 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Detection of Alzheimer's Disease from Speech and Text
Nov 30, 2020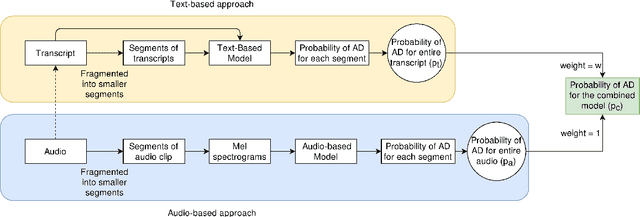
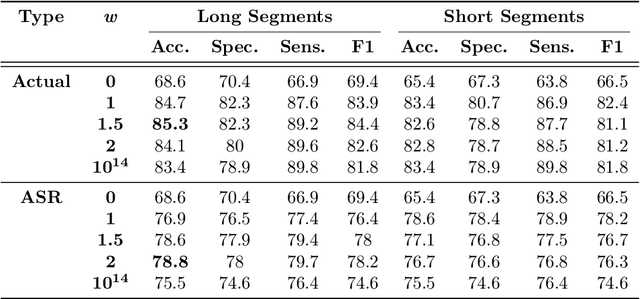
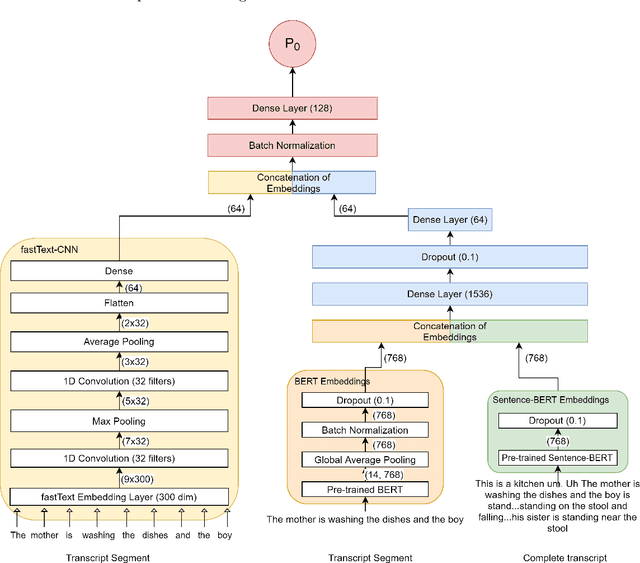
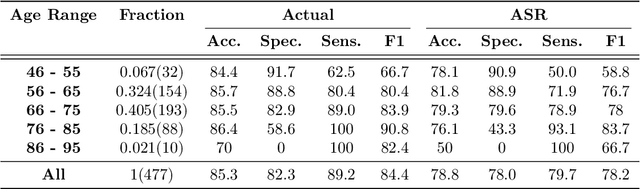
Reliable detection of the prodromal stages of Alzheimer's disease (AD) remains difficult even today because, unlike other neurocognitive impairments, there is no definitive diagnosis of AD in vivo. In this context, existing research has shown that patients often develop language impairment even in mild AD conditions. We propose a multimodal deep learning method that utilizes speech and the corresponding transcript simultaneously to detect AD. For audio signals, the proposed audio-based network, a convolutional neural network (CNN) based model, predicts the diagnosis for multiple speech segments, which are combined for the final prediction. Similarly, we use contextual embedding extracted from BERT concatenated with a CNN-generated embedding for classifying the transcript. The individual predictions of the two models are then combined to make the final classification. We also perform experiments to analyze the model performance when Automated Speech Recognition (ASR) system generated transcripts are used instead of manual transcription in the text-based model. The proposed method achieves 85.3% 10-fold cross-validation accuracy when trained and evaluated on the Dementiabank Pitt corpus.
Depression Status Estimation by Deep Learning based Hybrid Multi-Modal Fusion Model
Nov 30, 2020

Preliminary detection of mild depression could immensely help in effective treatment of the common mental health disorder. Due to the lack of proper awareness and the ample mix of stigmas and misconceptions present within the society, mental health status estimation has become a truly difficult task. Due to the immense variations in character level traits from person to person, traditional deep learning methods fail to generalize in a real world setting. In our study we aim to create a human allied AI workflow which could efficiently adapt to specific users and effectively perform in real world scenarios. We propose a Hybrid deep learning approach that combines the essence of one shot learning, classical supervised deep learning methods and human allied interactions for adaptation. In order to capture maximum information and make efficient diagnosis video, audio, and text modalities are utilized. Our Hybrid Fusion model achieved a high accuracy of 96.3% on the Dataset; and attained an AUC of 0.9682 which proves its robustness in discriminating classes in complex real-world scenarios making sure that no cases of mild depression are missed during diagnosis. The proposed method is deployed in a cloud-based smartphone application for robust testing. With user-specific adaptations and state of the art methodologies, we present a state-of-the-art model with user friendly experience.
A smartphone based multi input workflow for non-invasive estimation of haemoglobin levels using machine learning techniques
Nov 29, 2020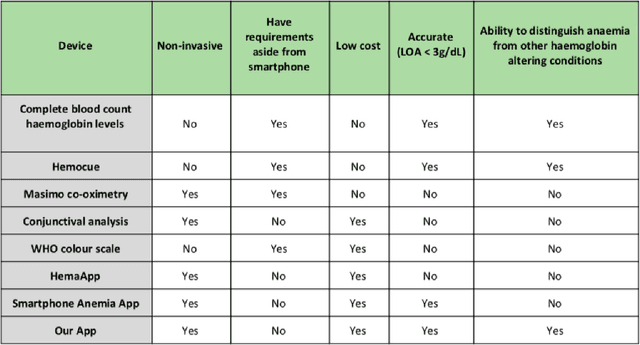
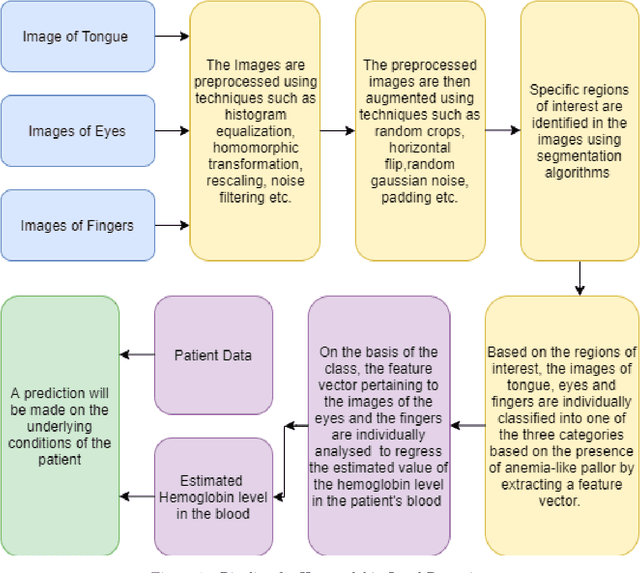
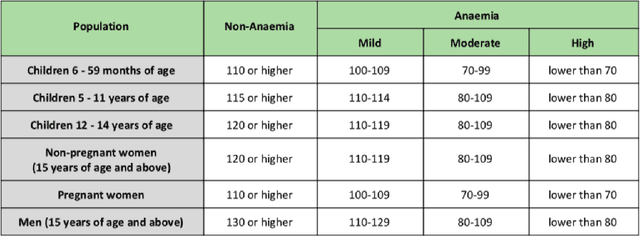
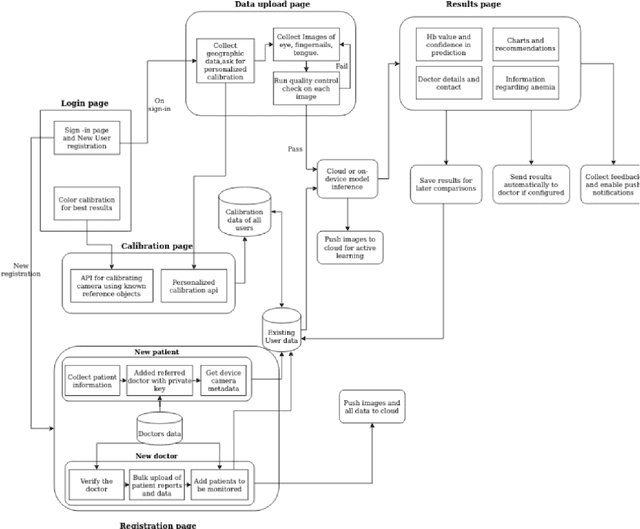
We suggest a low cost, non invasive healthcare system that measures haemoglobin levels in patients and can be used as a preliminary diagnostic test for anaemia. A combination of image processing, machine learning and deep learning techniques are employed to develop predictive models to measure haemoglobin levels. This is achieved through the color analysis of the fingernail beds, palpebral conjunctiva and tongue of the patients. This predictive model is then encapsulated in a healthcare application. This application expedites data collection and facilitates active learning of the model. It also incorporates personalized calibration of the model for each patient, assisting in the continual monitoring of the haemoglobin levels of the patient. Upon validating this framework using data, it can serve as a highly accurate preliminary diagnostic test for anaemia.
A Novel Sentiment Analysis Engine for Preliminary Depression Status Estimation on Social Media
Nov 29, 2020
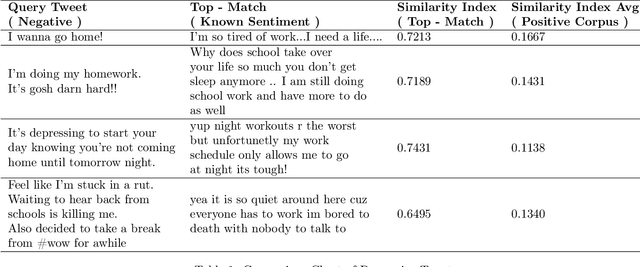
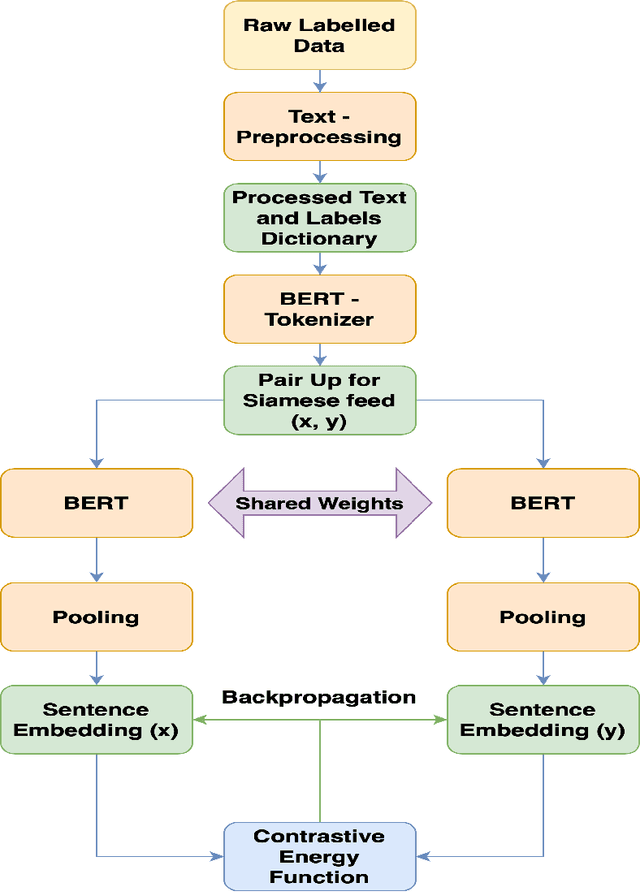
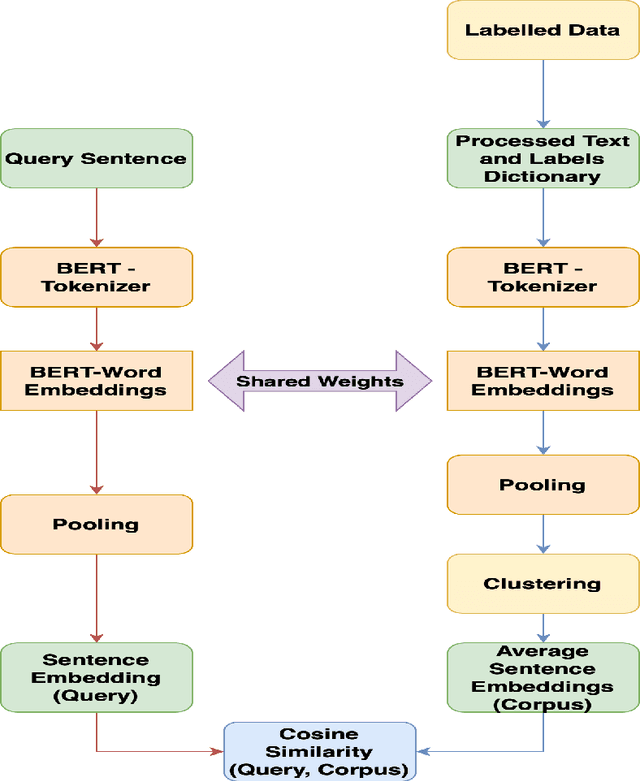
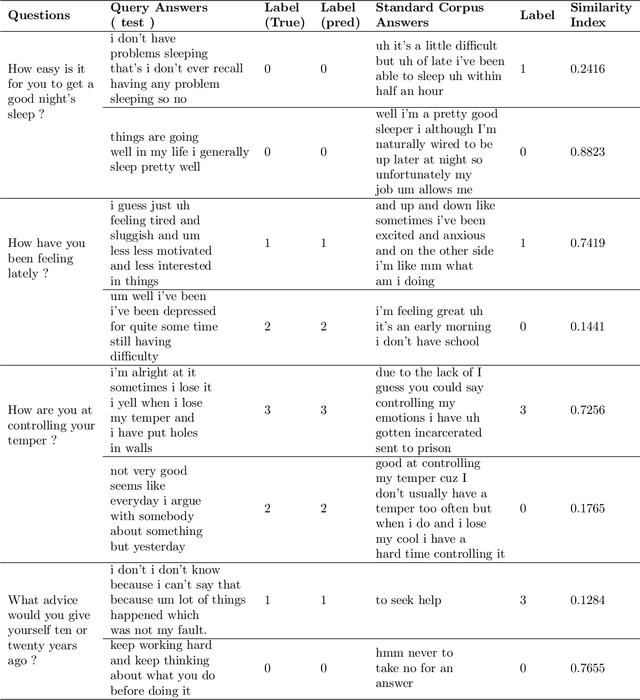
Text sentiment analysis for preliminary depression status estimation of users on social media is a widely exercised and feasible method, However, the immense variety of users accessing the social media websites and their ample mix of vocabularies makes it difficult for commonly applied deep learning-based classifiers to perform. To add to the situation, the lack of adaptability of traditional supervised machine learning could hurt at many levels. We propose a cloud-based smartphone application, with a deep learning-based backend to primarily perform depression detection on Twitter social media. The backend model consists of a RoBERTa based siamese sentence classifier that compares a given tweet (Query) with a labeled set of tweets with known sentiment ( Standard Corpus ). The standard corpus is varied over time with expert opinion so as to improve the model's reliability. A psychologist ( with the patient's permission ) could leverage the application to assess the patient's depression status prior to counseling, which provides better insight into the mental health status of a patient. In addition, to the same, the psychologist could be referred to cases of similar characteristics, which could in turn help in more effective treatment. We evaluate our backend model after fine-tuning it on a publicly available dataset. The find tuned model is made to predict depression on a large set of tweet samples with random noise factors. The model achieved pinnacle results, with a testing accuracy of 87.23% and an AUC of 0.8621.
A Data-Efficient Deep Learning Based Smartphone Application For Detection Of Pulmonary Diseases Using Chest X-rays
Aug 19, 2020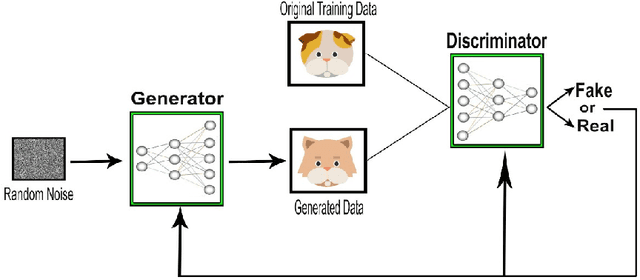
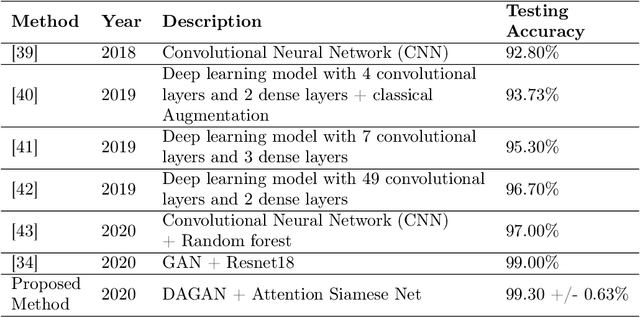
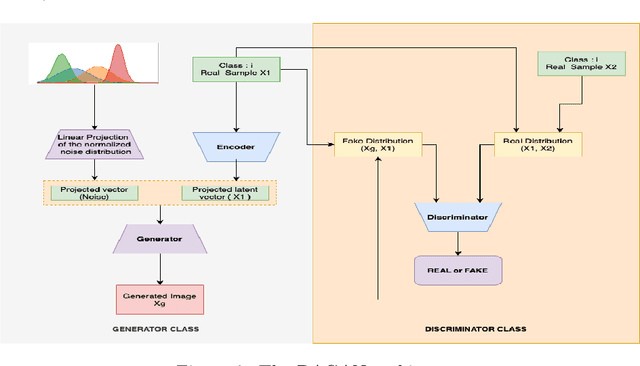

This paper introduces a paradigm of smartphone application based disease diagnostics that may completely revolutionise the way healthcare services are being provided. Although primarily aimed to assist the problems in rendering the healthcare services during the coronavirus pandemic, the model can also be extended to identify the exact disease that the patient is caught with from a broad spectrum of pulmonary diseases. The app inputs Chest X-Ray images captured from the mobile camera which is then relayed to the AI architecture in a cloud platform, and diagnoses the disease with state of the art accuracy. Doctors with a smartphone can leverage the application to save the considerable time that standard COVID-19 tests take for preliminary diagnosis. The scarcity of training data and class imbalance issues were effectively tackled in our approach by the use of Data Augmentation Generative Adversarial Network (DAGAN) and model architecture based as a Convolutional Siamese Network with attention mechanism. The backend model was tested for robustness us-ing publicly available datasets under two different classification scenarios(Binary/Multiclass) with minimal and noisy data. The model achieved pinnacle testing accuracy of 99.30% and 98.40% on the two respective scenarios, making it completely reliable for its users. On top of that a semi-live training scenario was introduced, which helps improve the app performance over time as data accumulates. Overall, the problems of generalisability of complex models and data inefficiency is tackled through the model architecture. The app based setting with semi live training helps in ease of access to reliable healthcare in the society, as well as help ineffective research of rare diseases in a minimal data setting.