 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnterprise AI Must Enforce Participant-Aware Access Control
Sep 18, 2025Large language models (LLMs) are increasingly deployed in enterprise settings where they interact with multiple users and are trained or fine-tuned on sensitive internal data. While fine-tuning enhances performance by internalizing domain knowledge, it also introduces a critical security risk: leakage of confidential training data to unauthorized users. These risks are exacerbated when LLMs are combined with Retrieval-Augmented Generation (RAG) pipelines that dynamically fetch contextual documents at inference time. We demonstrate data exfiltration attacks on AI assistants where adversaries can exploit current fine-tuning and RAG architectures to leak sensitive information by leveraging the lack of access control enforcement. We show that existing defenses, including prompt sanitization, output filtering, system isolation, and training-level privacy mechanisms, are fundamentally probabilistic and fail to offer robust protection against such attacks. We take the position that only a deterministic and rigorous enforcement of fine-grained access control during both fine-tuning and RAG-based inference can reliably prevent the leakage of sensitive data to unauthorized recipients. We introduce a framework centered on the principle that any content used in training, retrieval, or generation by an LLM is explicitly authorized for \emph{all users involved in the interaction}. Our approach offers a simple yet powerful paradigm shift for building secure multi-user LLM systems that are grounded in classical access control but adapted to the unique challenges of modern AI workflows. Our solution has been deployed in Microsoft Copilot Tuning, a product offering that enables organizations to fine-tune models using their own enterprise-specific data.
RE-IMAGINE: Symbolic Benchmark Synthesis for Reasoning Evaluation
Jun 18, 2025Recent Large Language Models (LLMs) have reported high accuracy on reasoning benchmarks. However, it is still unclear whether the observed results arise from true reasoning or from statistical recall of the training set. Inspired by the ladder of causation (Pearl, 2009) and its three levels (associations, interventions and counterfactuals), this paper introduces RE-IMAGINE, a framework to characterize a hierarchy of reasoning ability in LLMs, alongside an automated pipeline to generate problem variations at different levels of the hierarchy. By altering problems in an intermediate symbolic representation, RE-IMAGINE generates arbitrarily many problems that are not solvable using memorization alone. Moreover, the framework is general and can work across reasoning domains, including math, code, and logic. We demonstrate our framework on four widely-used benchmarks to evaluate several families of LLMs, and observe reductions in performance when the models are queried with problem variations. These assessments indicate a degree of reliance on statistical recall for past performance, and open the door to further research targeting skills across the reasoning hierarchy.
DeduCE: Deductive Consistency as a Framework to Evaluate LLM Reasoning
Apr 09, 2025Despite great performance on Olympiad-level reasoning problems, frontier large language models can still struggle on high school math when presented with novel problems outside standard benchmarks. Going beyond final accuracy, we propose a deductive consistency metric to analyze chain-of-thought output from language models (LMs).Formally, deductive reasoning involves two subtasks: understanding a set of input premises and inferring the conclusions that follow from them. The proposed metric studies LMs' performance on these subtasks, with the goal of explaining LMs' reasoning errors on novel problems: how well do LMs understand input premises with increasing context lengths, and how well can they infer conclusions over multiple reasoning hops? Since existing benchmarks may be memorized, we develop a pipeline to evaluate LMs' deductive consistency on novel, perturbed versions of benchmark problems. On novel grade school math problems (GSM-8k), we find that LMs are fairly robust to increasing number of input premises, but suffer significant accuracy decay as the number of reasoning hops is increased. Interestingly, these errors are masked in the original benchmark as all models achieve near 100% accuracy. As we increase the number of solution steps using a synthetic dataset, prediction over multiple hops still remains the major source of error compared to understanding input premises. Other factors, such as shifts in language style or natural propagation of early errors do not explain the trends. Our analysis provides a new view to characterize LM reasoning -- as computations over a window of input premises and reasoning hops -- that can provide unified evaluation across problem domains.
A Prototype Model of Zero-Trust Architecture Blockchain with EigenTrust-Based Practical Byzantine Fault Tolerance Protocol to Manage Decentralized Clinical Trials
Aug 29, 2024The COVID-19 pandemic necessitated the emergence of decentralized Clinical Trials (DCTs) due to patient retention, accelerate trials, improve data accessibility, enable virtual care, and facilitate seamless communication through integrated systems. However, integrating systems in DCTs exposes clinical data to potential security threats, making them susceptible to theft at any stage, a high risk of protocol deviations, and monitoring issues. To mitigate these challenges, blockchain technology serves as a secure framework, acting as a decentralized ledger, creating an immutable environment by establishing a zero-trust architecture, where data are deemed untrusted until verified. In combination with Internet of Things (IoT)-enabled wearable devices, blockchain secures the transfer of clinical trial data on private blockchains during DCT automation and operations. This paper proposes a prototype model of the Zero-Trust Architecture Blockchain (z-TAB) to integrate patient-generated clinical trial data during DCT operation management. The EigenTrust-based Practical Byzantine Fault Tolerance (T-PBFT) algorithm has been incorporated as a consensus protocol, leveraging Hyperledger Fabric. Furthermore, the Internet of Things (IoT) has been integrated to streamline data processing among stakeholders within the blockchain platforms. Rigorous evaluation has been done to evaluate the quality of the system.
Physics-Informed Machine Learning for Smart Additive Manufacturing
Jul 15, 2024Compared to physics-based computational manufacturing, data-driven models such as machine learning (ML) are alternative approaches to achieve smart manufacturing. However, the data-driven ML's "black box" nature has presented a challenge to interpreting its outcomes. On the other hand, governing physical laws are not effectively utilized to develop data-efficient ML algorithms. To leverage the advantages of ML and physical laws of advanced manufacturing, this paper focuses on the development of a physics-informed machine learning (PIML) model by integrating neural networks and physical laws to improve model accuracy, transparency, and generalization with case studies in laser metal deposition (LMD).
Decoding Cognitive Health Using Machine Learning: A Comprehensive Evaluation for Diagnosis of Significant Memory Concern
May 11, 2024The timely identification of significant memory concern (SMC) is crucial for proactive cognitive health management, especially in an aging population. Detecting SMC early enables timely intervention and personalized care, potentially slowing cognitive disorder progression. This study presents a state-of-the-art review followed by a comprehensive evaluation of machine learning models within the randomized neural networks (RNNs) and hyperplane-based classifiers (HbCs) family to investigate SMC diagnosis thoroughly. Utilizing the Alzheimer's Disease Neuroimaging Initiative 2 (ADNI2) dataset, 111 individuals with SMC and 111 healthy older adults are analyzed based on T1W magnetic resonance imaging (MRI) scans, extracting rich features. This analysis is based on baseline structural MRI (sMRI) scans, extracting rich features from gray matter (GM), white matter (WM), Jacobian determinant (JD), and cortical thickness (CT) measurements. In RNNs, deep random vector functional link (dRVFL) and ensemble dRVFL (edRVFL) emerge as the best classifiers in terms of performance metrics in the identification of SMC. In HbCs, Kernelized pinball general twin support vector machine (Pin-GTSVM-K) excels in CT and WM features, whereas Linear Pin-GTSVM (Pin-GTSVM-L) and Linear intuitionistic fuzzy TSVM (IFTSVM-L) performs well in the JD and GM features sets, respectively. This comprehensive evaluation emphasizes the critical role of feature selection and model choice in attaining an effective classifier for SMC diagnosis. The inclusion of statistical analyses further reinforces the credibility of the results, affirming the rigor of this analysis. The performance measures exhibit the suitability of this framework in aiding researchers with the automated and accurate assessment of SMC. The source codes of the algorithms and datasets used in this study are available at https://github.com/mtanveer1/SMC.
Private Benchmarking to Prevent Contamination and Improve Comparative Evaluation of LLMs
Mar 01, 2024Benchmarking is the de-facto standard for evaluating LLMs, due to its speed, replicability and low cost. However, recent work has pointed out that the majority of the open source benchmarks available today have been contaminated or leaked into LLMs, meaning that LLMs have access to test data during pretraining and/or fine-tuning. This raises serious concerns about the validity of benchmarking studies conducted so far and the future of evaluation using benchmarks. To solve this problem, we propose Private Benchmarking, a solution where test datasets are kept private and models are evaluated without revealing the test data to the model. We describe various scenarios (depending on the trust placed on model owners or dataset owners), and present solutions to avoid data contamination using private benchmarking. For scenarios where the model weights need to be kept private, we describe solutions from confidential computing and cryptography that can aid in private benchmarking. Finally, we present solutions the problem of benchmark dataset auditing, to ensure that private benchmarks are of sufficiently high quality.
Evaluating Atypical Gaze Patterns through Vision Models: The Case of Cortical Visual Impairment
Feb 15, 2024

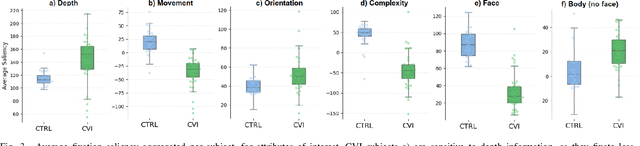
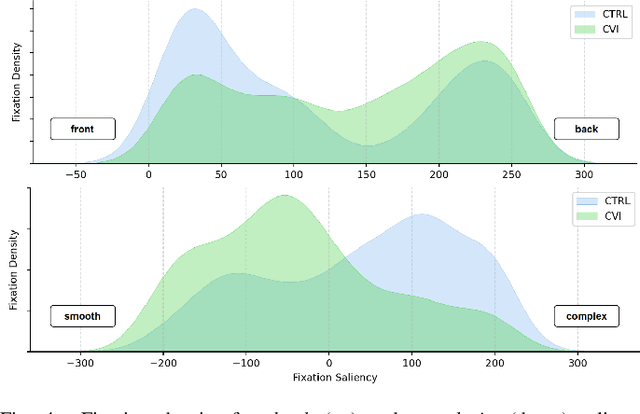
A wide range of neurological and cognitive disorders exhibit distinct behavioral markers aside from their clinical manifestations. Cortical Visual Impairment (CVI) is a prime example of such conditions, resulting from damage to visual pathways in the brain, and adversely impacting low- and high-level visual function. The characteristics impacted by CVI are primarily described qualitatively, challenging the establishment of an objective, evidence-based measure of CVI severity. To study those characteristics, we propose to create visual saliency maps by adequately prompting deep vision models with attributes of clinical interest. After extracting saliency maps for a curated set of stimuli, we evaluate fixation traces on those from children with CVI through eye tracking technology. Our experiments reveal significant gaze markers that verify clinical knowledge and yield nuanced discriminability when compared to those of age-matched control subjects. Using deep learning to unveil atypical visual saliency is an important step toward establishing an eye-tracking signature for severe neurodevelopmental disorders, like CVI.
X Hacking: The Threat of Misguided AutoML
Jan 16, 2024



Explainable AI (XAI) and interpretable machine learning methods help to build trust in model predictions and derived insights, yet also present a perverse incentive for analysts to manipulate XAI metrics to support pre-specified conclusions. This paper introduces the concept of X-hacking, a form of p-hacking applied to XAI metrics such as Shap values. We show how an automated machine learning pipeline can be used to search for 'defensible' models that produce a desired explanation while maintaining superior predictive performance to a common baseline. We formulate the trade-off between explanation and accuracy as a multi-objective optimization problem and illustrate the feasibility and severity of X-hacking empirically on familiar real-world datasets. Finally, we suggest possible methods for detection and prevention, and discuss ethical implications for the credibility and reproducibility of XAI research.
Finding Inductive Loop Invariants using Large Language Models
Nov 14, 2023Loop invariants are fundamental to reasoning about programs with loops. They establish properties about a given loop's behavior. When they additionally are inductive, they become useful for the task of formal verification that seeks to establish strong mathematical guarantees about program's runtime behavior. The inductiveness ensures that the invariants can be checked locally without consulting the entire program, thus are indispensable artifacts in a formal proof of correctness. Finding inductive loop invariants is an undecidable problem, and despite a long history of research towards practical solutions, it remains far from a solved problem. This paper investigates the capabilities of the Large Language Models (LLMs) in offering a new solution towards this old, yet important problem. To that end, we first curate a dataset of verification problems on programs with loops. Next, we design a prompt for exploiting LLMs, obtaining inductive loop invariants, that are checked for correctness using sound symbolic tools. Finally, we explore the effectiveness of using an efficient combination of a symbolic tool and an LLM on our dataset and compare it against a purely symbolic baseline. Our results demonstrate that LLMs can help improve the state-of-the-art in automated program verification.