 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent Formalization: A Grand Challenge for Reliable Coding in the Age of AI Agents
Mar 17, 2026Agentic AI systems can now generate code with remarkable fluency, but a fundamental question remains: \emph{does the generated code actually do what the user intended?} The gap between informal natural language requirements and precise program behavior -- the \emph{intent gap} -- has always plagued software engineering, but AI-generated code amplifies it to an unprecedented scale. This article argues that \textbf{intent formalization} -- the translation of informal user intent into a set of checkable formal specifications -- is the key challenge that will determine whether AI makes software more reliable or merely more abundant. Intent formalization offers a tradeoff spectrum suitable to the reliability needs of different contexts: from lightweight tests that disambiguate likely misinterpretations, through full functional specifications for formal verification, to domain-specific languages from which correct code is synthesized automatically. The central bottleneck is \emph{validating specifications}: since there is no oracle for specification correctness other than the user, we need semi-automated metrics that can assess specification quality with or without code, through lightweight user interaction and proxy artifacts such as tests. We survey early research that demonstrates the \emph{potential} of this approach: interactive test-driven formalization that improves program correctness, AI-generated postconditions that catch real-world bugs missed by prior methods, and end-to-end verified pipelines that produce provably correct code from informal specifications. We outline the open research challenges -- scaling beyond benchmarks, achieving compositionality over changes, metrics for validating specifications, handling rich logics, designing human-AI specification interactions -- that define a research agenda spanning AI, programming languages, formal methods, and human-computer interaction.
Evaluating LLM-driven User-Intent Formalization for Verification-Aware Languages
Jun 14, 2024Verification-aware programming languages such as Dafny and F* provide means to formally specify and prove properties of programs. Although the problem of checking an implementation against a specification can be defined mechanically, there is no algorithmic way of ensuring the correctness of the user-intent formalization for programs -- that a specification adheres to the user's intent behind the program. The intent or requirement is expressed informally in natural language and the specification is a formal artefact. The advent of large language models (LLMs) has made strides bridging the gap between informal intent and formal program implementations recently, driven in large parts due to benchmarks and automated metrics for evaluation. Recent work has proposed evaluating {\it user-intent formalization} problem for mainstream programming languages~\cite{endres-fse24}. However, such an approach does not readily extend to verification-aware languages that support rich specifications (containing quantifiers and ghost variables) that cannot be evaluated through dynamic execution. Previous work also required generating program mutants using LLMs to create the benchmark. We advocate an alternate approach of {\it symbolically testing specifications} to provide an intuitive metric for evaluating the quality of specifications for verification-aware languages. We demonstrate that our automated metric agrees closely with mostly GPT-4 generated and human-labeled dataset of roughly 150 Dafny specifications for the popular MBPP code-generation benchmark, yet demonstrates cases where the human labeling is not perfect. We believe our work provides a stepping stone to enable the establishment of a benchmark and research agenda for the problem of user-intent formalization for programs.
LLM-Vectorizer: LLM-based Verified Loop Vectorizer
Jun 07, 2024



Vectorization is a powerful optimization technique that significantly boosts the performance of high performance computing applications operating on large data arrays. Despite decades of research on auto-vectorization, compilers frequently miss opportunities to vectorize code. On the other hand, writing vectorized code manually using compiler intrinsics is still a complex, error-prone task that demands deep knowledge of specific architecture and compilers. In this paper, we evaluate the potential of large-language models (LLMs) to generate vectorized (Single Instruction Multiple Data) code from scalar programs that process individual array elements. We propose a novel finite-state machine multi-agents based approach that harnesses LLMs and test-based feedback to generate vectorized code. Our findings indicate that LLMs are capable of producing high performance vectorized code with run-time speedup ranging from 1.1x to 9.4x as compared to the state-of-the-art compilers such as Intel Compiler, GCC, and Clang. To verify the correctness of vectorized code, we use Alive2, a leading bounded translation validation tool for LLVM IR. We describe a few domain-specific techniques to improve the scalability of Alive2 on our benchmark dataset. Overall, our approach is able to verify 38.2% of vectorizations as correct on the TSVC benchmark dataset.
Finding Inductive Loop Invariants using Large Language Models
Nov 14, 2023Loop invariants are fundamental to reasoning about programs with loops. They establish properties about a given loop's behavior. When they additionally are inductive, they become useful for the task of formal verification that seeks to establish strong mathematical guarantees about program's runtime behavior. The inductiveness ensures that the invariants can be checked locally without consulting the entire program, thus are indispensable artifacts in a formal proof of correctness. Finding inductive loop invariants is an undecidable problem, and despite a long history of research towards practical solutions, it remains far from a solved problem. This paper investigates the capabilities of the Large Language Models (LLMs) in offering a new solution towards this old, yet important problem. To that end, we first curate a dataset of verification problems on programs with loops. Next, we design a prompt for exploiting LLMs, obtaining inductive loop invariants, that are checked for correctness using sound symbolic tools. Finally, we explore the effectiveness of using an efficient combination of a symbolic tool and an LLM on our dataset and compare it against a purely symbolic baseline. Our results demonstrate that LLMs can help improve the state-of-the-art in automated program verification.
Ranking LLM-Generated Loop Invariants for Program Verification
Oct 18, 2023Synthesizing inductive loop invariants is fundamental to automating program verification. In this work, we observe that Large Language Models (such as gpt-3.5 or gpt-4) are capable of synthesizing loop invariants for a class of programs in a 0-shot setting, yet require several samples to generate the correct invariants. This can lead to a large number of calls to a program verifier to establish an invariant. To address this issue, we propose a {\it re-ranking} approach for the generated results of LLMs. We have designed a ranker that can distinguish between correct inductive invariants and incorrect attempts based on the problem definition. The ranker is optimized as a contrastive ranker. Experimental results demonstrate that this re-ranking mechanism significantly improves the ranking of correct invariants among the generated candidates, leading to a notable reduction in the number of calls to a verifier.
Formalizing Natural Language Intent into Program Specifications via Large Language Models
Oct 03, 2023Informal natural language that describes code functionality, such as code comments or function documentation, may contain substantial information about a programs intent. However, there is typically no guarantee that a programs implementation and natural language documentation are aligned. In the case of a conflict, leveraging information in code-adjacent natural language has the potential to enhance fault localization, debugging, and code trustworthiness. In practice, however, this information is often underutilized due to the inherent ambiguity of natural language which makes natural language intent challenging to check programmatically. The "emergent abilities" of Large Language Models (LLMs) have the potential to facilitate the translation of natural language intent to programmatically checkable assertions. However, it is unclear if LLMs can correctly translate informal natural language specifications into formal specifications that match programmer intent. Additionally, it is unclear if such translation could be useful in practice. In this paper, we describe LLM4nl2post, the problem leveraging LLMs for transforming informal natural language to formal method postconditions, expressed as program assertions. We introduce and validate metrics to measure and compare different LLM4nl2post approaches, using the correctness and discriminative power of generated postconditions. We then perform qualitative and quantitative methods to assess the quality of LLM4nl2post postconditions, finding that they are generally correct and able to discriminate incorrect code. Finally, we find that LLM4nl2post via LLMs has the potential to be helpful in practice; specifications generated from natural language were able to catch 70 real-world historical bugs from Defects4J.
Guiding Language Models of Code with Global Context using Monitors
Jun 19, 2023
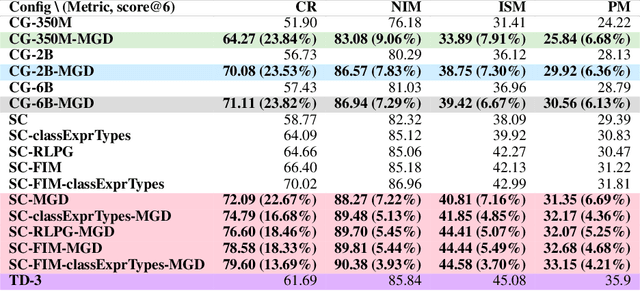
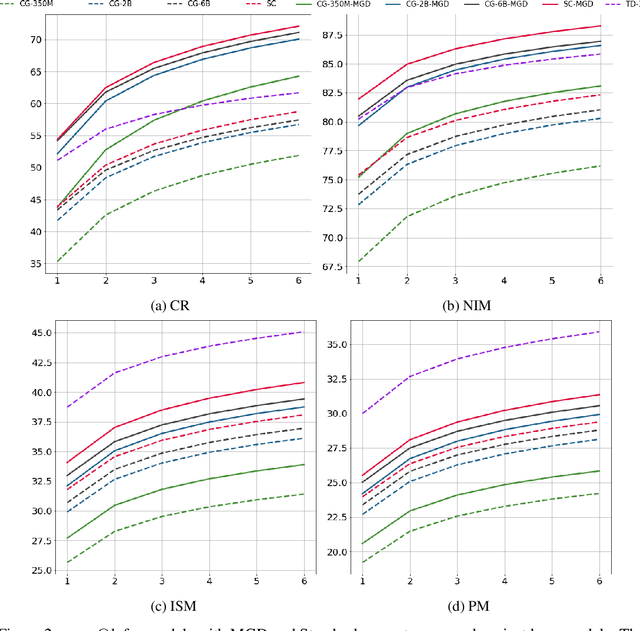
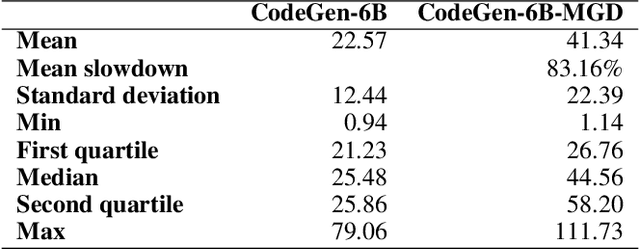
Language models of code (LMs) work well when the surrounding code in the vicinity of generation provides sufficient context. This is not true when it becomes necessary to use types or functionality defined in another module or library, especially those not seen during training. LMs suffer from limited awareness of such global context and end up hallucinating, e.g., using types defined in other files incorrectly. Recent work tries to overcome this issue by retrieving global information to augment the local context. However, this bloats the prompt or requires architecture modifications and additional training. Integrated development environments (IDEs) assist developers by bringing the global context at their fingertips using static analysis. We extend this assistance, enjoyed by developers, to the LMs. We propose a notion of monitors that use static analysis in the background to guide the decoding. Unlike a priori retrieval, static analysis is invoked iteratively during the entire decoding process, providing the most relevant suggestions on demand. We demonstrate the usefulness of our proposal by monitoring for type-consistent use of identifiers whenever an LM generates code for object dereference. To evaluate our approach, we curate PragmaticCode, a dataset of open-source projects with their development environments. On models of varying parameter scale, we show that monitor-guided decoding consistently improves the ability of an LM to not only generate identifiers that match the ground truth but also improves compilation rates and agreement with ground truth. We find that LMs with fewer parameters, when guided with our monitor, can outperform larger LMs. With monitor-guided decoding, SantaCoder-1.1B achieves better compilation rate and next-identifier match than the much larger text-davinci-003 model. The datasets and code will be released at https://aka.ms/monitors4codegen .
Towards Generating Functionally Correct Code Edits from Natural Language Issue Descriptions
Apr 07, 2023



Large language models (LLMs), such as OpenAI's Codex, have demonstrated their potential to generate code from natural language descriptions across a wide range of programming tasks. Several benchmarks have recently emerged to evaluate the ability of LLMs to generate functionally correct code from natural language intent with respect to a set of hidden test cases. This has enabled the research community to identify significant and reproducible advancements in LLM capabilities. However, there is currently a lack of benchmark datasets for assessing the ability of LLMs to generate functionally correct code edits based on natural language descriptions of intended changes. This paper aims to address this gap by motivating the problem NL2Fix of translating natural language descriptions of code changes (namely bug fixes described in Issue reports in repositories) into correct code fixes. To this end, we introduce Defects4J-NL2Fix, a dataset of 283 Java programs from the popular Defects4J dataset augmented with high-level descriptions of bug fixes, and empirically evaluate the performance of several state-of-the-art LLMs for the this task. Results show that these LLMS together are capable of generating plausible fixes for 64.6% of the bugs, and the best LLM-based technique can achieve up to 21.20% top-1 and 35.68% top-5 accuracy on this benchmark.
Interactive Code Generation via Test-Driven User-Intent Formalization
Aug 11, 2022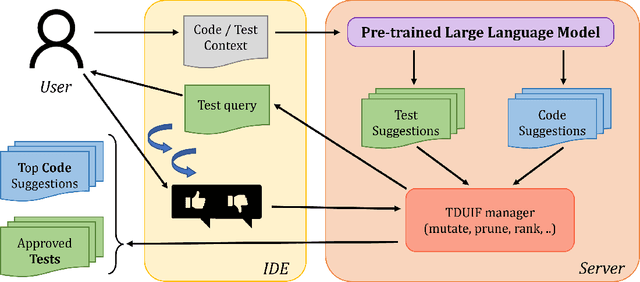



Pre-trained large language models (LLMs) such as OpenAI Codex have shown immense potential in automating significant aspects of coding by producing natural code from informal natural language (NL) intent. However, the code produced does not have any correctness guarantees around satisfying user's intent. In fact, it is hard to define a notion of correctness since natural language can be ambiguous and lacks a formal semantics. In this paper, we take a first step towards addressing the problem above by proposing the workflow of test-driven user-intent formalization (TDUIF), which leverages lightweight user feedback to jointly (a) formalize the user intent as tests (a partial specification), and (b) generates code that meets the formal user intent. To perform a scalable and large-scale automated evaluation of the algorithms without requiring a user in the loop, we describe how to simulate user interaction with high-fidelity using a reference solution. We also describe and implement alternate implementations of several algorithmic components (including mutating and ranking a set of tests) that can be composed for efficient solutions to the TDUIF problem. We have developed a system TICODER that implements several solutions to TDUIF, and compare their relative effectiveness on the MBPP academic code generation benchmark. Our results are promising with using the OpenAI Codex LLM on MBPP: our best algorithm improves the pass@1 code generation accuracy metric from 48.39% to 70.49% with a single user query, and up to 85.48% with up to 5 user queries. Second, we can generate a non-trivial functional unit test consistent with the user intent within an average of 1.69 user queries for 90.40% of the examples for this dataset.
Enabling Open-World Specification Mining via Unsupervised Learning
Apr 27, 2019


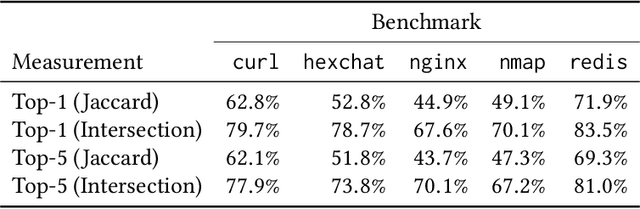
Many programming tasks require using both domain-specific code and well-established patterns (such as routines concerned with file IO). Together, several small patterns combine to create complex interactions. This compounding effect, mixed with domain-specific idiosyncrasies, creates a challenging environment for fully automatic specification inference. Mining specifications in this environment, without the aid of rule templates, user-directed feedback, or predefined API surfaces, is a major challenge. We call this challenge Open-World Specification Mining. In this paper, we present a framework for mining specifications and usage patterns in an Open-World setting. We design this framework to be miner-agnostic and instead focus on disentangling complex and noisy API interactions. To evaluate our framework, we introduce a benchmark of 71 clusters extracted from five open-source projects. Using this dataset, we show that interesting clusters can be recovered, in a fully automatic way, by leveraging unsupervised learning in the form of word embeddings. Once clusters have been recovered, the challenge of Open-World Specification Mining is simplified and any trace-based mining technique can be applied. In addition, we provide a comprehensive evaluation of three word-vector learners to showcase the value of sub-word information for embeddings learned in the software-engineering domain.