 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling, Analysis and Activation of Planar Viscoelastically-combined Rimless Wheels
Apr 13, 2026This paper proposes novel passive-dynamic walkers formed by two cross-shaped frames and eight viscoelastic elements. Since it is a combination of two four-legged rimless wheels via viscoelastic elements, we call it viscoelastically-combined rimless wheel (VCRW). Two types of VCRWs consisting of different cross-shaped frames are introduced; one is formed by combining two Greek-cross-shaped frames (VCRW1), and the other is formed by combining two-link cross-shaped frames that can rotate freely around the central axis (VCRW2). First, we describe the model assumptions and equations of motion and collision. Second, we numerically analyze the basic gait properties of passive dynamic walking. Furthermore, we consider an activation of VCRW2 for generating a stable level gait, and discuss the significance of the study as a novel walking support device.
* This is a corrected version of the IROS 2022 paper. A typographical error in Eq. (14) has been corrected
A High-frequency Pneumatic Oscillator for Soft Robotics
Nov 12, 2024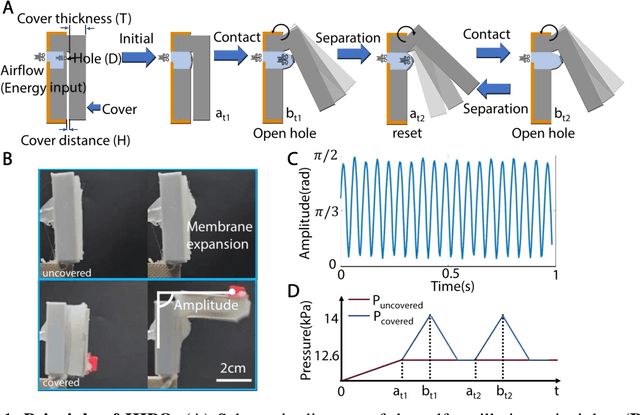
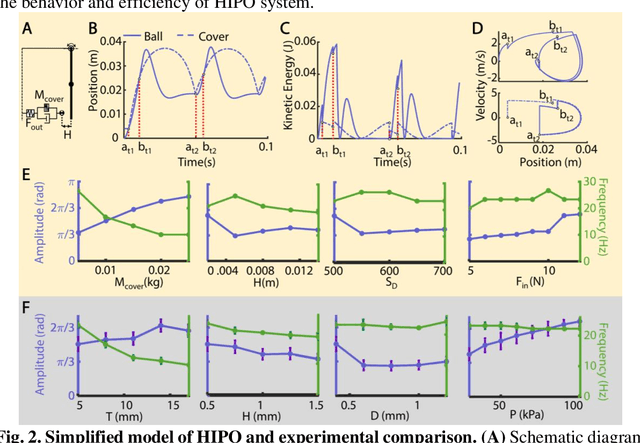
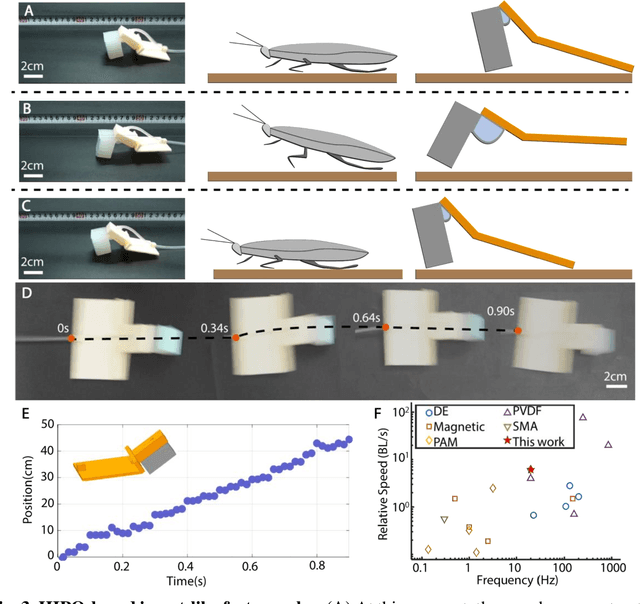
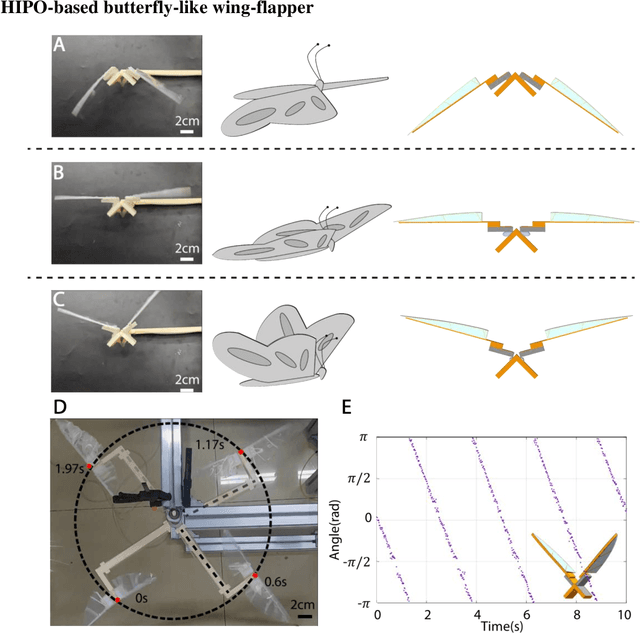
Soft robots, while highly adaptable to diverse environments through various actuation methods, still face significant performance boundary due to the inherent properties of materials. These limitations manifest in the challenge of guaranteeing rapid response and large-scale movements simultaneously, ultimately restricting the robots' absolute speed and overall efficiency. In this paper, we introduce a high-frequency pneumatic oscillator (HIPO) to overcome these challenges. Through a collision-induced phase resetting mechanism, our HIPO leverages event-based nonlinearity to trigger self-oscillation of pneumatic actuator, which positively utilizes intrinsic characteristics of materials. This enables the system to spontaneously generate periodic control signals and directly produce motion responses, eliminating the need for incorporating external actuation components. By efficiently and rapidly converting internal energy of airflow into the kinetic energy of robots, HIPO achieves a frequency of up to 20 Hz. Furthermore, we demonstrate the versatility and high-performance capabilities of HIPO through bio-inspired robots: an insect-like fast-crawler (with speeds up to 50.27 cm/s), a high-frequency butterfly-like wing-flapper, and a maneuverable duck-like swimmer. By eliminating external components and seamlessly fusing signal generation, energy conversion, and motion output, HIPO unleashes rapid and efficient motion, unlocking potential for high-performance soft robotics.
LLM-Vectorizer: LLM-based Verified Loop Vectorizer
Jun 07, 2024



Vectorization is a powerful optimization technique that significantly boosts the performance of high performance computing applications operating on large data arrays. Despite decades of research on auto-vectorization, compilers frequently miss opportunities to vectorize code. On the other hand, writing vectorized code manually using compiler intrinsics is still a complex, error-prone task that demands deep knowledge of specific architecture and compilers. In this paper, we evaluate the potential of large-language models (LLMs) to generate vectorized (Single Instruction Multiple Data) code from scalar programs that process individual array elements. We propose a novel finite-state machine multi-agents based approach that harnesses LLMs and test-based feedback to generate vectorized code. Our findings indicate that LLMs are capable of producing high performance vectorized code with run-time speedup ranging from 1.1x to 9.4x as compared to the state-of-the-art compilers such as Intel Compiler, GCC, and Clang. To verify the correctness of vectorized code, we use Alive2, a leading bounded translation validation tool for LLVM IR. We describe a few domain-specific techniques to improve the scalability of Alive2 on our benchmark dataset. Overall, our approach is able to verify 38.2% of vectorizations as correct on the TSVC benchmark dataset.
Auto-Tables: Synthesizing Multi-Step Transformations to Relationalize Tables without Using Examples
Aug 09, 2023Relational tables, where each row corresponds to an entity and each column corresponds to an attribute, have been the standard for tables in relational databases. However, such a standard cannot be taken for granted when dealing with tables "in the wild". Our survey of real spreadsheet-tables and web-tables shows that over 30% of such tables do not conform to the relational standard, for which complex table-restructuring transformations are needed before these tables can be queried easily using SQL-based analytics tools. Unfortunately, the required transformations are non-trivial to program, which has become a substantial pain point for technical and non-technical users alike, as evidenced by large numbers of forum questions in places like StackOverflow and Excel/Power-BI/Tableau forums. We develop an Auto-Tables system that can automatically synthesize pipelines with multi-step transformations (in Python or other languages), to transform non-relational tables into standard relational forms for downstream analytics, obviating the need for users to manually program transformations. We compile an extensive benchmark for this new task, by collecting 244 real test cases from user spreadsheets and online forums. Our evaluation suggests that Auto-Tables can successfully synthesize transformations for over 70% of test cases at interactive speeds, without requiring any input from users, making this an effective tool for both technical and non-technical users to prepare data for analytics.
Execution-based Evaluation for Data Science Code Generation Models
Nov 17, 2022
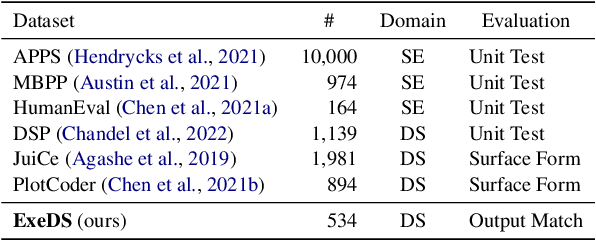
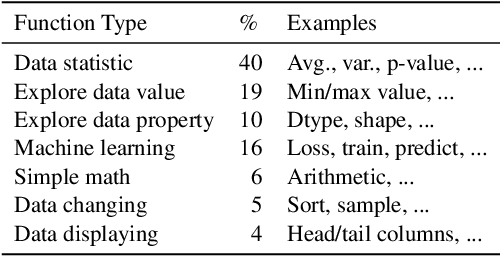
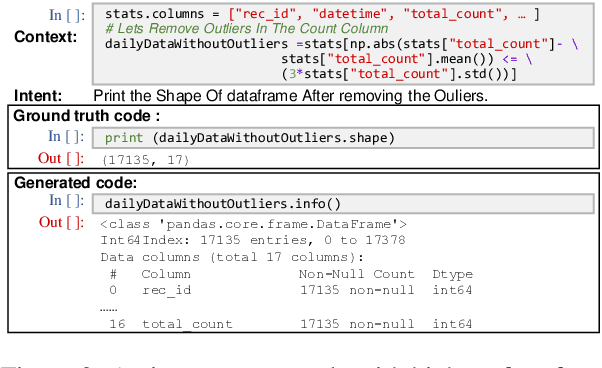
Code generation models can benefit data scientists' productivity by automatically generating code from context and text descriptions. An important measure of the modeling progress is whether a model can generate code that can correctly execute to solve the task. However, due to the lack of an evaluation dataset that directly supports execution-based model evaluation, existing work relies on code surface form similarity metrics (e.g., BLEU, CodeBLEU) for model selection, which can be inaccurate. To remedy this, we introduce ExeDS, an evaluation dataset for execution evaluation for data science code generation tasks. ExeDS contains a set of 534 problems from Jupyter Notebooks, each consisting of code context, task description, reference program, and the desired execution output. With ExeDS, we evaluate the execution performance of five state-of-the-art code generation models that have achieved high surface-form evaluation scores. Our experiments show that models with high surface-form scores do not necessarily perform well on execution metrics, and execution-based metrics can better capture model code generation errors. Source code and data can be found at https://github.com/Jun-jie-Huang/ExeDS