 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionable Advice from Reviews via Mixture of LoRA Experts: A Two-LLM Pipeline for Issue Extraction and Business Recommendations
Jan 18, 2026Customer reviews contain detailed, domain specific signals about service failures and user expectations, but converting this unstructured feedback into actionable business decisions remains difficult. We study review-to-action generation: producing concrete, implementable recommendations grounded in review text. We propose a modular two-LLM framework in which an Issue model extracts salient issues and assigns coarse themes, and an Advice model generates targeted operational fixes conditioned on the extracted issue representation. To enable specialization without expensive full fine-tuning, we adapt the Advice model using a mixture of LoRA experts strategy: multiple low-rank adapters are trained and a lightweight gating mechanism performs token-level expert mixing at inference, combining complementary expertise across issue types. We construct synthetic review-issue-advice triples from Yelp reviews (airlines and restaurants) to supervise training, and evaluate recommendations using an eight dimension operational rubric spanning actionability, specificity, feasibility, expected impact, novelty, non-redundancy, bias, and clarity. Across both domains, our approach consistently outperforms prompting-only and single-adapter baselines, yielding higher actionability and specificity while retaining favorable efficiency-quality trade-offs.
A Multi-Agent System for Generating Actionable Business Advice
Jan 17, 2026Customer reviews contain rich signals about product weaknesses and unmet user needs, yet existing analytic methods rarely move beyond descriptive tasks such as sentiment analysis or aspect extraction. While large language models (LLMs) can generate free-form suggestions, their outputs often lack accuracy and depth of reasoning. In this paper, we present a multi-agent, LLM-based framework for prescriptive decision support, which transforms large scale review corpora into actionable business advice. The framework integrates four components: clustering to select representative reviews, generation of advices, iterative evaluation, and feasibility based ranking. This design couples corpus distillation with feedback driven advice refinement to produce outputs that are specific, actionable, and practical. Experiments across three service domains and multiple model families show that our framework consistently outperform single model baselines on actionability, specificity, and non-redundancy, with medium sized models approaching the performance of large model frameworks.
A Novel Sentiment Analysis Engine for Preliminary Depression Status Estimation on Social Media
Nov 29, 2020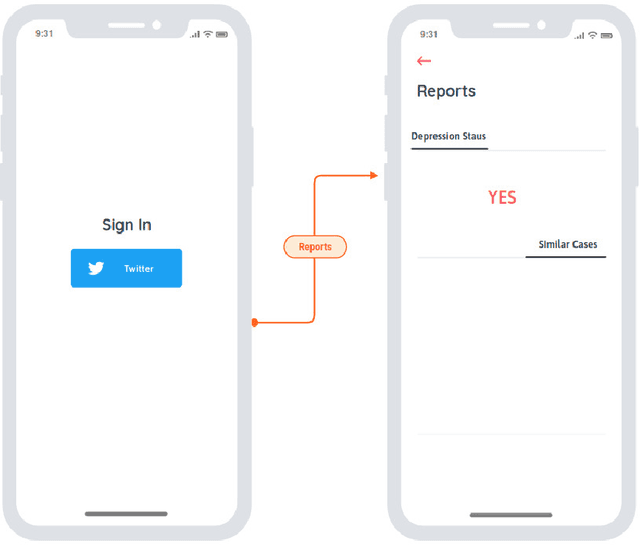
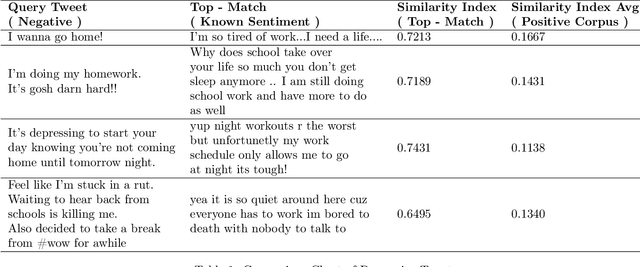
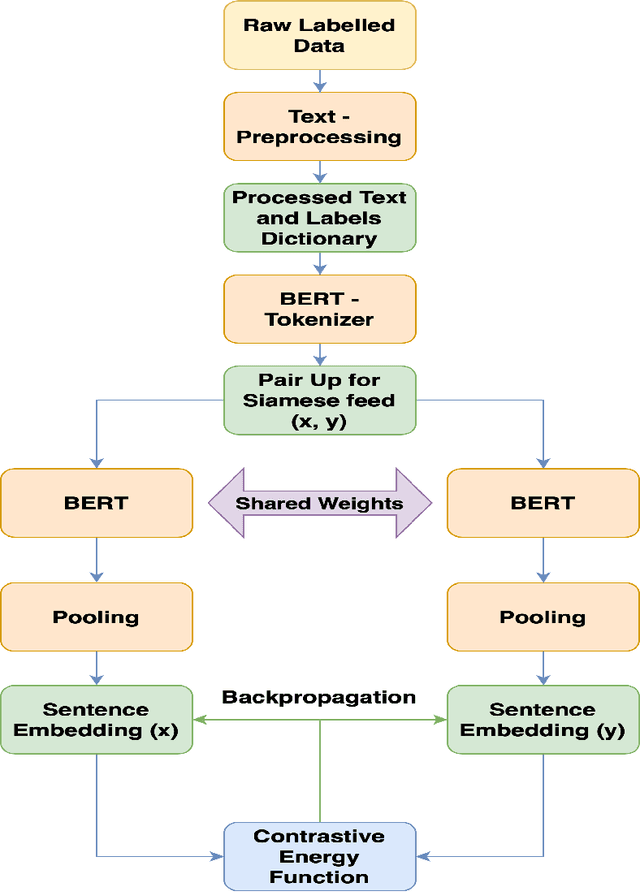
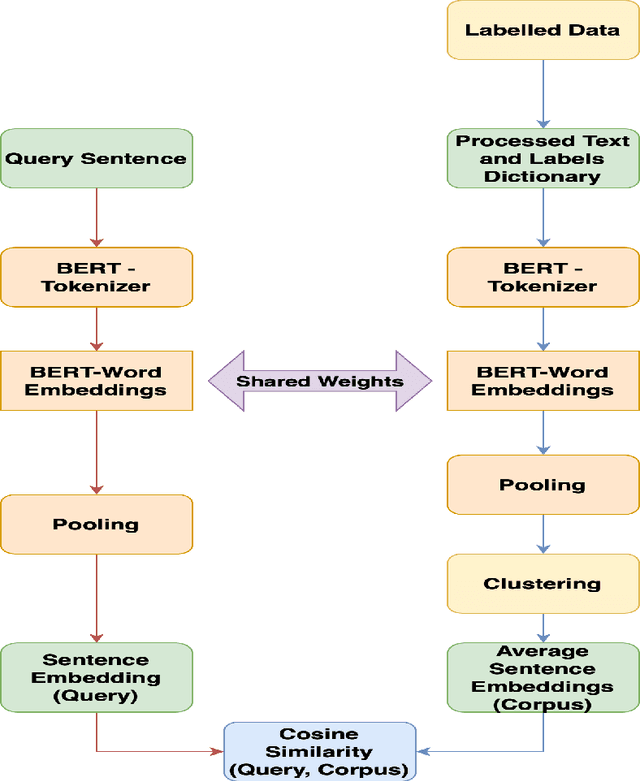
Text sentiment analysis for preliminary depression status estimation of users on social media is a widely exercised and feasible method, However, the immense variety of users accessing the social media websites and their ample mix of vocabularies makes it difficult for commonly applied deep learning-based classifiers to perform. To add to the situation, the lack of adaptability of traditional supervised machine learning could hurt at many levels. We propose a cloud-based smartphone application, with a deep learning-based backend to primarily perform depression detection on Twitter social media. The backend model consists of a RoBERTa based siamese sentence classifier that compares a given tweet (Query) with a labeled set of tweets with known sentiment ( Standard Corpus ). The standard corpus is varied over time with expert opinion so as to improve the model's reliability. A psychologist ( with the patient's permission ) could leverage the application to assess the patient's depression status prior to counseling, which provides better insight into the mental health status of a patient. In addition, to the same, the psychologist could be referred to cases of similar characteristics, which could in turn help in more effective treatment. We evaluate our backend model after fine-tuning it on a publicly available dataset. The find tuned model is made to predict depression on a large set of tweet samples with random noise factors. The model achieved pinnacle results, with a testing accuracy of 87.23% and an AUC of 0.8621.