 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Global and Local Consistent Representations for Unsupervised Image Retrieval via Deep Graph Diffusion Networks
Jan 05, 2020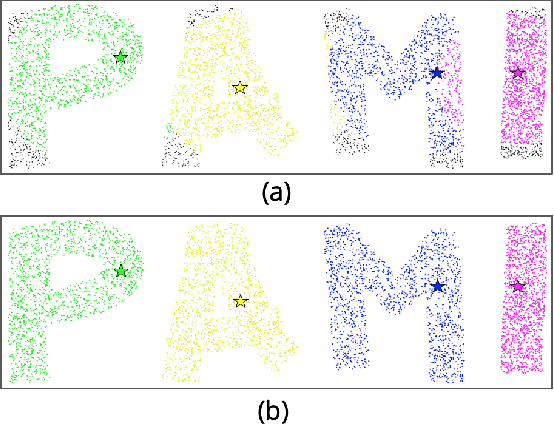
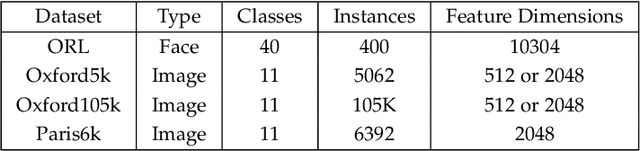


Diffusion has shown great success in improving accuracy of unsupervised image retrieval systems by utilizing high-order structures of image manifold. However, existing diffusion methods suffer from three major limitations: 1) they usually rely on local structures without considering global manifold information; 2) they focus on improving pair-wise similarities within existing images input output transductively while lacking flexibility to learn representations for novel unseen instances inductively; 3) they fail to scale to large datasets due to prohibitive memory consumption and computational burden due to intrinsic high-order operations on the whole graph. In this paper, to address these limitations, we propose a novel method,Graph Diffusion Networks (GRAD-Net), that adopts graph neural networks (GNNs), a novel variant of deep learning algorithms on irregular graphs. GRAD-Net learns semantic representations by exploiting both local and global structures of image manifold in an unsupervised fashion. By utilizing sparse coding techniques, GRAD-Net not only preserves global information on the image manifold, but also enables scalable training and efficient querying. Experiments on several large benchmark datasets demonstrate effectiveness of our method over state-of-the-art diffusion algorithms for unsupervised image retrieval.
Hard-Aware Point-to-Set Deep Metric for Person Re-identification
Jul 30, 2018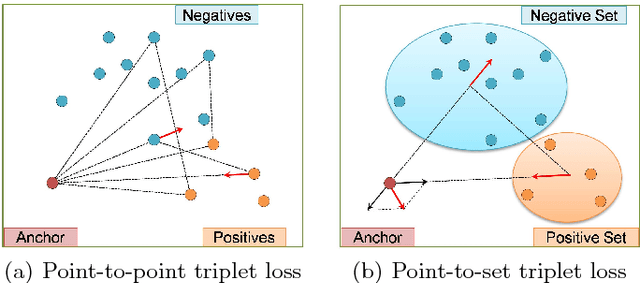
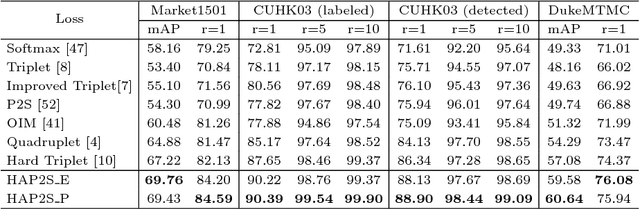
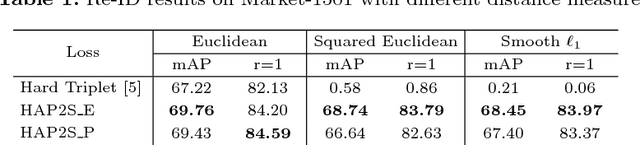
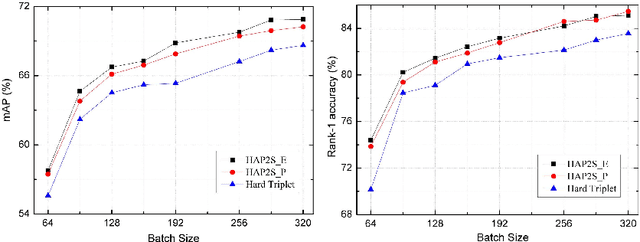
Person re-identification (re-ID) is a highly challenging task due to large variations of pose, viewpoint, illumination, and occlusion. Deep metric learning provides a satisfactory solution to person re-ID by training a deep network under supervision of metric loss, e.g., triplet loss. However, the performance of deep metric learning is greatly limited by traditional sampling methods. To solve this problem, we propose a Hard-Aware Point-to-Set (HAP2S) loss with a soft hard-mining scheme. Based on the point-to-set triplet loss framework, the HAP2S loss adaptively assigns greater weights to harder samples. Several advantageous properties are observed when compared with other state-of-the-art loss functions: 1) Accuracy: HAP2S loss consistently achieves higher re-ID accuracies than other alternatives on three large-scale benchmark datasets; 2) Robustness: HAP2S loss is more robust to outliers than other losses; 3) Flexibility: HAP2S loss does not rely on a specific weight function, i.e., different instantiations of HAP2S loss are equally effective. 4) Generality: In addition to person re-ID, we apply the proposed method to generic deep metric learning benchmarks including CUB-200-2011 and Cars196, and also achieve state-of-the-art results.
Deep-Person: Learning Discriminative Deep Features for Person Re-Identification
Jul 24, 2018
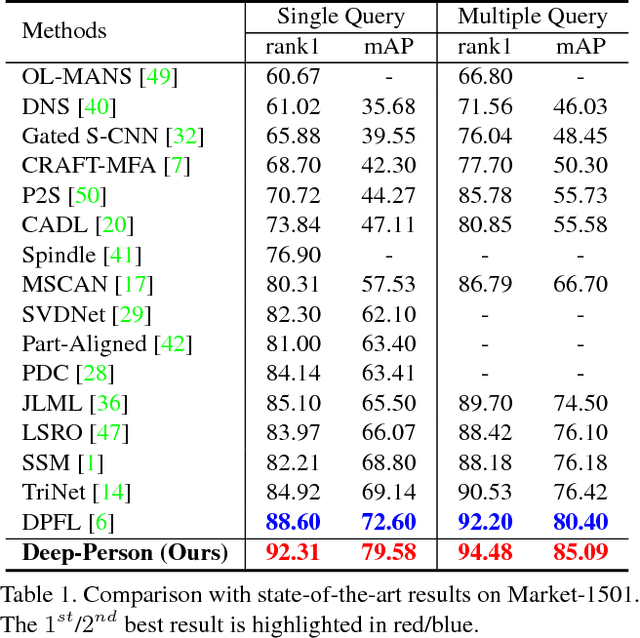

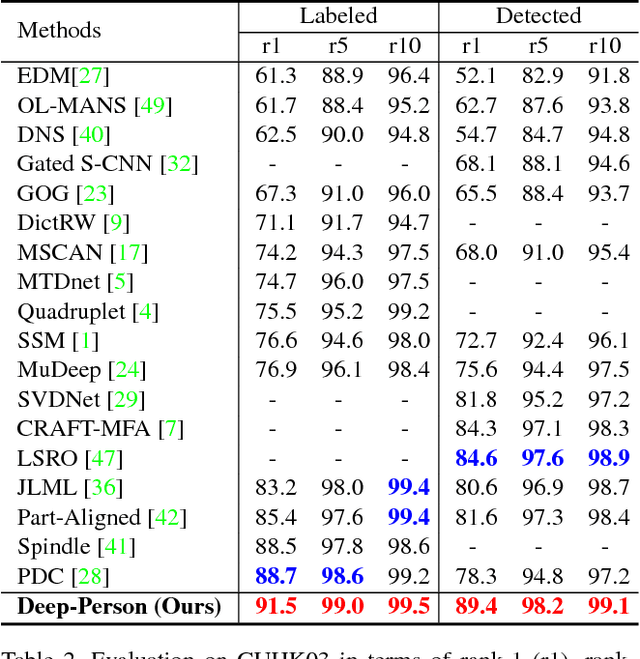
Recently, many methods of person re-identification (Re-ID) rely on part-based feature representation to learn a discriminative pedestrian descriptor. However, the spatial context between these parts is ignored for the independent extractor to each separate part. In this paper, we propose to apply Long Short-Term Memory (LSTM) in an end-to-end way to model the pedestrian, seen as a sequence of body parts from head to foot. Integrating the contextual information strengthens the discriminative ability of local representation. We also leverage the complementary information between local and global feature. Furthermore, we integrate both identification task and ranking task in one network, where a discriminative embedding and a similarity measurement are learned concurrently. This results in a novel three-branch framework named Deep-Person, which learns highly discriminative features for person Re-ID. Experimental results demonstrate that Deep-Person outperforms the state-of-the-art methods by a large margin on three challenging datasets including Market-1501, CUHK03, and DukeMTMC-reID. Specifically, combining with a re-ranking approach, we achieve a 90.84% mAP on Market-1501 under single query setting.