 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Sentiment Analysis Engine for Preliminary Depression Status Estimation on Social Media
Paper and Code
Nov 29, 2020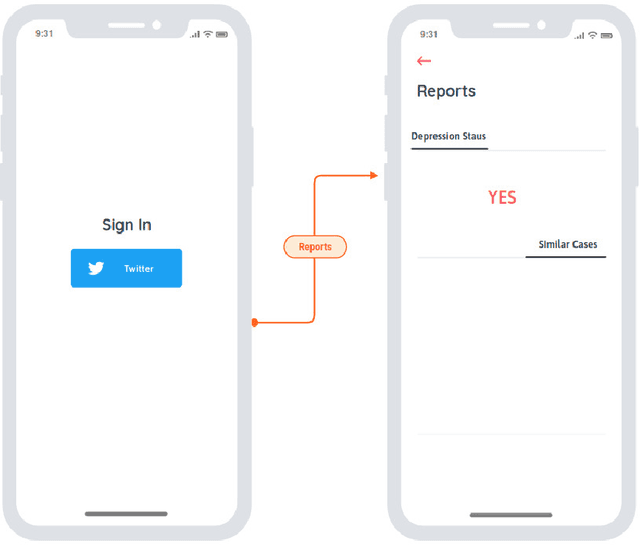
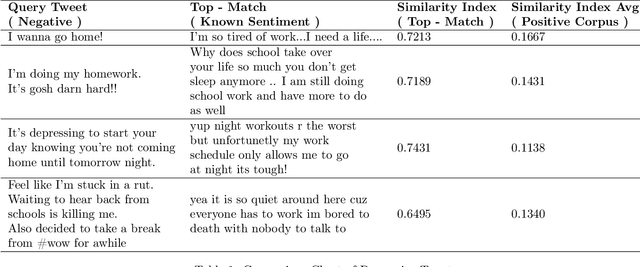
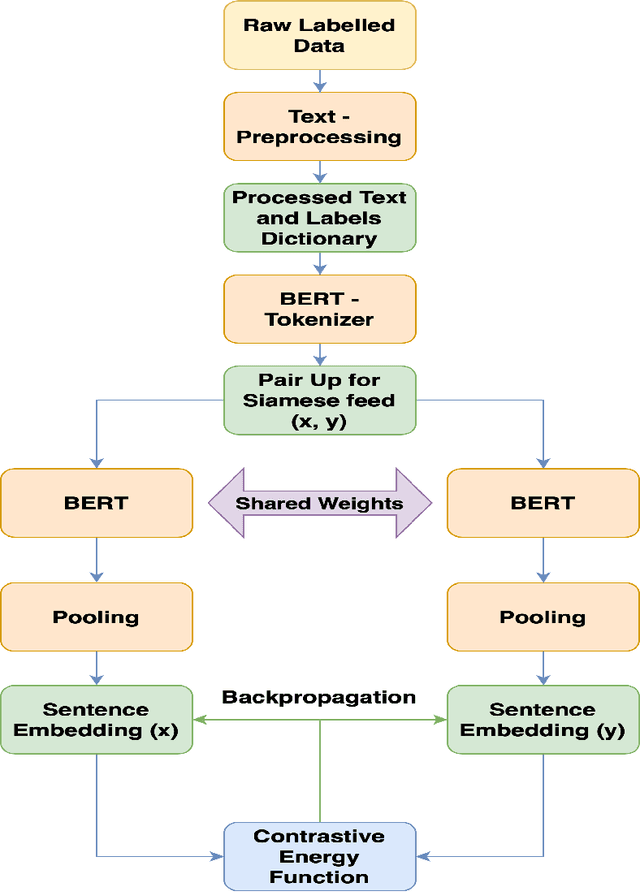
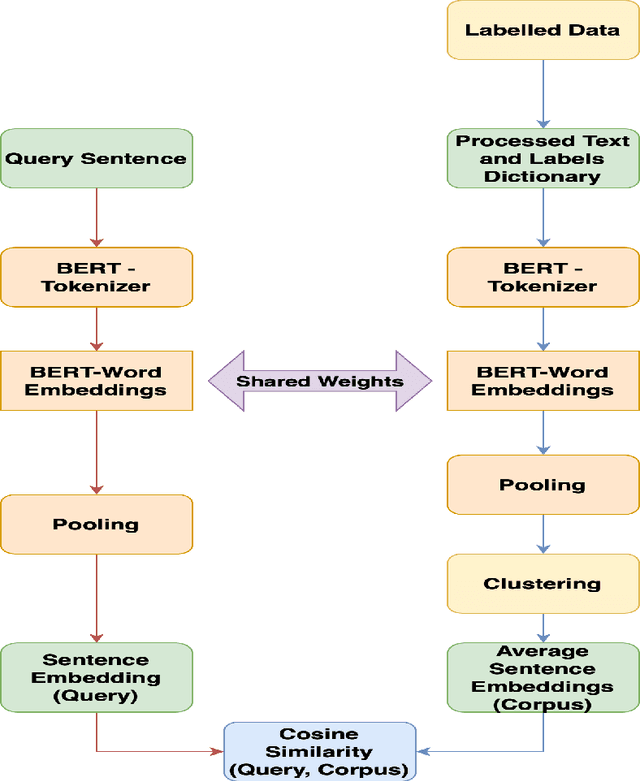
Text sentiment analysis for preliminary depression status estimation of users on social media is a widely exercised and feasible method, However, the immense variety of users accessing the social media websites and their ample mix of vocabularies makes it difficult for commonly applied deep learning-based classifiers to perform. To add to the situation, the lack of adaptability of traditional supervised machine learning could hurt at many levels. We propose a cloud-based smartphone application, with a deep learning-based backend to primarily perform depression detection on Twitter social media. The backend model consists of a RoBERTa based siamese sentence classifier that compares a given tweet (Query) with a labeled set of tweets with known sentiment ( Standard Corpus ). The standard corpus is varied over time with expert opinion so as to improve the model's reliability. A psychologist ( with the patient's permission ) could leverage the application to assess the patient's depression status prior to counseling, which provides better insight into the mental health status of a patient. In addition, to the same, the psychologist could be referred to cases of similar characteristics, which could in turn help in more effective treatment. We evaluate our backend model after fine-tuning it on a publicly available dataset. The find tuned model is made to predict depression on a large set of tweet samples with random noise factors. The model achieved pinnacle results, with a testing accuracy of 87.23% and an AUC of 0.8621.