 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Video Foundation Models for Remote Parkinson's Disease Screening
Feb 13, 2026Remote, video-based assessments offer a scalable pathway for Parkinson's disease (PD) screening. While traditional approaches rely on handcrafted features mimicking clinical scales, recent advances in video foundation models (VFMs) enable representation learning without task-specific customization. However, the comparative effectiveness of different VFM architectures across diverse clinical tasks remains poorly understood. We present a large-scale systematic study using a novel video dataset from 1,888 participants (727 with PD), comprising 32,847 videos across 16 standardized clinical tasks. We evaluate seven state-of-the-art VFMs -- including VideoPrism, V-JEPA, ViViT, and VideoMAE -- to determine their robustness in clinical screening. By evaluating frozen embeddings with a linear classification head, we demonstrate that task saliency is highly model-dependent: VideoPrism excels in capturing visual speech kinematics (no audio) and facial expressivity, while V-JEPA proves superior for upper-limb motor tasks. Notably, TimeSformer remains highly competitive for rhythmic tasks like finger tapping. Our experiments yield AUCs of 76.4-85.3% and accuracies of 71.5-80.6%. While high specificity (up to 90.3%) suggests strong potential for ruling out healthy individuals, the lower sensitivity (43.2-57.3%) highlights the need for task-aware calibration and integration of multiple tasks and modalities. Overall, this work establishes a rigorous baseline for VFM-based PD screening and provides a roadmap for selecting suitable tasks and architectures in remote neurological monitoring. Code and anonymized structured data are publicly available: https://anonymous.4open.science/r/parkinson\_video\_benchmarking-A2C5
A Hybrid Supervised-LLM Pipeline for Actionable Suggestion Mining in Unstructured Customer Reviews
Jan 27, 2026Extracting actionable suggestions from customer reviews is essential for operational decision-making, yet these directives are often embedded within mixed-intent, unstructured text. Existing approaches either classify suggestion-bearing sentences or generate high-level summaries, but rarely isolate the precise improvement instructions businesses need. We evaluate a hybrid pipeline combining a high-recall RoBERTa classifier trained with a precision-recall surrogate to reduce unrecoverable false negatives with a controlled, instruction-tuned LLM for suggestion extraction, categorization, clustering, and summarization. Across real-world hospitality and food datasets, the hybrid system outperforms prompt-only, rule-based, and classifier-only baselines in extraction accuracy and cluster coherence. Human evaluations further confirm that the resulting suggestions and summaries are clear, faithful, and interpretable. Overall, our results show that hybrid reasoning architectures achieve meaningful improvements fine-grained actionable suggestion mining while highlighting challenges in domain adaptation and efficient local deployment.
A Multi-Agent System for Generating Actionable Business Advice
Jan 17, 2026Customer reviews contain rich signals about product weaknesses and unmet user needs, yet existing analytic methods rarely move beyond descriptive tasks such as sentiment analysis or aspect extraction. While large language models (LLMs) can generate free-form suggestions, their outputs often lack accuracy and depth of reasoning. In this paper, we present a multi-agent, LLM-based framework for prescriptive decision support, which transforms large scale review corpora into actionable business advice. The framework integrates four components: clustering to select representative reviews, generation of advices, iterative evaluation, and feasibility based ranking. This design couples corpus distillation with feedback driven advice refinement to produce outputs that are specific, actionable, and practical. Experiments across three service domains and multiple model families show that our framework consistently outperform single model baselines on actionability, specificity, and non-redundancy, with medium sized models approaching the performance of large model frameworks.
Hybrid LSTM-UKF Framework: Ankle Angle and Ground Reaction Force Estimation
Jan 10, 2026Accurate prediction of joint kinematics and kinetics is essential for advancing gait analysis and developing intelligent assistive systems such as prosthetics and exoskeletons. This study presents a hybrid LSTM-UKF framework for estimating ankle angle and ground reaction force (GRF) across varying walking speeds. A multimodal sensor fusion strategy integrates force plate data, knee angle, and GRF signals to enrich biomechanical context. Model performance was evaluated using RMSE and $R^2$ under subject-specific validation. The LSTM-UKF consistently outperformed standalone LSTM and UKF models, achieving up to 18.6\% lower RMSE for GRF prediction at 3 km/h. Additionally, UKF integration improved robustness, reducing ankle angle RMSE by up to 22.4\% compared to UKF alone at 1 km/h. These results underscore the effectiveness of hybrid architectures for reliable gait prediction across subjects and walking conditions.
Vision-Aided Online A* Path Planning for Efficient and Safe Navigation of Service Robots
Nov 10, 2025The deployment of autonomous service robots in human-centric environments is hindered by a critical gap in perception and planning. Traditional navigation systems rely on expensive LiDARs that, while geometrically precise, are semantically unaware, they cannot distinguish a important document on an office floor from a harmless piece of litter, treating both as physically traversable. While advanced semantic segmentation exists, no prior work has successfully integrated this visual intelligence into a real-time path planner that is efficient enough for low-cost, embedded hardware. This paper presents a framework to bridge this gap, delivering context-aware navigation on an affordable robotic platform. Our approach centers on a novel, tight integration of a lightweight perception module with an online A* planner. The perception system employs a semantic segmentation model to identify user-defined visual constraints, enabling the robot to navigate based on contextual importance rather than physical size alone. This adaptability allows an operator to define what is critical for a given task, be it sensitive papers in an office or safety lines in a factory, thus resolving the ambiguity of what to avoid. This semantic perception is seamlessly fused with geometric data. The identified visual constraints are projected as non-geometric obstacles onto a global map that is continuously updated from sensor data, enabling robust navigation through both partially known and unknown environments. We validate our framework through extensive experiments in high-fidelity simulations and on a real-world robotic platform. The results demonstrate robust, real-time performance, proving that a cost-effective robot can safely navigate complex environments while respecting critical visual cues invisible to traditional planners.
Unsupervised Latent Pattern Analysis for Estimating Type 2 Diabetes Risk in Undiagnosed Populations
May 27, 2025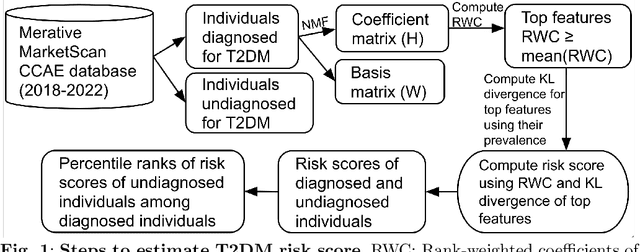
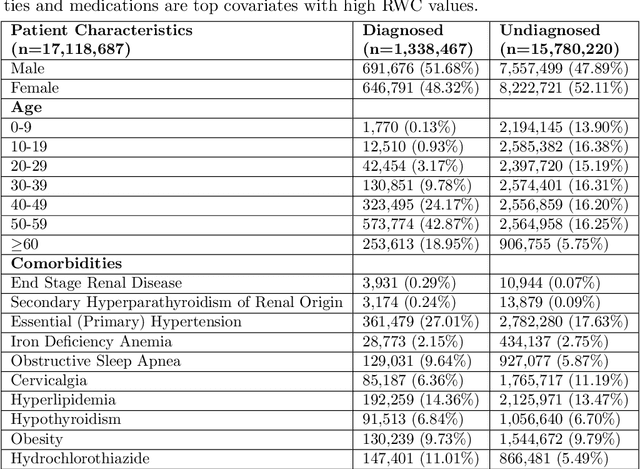
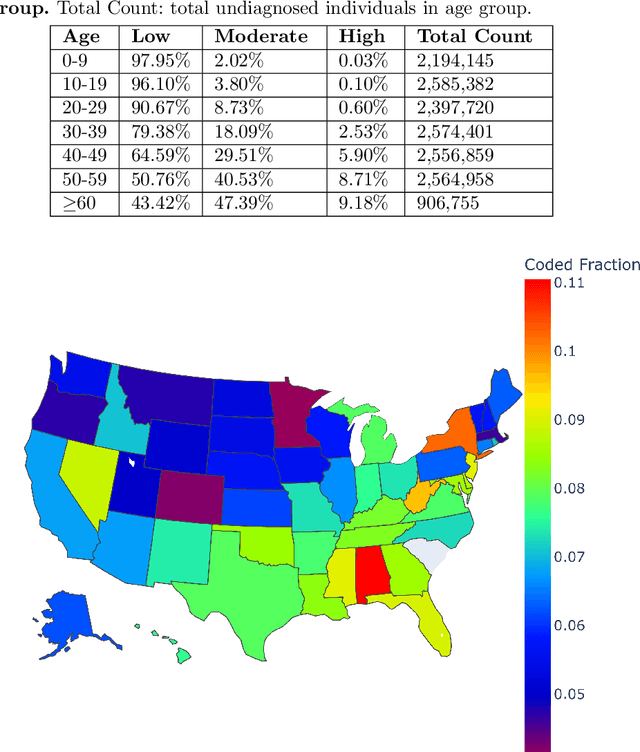
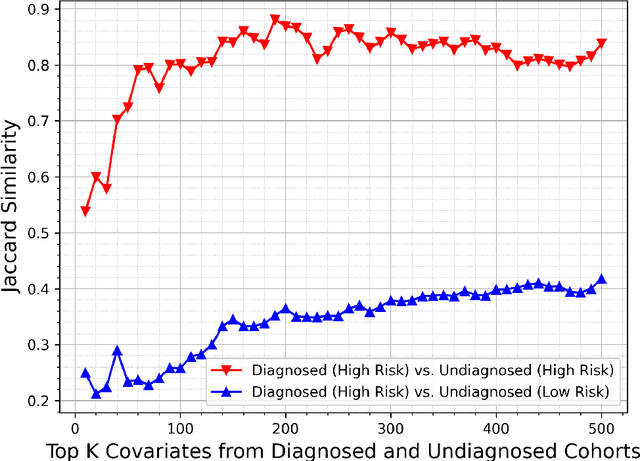
The global prevalence of diabetes, particularly type 2 diabetes mellitus (T2DM), is rapidly increasing, posing significant health and economic challenges. T2DM not only disrupts blood glucose regulation but also damages vital organs such as the heart, kidneys, eyes, nerves, and blood vessels, leading to substantial morbidity and mortality. In the US alone, the economic burden of diagnosed diabetes exceeded \$400 billion in 2022. Early detection of individuals at risk is critical to mitigating these impacts. While machine learning approaches for T2DM prediction are increasingly adopted, many rely on supervised learning, which is often limited by the lack of confirmed negative cases. To address this limitation, we propose a novel unsupervised framework that integrates Non-negative Matrix Factorization (NMF) with statistical techniques to identify individuals at risk of developing T2DM. Our method identifies latent patterns of multimorbidity and polypharmacy among diagnosed T2DM patients and applies these patterns to estimate the T2DM risk in undiagnosed individuals. By leveraging data-driven insights from comorbidity and medication usage, our approach provides an interpretable and scalable solution that can assist healthcare providers in implementing timely interventions, ultimately improving patient outcomes and potentially reducing the future health and economic burden of T2DM.
ARDDQN: Attention Recurrent Double Deep Q-Network for UAV Coverage Path Planning and Data Harvesting
May 17, 2024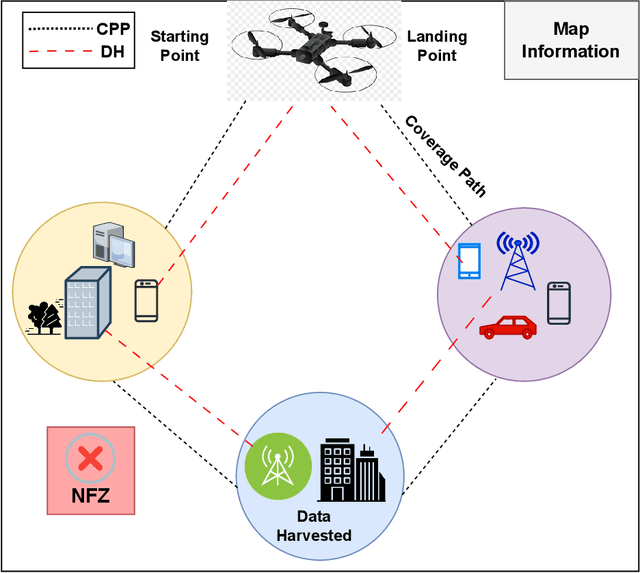



Unmanned Aerial Vehicles (UAVs) have gained popularity in data harvesting (DH) and coverage path planning (CPP) to survey a given area efficiently and collect data from aerial perspectives, while data harvesting aims to gather information from various Internet of Things (IoT) sensor devices, coverage path planning guarantees that every location within the designated area is visited with minimal redundancy and maximum efficiency. We propose the ARDDQN (Attention-based Recurrent Double Deep Q Network), which integrates double deep Q-networks (DDQN) with recurrent neural networks (RNNs) and an attention mechanism to generate path coverage choices that maximize data collection from IoT devices and to learn a control scheme for the UAV that generalizes energy restrictions. We employ a structured environment map comprising a compressed global environment map and a local map showing the UAV agent's locate efficiently scaling to large environments. We have compared Long short-term memory (LSTM), Bi-directional long short-term memory (Bi-LSTM), Gated recurrent unit (GRU) and Bidirectional gated recurrent unit (Bi-GRU) as recurrent neural networks (RNN) to the result without RNN We propose integrating the LSTM with the Attention mechanism to the existing DDQN model, which works best on evolution parameters, i.e., data collection, landing, and coverage ratios for the CPP and data harvesting scenarios.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
PULSNAR -- Positive unlabeled learning selected not at random: class proportion estimation when the SCAR assumption does not hold
Mar 14, 2023



Positive and Unlabeled (PU) learning is a type of semi-supervised binary classification where the machine learning algorithm differentiates between a set of positive instances (labeled) and a set of both positive and negative instances (unlabeled). PU learning has broad applications in settings where confirmed negatives are unavailable or difficult to obtain, and there is value in discovering positives among the unlabeled (e.g., viable drugs among untested compounds). Most PU learning algorithms make the selected completely at random (SCAR) assumption, namely that positives are selected independently of their features. However, in many real-world applications, such as healthcare, positives are not SCAR (e.g., severe cases are more likely to be diagnosed), leading to a poor estimate of the proportion, $\alpha$, of positives among unlabeled examples and poor model calibration, resulting in an uncertain decision threshold for selecting positives. PU learning algorithms can estimate $\alpha$ or the probability of an individual unlabeled instance being positive or both. We propose two PU learning algorithms to estimate $\alpha$, calculate calibrated probabilities for PU instances, and improve classification metrics: i) PULSCAR (positive unlabeled learning selected completely at random), and ii) PULSNAR (positive unlabeled learning selected not at random). PULSNAR uses a divide-and-conquer approach that creates and solves several SCAR-like sub-problems using PULSCAR. In our experiments, PULSNAR outperformed state-of-the-art approaches on both synthetic and real-world benchmark datasets.
Differentiable modeling to unify machine learning and physical models and advance Geosciences
Jan 10, 2023



Process-Based Modeling (PBM) and Machine Learning (ML) are often perceived as distinct paradigms in the geosciences. Here we present differentiable geoscientific modeling as a powerful pathway toward dissolving the perceived barrier between them and ushering in a paradigm shift. For decades, PBM offered benefits in interpretability and physical consistency but struggled to efficiently leverage large datasets. ML methods, especially deep networks, presented strong predictive skills yet lacked the ability to answer specific scientific questions. While various methods have been proposed for ML-physics integration, an important underlying theme -- differentiable modeling -- is not sufficiently recognized. Here we outline the concepts, applicability, and significance of differentiable geoscientific modeling (DG). "Differentiable" refers to accurately and efficiently calculating gradients with respect to model variables, critically enabling the learning of high-dimensional unknown relationships. DG refers to a range of methods connecting varying amounts of prior knowledge to neural networks and training them together, capturing a different scope than physics-guided machine learning and emphasizing first principles. Preliminary evidence suggests DG offers better interpretability and causality than ML, improved generalizability and extrapolation capability, and strong potential for knowledge discovery, while approaching the performance of purely data-driven ML. DG models require less training data while scaling favorably in performance and efficiency with increasing amounts of data. With DG, geoscientists may be better able to frame and investigate questions, test hypotheses, and discover unrecognized linkages.