 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeoptimize_anything: A Universal API for Optimizing any Text Parameter
May 19, 2026Can a single LLM-based optimization system match specialized tools across fundamentally different domains? We show that when optimization problems are formulated as improving a text artifact evaluated by a scoring function, a single AI-based optimization system-supporting single-task search, multi-task search with cross-problem transfer, and generalization to unseen inputs-achieves state-of-the-art results across six diverse tasks. Our system discovers agent architectures that nearly triple Gemini Flash's ARC-AGI accuracy (32.5% to 89.5%), finds scheduling algorithms that cut cloud costs by 40%, generates CUDA kernels where 87% match or beat PyTorch, and outperforms AlphaEvolve's reported circle packing solution (n=26). Ablations across three domains reveal that actionable side information yields faster convergence and substantially higher final scores than score-only feedback, and that multi-task search outperforms independent optimization given equivalent per-problem budget through cross-task transfer, with benefits scaling with the number of related tasks. Together, we show for the first time that text optimization with LLM-based search is a general-purpose problem-solving paradigm, unifying tasks traditionally requiring domain-specific algorithms under a single framework. We open-source optimize\_anything with support for multiple backends as part of the GEPA project at https://github.com/gepa-ai/gepa .
* 16 pages, 11 figures; Blog: https://gepa-ai.github.io/gepa/blog/2026/02/18/introducing-optimize-anything/
Learning, Fast and Slow: Towards LLMs That Adapt Continually
May 14, 2026Large language models (LLMs) are trained for downstream tasks by updating their parameters (e.g., via RL). However, updating parameters forces them to absorb task-specific information, which can result in catastrophic forgetting and loss of plasticity. In contrast, in-context learning with fixed LLM parameters can cheaply and rapidly adapt to task-specific requirements (e.g., prompt optimization), but cannot by itself typically match the performance gains available through updating LLM parameters. There is no good reason for restricting learning to being in-context or in-weights. Moreover, humans also likely learn at different time scales (e.g., System 1 vs 2). To this end, we introduce a fast-slow learning framework for LLMs, with model parameters as "slow" weights and optimized context as "fast" weights. These fast "weights" can learn from textual feedback to absorb the task-specific information, while allowing slow weights to stay closer to the base model and persist general reasoning behaviors. Fast-Slow Training (FST) is up to 3x more sample-efficient than only slow learning (RL) across reasoning tasks, while consistently reaching a higher performance asymptote. Moreover, FST-trained models remain closer to the base LLM (up to 70% less KL divergence), resulting in less catastrophic forgetting than RL-training. This reduced drift also preserves plasticity: after training on one task, FST trained models adapt more effectively to a subsequent task than parameter-only trained models. In continual learning scenarios, where task domains change on the fly, FST continues to acquire each new task while parameter-only RL stalls.
Combee: Scaling Prompt Learning for Self-Improving Language Model Agents
Apr 05, 2026Recent advances in prompt learning allow large language model agents to acquire task-relevant knowledge from inference-time context without parameter changes. For example, existing methods (like ACE or GEPA) can learn system prompts to improve accuracy based on previous agent runs. However, these methods primarily focus on single-agent or low-parallelism settings. This fundamentally limits their ability to efficiently learn from a large set of collected agentic traces. It would be efficient and beneficial to run prompt learning in parallel to accommodate the growing trend of learning from many agentic traces or parallel agent executions. Yet without a principled strategy for scaling, current methods suffer from quality degradation with high parallelism. To improve both the efficiency and quality of prompt learning, we propose Combee, a novel framework to scale parallel prompt learning for self-improving agents. Combee speeds up learning and enables running many agents in parallel while learning from their aggregate traces without quality degradation. To achieve this, Combee leverages parallel scans and employs an augmented shuffle mechanism; Combee also introduces a dynamic batch size controller to balance quality and delay. Evaluations on AppWorld, Terminal-Bench, Formula, and FiNER demonstrate that Combee achieves up to 17x speedup over previous methods with comparable or better accuracy and equivalent cost.
Multi-module GRPO: Composing Policy Gradients and Prompt Optimization for Language Model Programs
Aug 06, 2025Group Relative Policy Optimization (GRPO) has proven to be an effective tool for post-training language models (LMs). However, AI systems are increasingly expressed as modular programs that mix together multiple LM calls with distinct prompt templates and other tools, and it is not clear how best to leverage GRPO to improve these systems. We begin to address this challenge by defining mmGRPO, a simple multi-module generalization of GRPO that groups LM calls by module across rollouts and handles variable-length and interrupted trajectories. We find that mmGRPO, composed with automatic prompt optimization, improves accuracy by 11% on average across classification, many-hop search, and privacy-preserving delegation tasks against the post-trained LM, and by 5% against prompt optimization on its own. We open-source mmGRPO in DSPy as the dspy.GRPO optimizer.
LangProBe: a Language Programs Benchmark
Feb 27, 2025
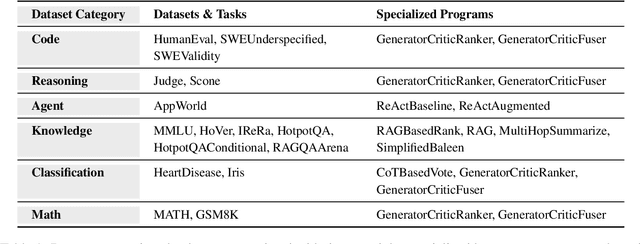
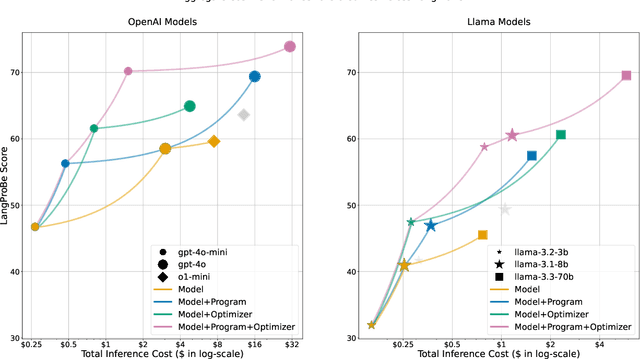
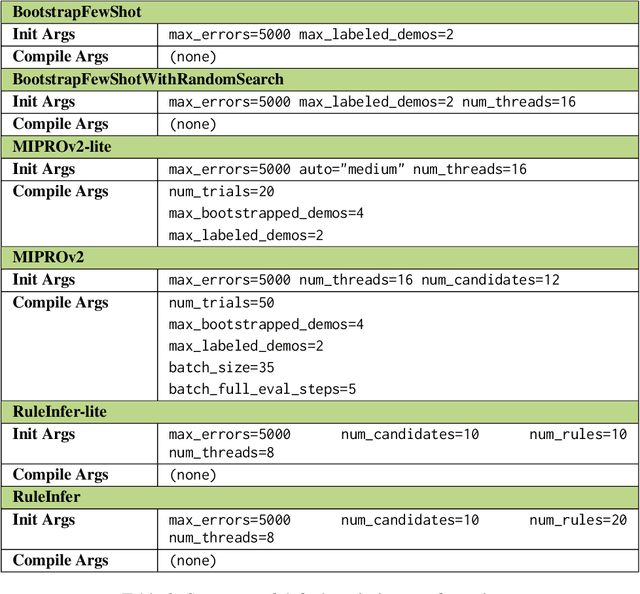
Composing language models (LMs) into multi-step language programs and automatically optimizing their modular prompts is now a mainstream paradigm for building AI systems, but the tradeoffs in this space have only scarcely been studied before. We introduce LangProBe, the first large-scale benchmark for evaluating the architectures and optimization strategies for language programs, with over 2000 combinations of tasks, architectures, optimizers, and choices of LMs. Using LangProBe, we are the first to study the impact of program architectures and optimizers (and their compositions together and with different models) on tradeoffs of quality and cost. We find that optimized language programs offer strong cost--quality Pareto improvement over raw calls to models, but simultaneously demonstrate that human judgment (or empirical decisions) about which compositions to pursue is still necessary for best performance. We will open source the code and evaluation data for LangProBe.
Guiding Language Models of Code with Global Context using Monitors
Jun 19, 2023
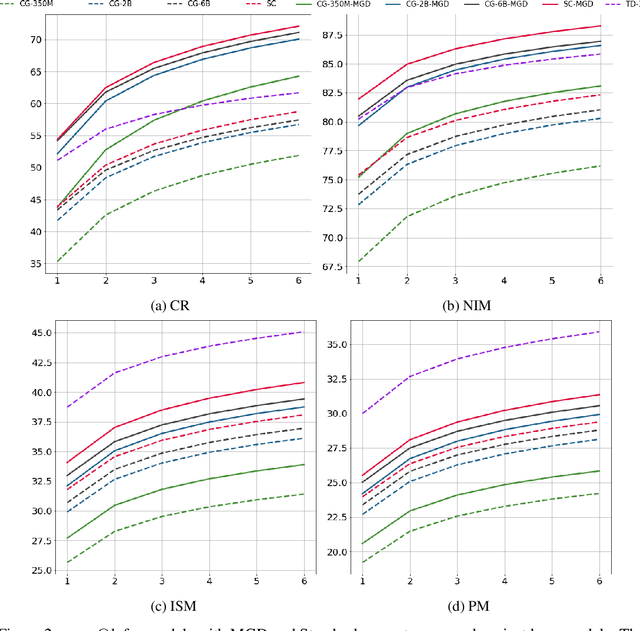
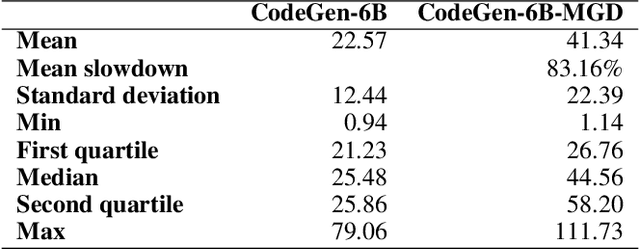
Language models of code (LMs) work well when the surrounding code in the vicinity of generation provides sufficient context. This is not true when it becomes necessary to use types or functionality defined in another module or library, especially those not seen during training. LMs suffer from limited awareness of such global context and end up hallucinating, e.g., using types defined in other files incorrectly. Recent work tries to overcome this issue by retrieving global information to augment the local context. However, this bloats the prompt or requires architecture modifications and additional training. Integrated development environments (IDEs) assist developers by bringing the global context at their fingertips using static analysis. We extend this assistance, enjoyed by developers, to the LMs. We propose a notion of monitors that use static analysis in the background to guide the decoding. Unlike a priori retrieval, static analysis is invoked iteratively during the entire decoding process, providing the most relevant suggestions on demand. We demonstrate the usefulness of our proposal by monitoring for type-consistent use of identifiers whenever an LM generates code for object dereference. To evaluate our approach, we curate PragmaticCode, a dataset of open-source projects with their development environments. On models of varying parameter scale, we show that monitor-guided decoding consistently improves the ability of an LM to not only generate identifiers that match the ground truth but also improves compilation rates and agreement with ground truth. We find that LMs with fewer parameters, when guided with our monitor, can outperform larger LMs. With monitor-guided decoding, SantaCoder-1.1B achieves better compilation rate and next-identifier match than the much larger text-davinci-003 model. The datasets and code will be released at https://aka.ms/monitors4codegen .
A Novel Sentiment Analysis Engine for Preliminary Depression Status Estimation on Social Media
Nov 29, 2020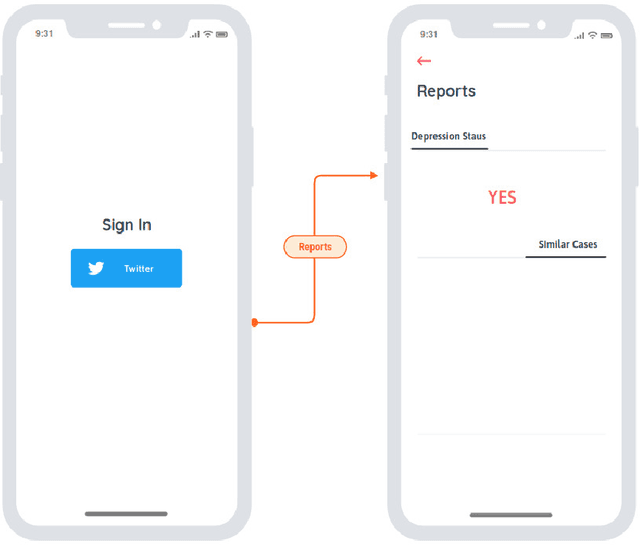
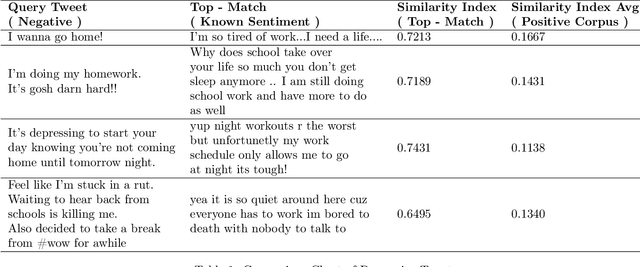
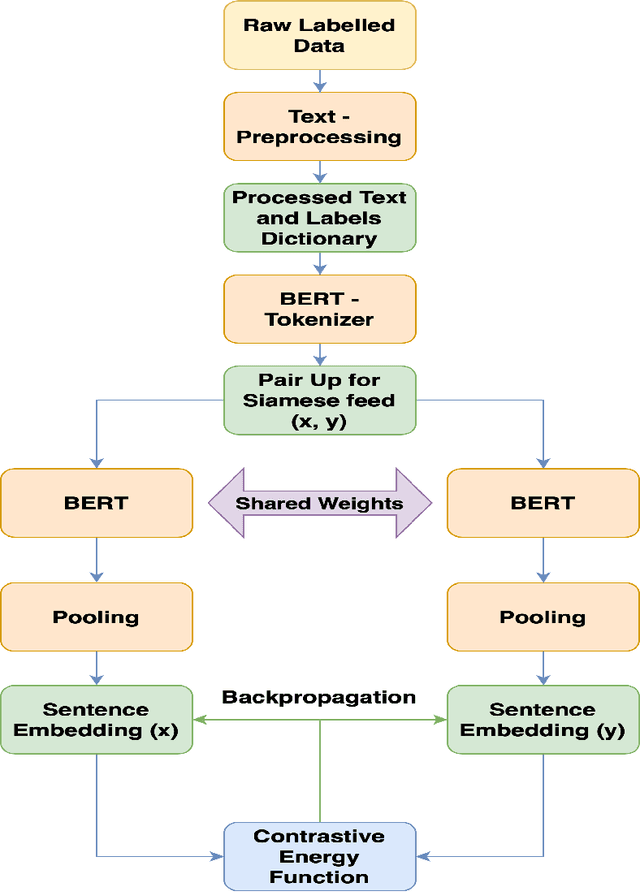
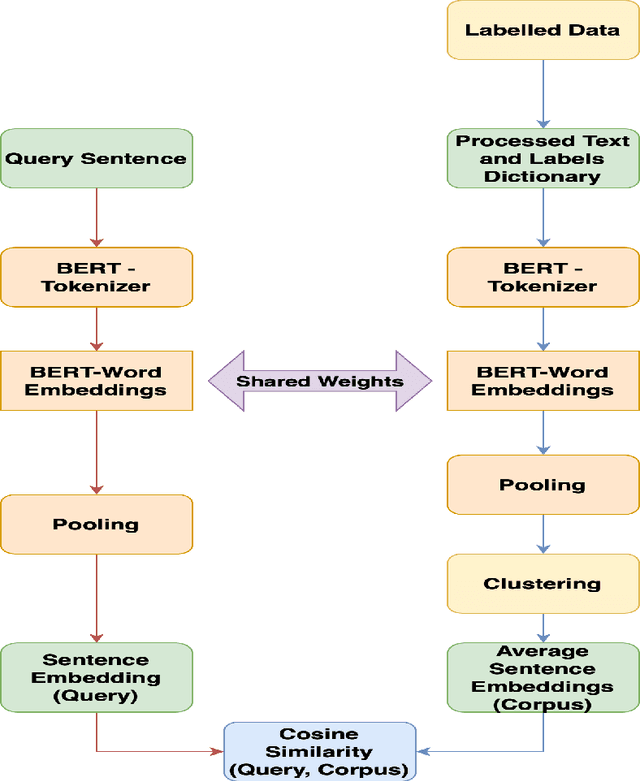
Text sentiment analysis for preliminary depression status estimation of users on social media is a widely exercised and feasible method, However, the immense variety of users accessing the social media websites and their ample mix of vocabularies makes it difficult for commonly applied deep learning-based classifiers to perform. To add to the situation, the lack of adaptability of traditional supervised machine learning could hurt at many levels. We propose a cloud-based smartphone application, with a deep learning-based backend to primarily perform depression detection on Twitter social media. The backend model consists of a RoBERTa based siamese sentence classifier that compares a given tweet (Query) with a labeled set of tweets with known sentiment ( Standard Corpus ). The standard corpus is varied over time with expert opinion so as to improve the model's reliability. A psychologist ( with the patient's permission ) could leverage the application to assess the patient's depression status prior to counseling, which provides better insight into the mental health status of a patient. In addition, to the same, the psychologist could be referred to cases of similar characteristics, which could in turn help in more effective treatment. We evaluate our backend model after fine-tuning it on a publicly available dataset. The find tuned model is made to predict depression on a large set of tweet samples with random noise factors. The model achieved pinnacle results, with a testing accuracy of 87.23% and an AUC of 0.8621.