
Code generation models can benefit data scientists' productivity by automatically generating code from context and text descriptions. An important measure of the modeling progress is whether a model can generate code that can correctly execute to solve the task. However, due to the lack of an evaluation dataset that directly supports execution-based model evaluation, existing work relies on code surface form similarity metrics (e.g., BLEU, CodeBLEU) for model selection, which can be inaccurate. To remedy this, we introduce ExeDS, an evaluation dataset for execution evaluation for data science code generation tasks. ExeDS contains a set of 534 problems from Jupyter Notebooks, each consisting of code context, task description, reference program, and the desired execution output. With ExeDS, we evaluate the execution performance of five state-of-the-art code generation models that have achieved high surface-form evaluation scores. Our experiments show that models with high surface-form scores do not necessarily perform well on execution metrics, and execution-based metrics can better capture model code generation errors. Source code and data can be found at https://github.com/Jun-jie-Huang/ExeDS
Learning Global and Local Consistent Representations for Unsupervised Image Retrieval via Deep Graph Diffusion Networks
Jan 05, 2020
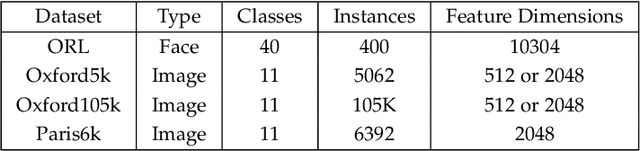


Diffusion has shown great success in improving accuracy of unsupervised image retrieval systems by utilizing high-order structures of image manifold. However, existing diffusion methods suffer from three major limitations: 1) they usually rely on local structures without considering global manifold information; 2) they focus on improving pair-wise similarities within existing images input output transductively while lacking flexibility to learn representations for novel unseen instances inductively; 3) they fail to scale to large datasets due to prohibitive memory consumption and computational burden due to intrinsic high-order operations on the whole graph. In this paper, to address these limitations, we propose a novel method,Graph Diffusion Networks (GRAD-Net), that adopts graph neural networks (GNNs), a novel variant of deep learning algorithms on irregular graphs. GRAD-Net learns semantic representations by exploiting both local and global structures of image manifold in an unsupervised fashion. By utilizing sparse coding techniques, GRAD-Net not only preserves global information on the image manifold, but also enables scalable training and efficient querying. Experiments on several large benchmark datasets demonstrate effectiveness of our method over state-of-the-art diffusion algorithms for unsupervised image retrieval.
Object-oriented Neural Programming (OONP) for Document Understanding
Jul 25, 2018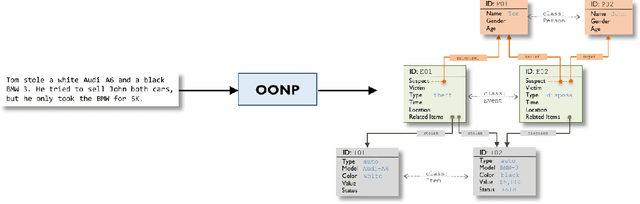

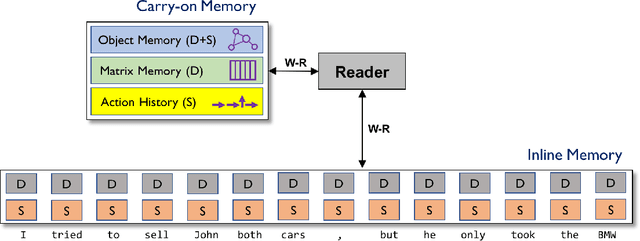

We propose Object-oriented Neural Programming (OONP), a framework for semantically parsing documents in specific domains. Basically, OONP reads a document and parses it into a predesigned object-oriented data structure (referred to as ontology in this paper) that reflects the domain-specific semantics of the document. An OONP parser models semantic parsing as a decision process: a neural net-based Reader sequentially goes through the document, and during the process it builds and updates an intermediate ontology to summarize its partial understanding of the text it covers. OONP supports a rich family of operations (both symbolic and differentiable) for composing the ontology, and a big variety of forms (both symbolic and differentiable) for representing the state and the document. An OONP parser can be trained with supervision of different forms and strength, including supervised learning (SL) , reinforcement learning (RL) and hybrid of the two. Our experiments on both synthetic and real-world document parsing tasks have shown that OONP can learn to handle fairly complicated ontology with training data of modest sizes.
JUMPER: Learning When to Make Classification Decisions in Reading
Jul 06, 2018
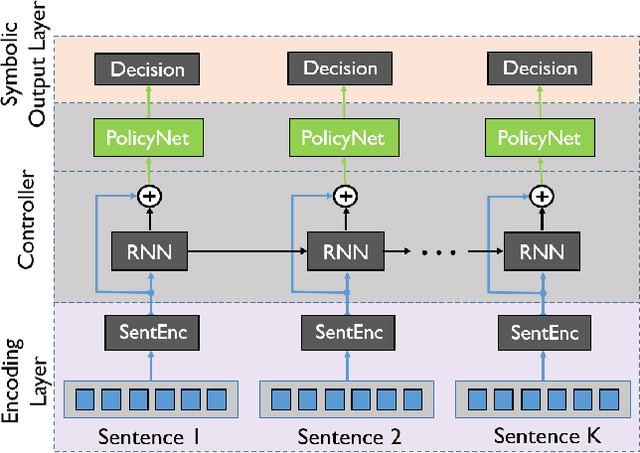
In early years, text classification is typically accomplished by feature-based machine learning models; recently, deep neural networks, as a powerful learning machine, make it possible to work with raw input as the text stands. However, exiting end-to-end neural networks lack explicit interpretation of the prediction. In this paper, we propose a novel framework, JUMPER, inspired by the cognitive process of text reading, that models text classification as a sequential decision process. Basically, JUMPER is a neural system that scans a piece of text sequentially and makes classification decisions at the time it wishes. Both the classification result and when to make the classification are part of the decision process, which is controlled by a policy network and trained with reinforcement learning. Experimental results show that a properly trained JUMPER has the following properties: (1) It can make decisions whenever the evidence is enough, therefore reducing total text reading by 30-40% and often finding the key rationale of prediction. (2) It achieves classification accuracy better than or comparable to state-of-the-art models in several benchmark and industrial datasets.
Deep-learning Based Modeling of Fault Detachment Stability for Power Grid
May 17, 2018The project intends to model the stability of power system with a deep learning algorithm to the problem, aiming to delay the removal of the fault. The so-called "fail-delay cut-off" refers to the occurrence of N-1 backup protection action on the backbone network of the system, resulting in longer time for the removal of the fault. In practice, through the analysis and calculation of a large number of online data, we have found that the N-1 failure system of the main protection action will not be unstable, which is also a guarantee of the operation mode arrangement. In the case of the N-1 backup protection action, there is an approximately 2.5% probability that the system will be destabilized. Therefore, research is needed to improve the operating arrangement.