 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Detection of Alzheimer's Disease from Speech and Text
Paper and Code
Nov 30, 2020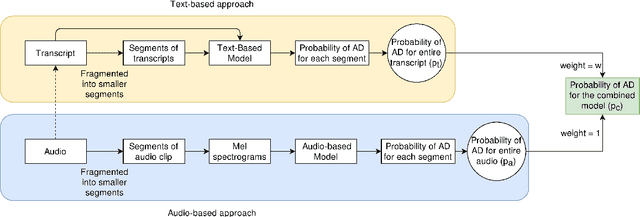
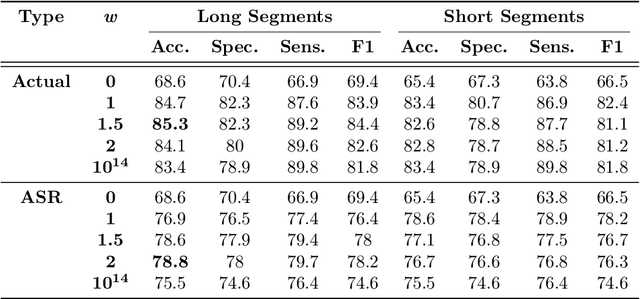
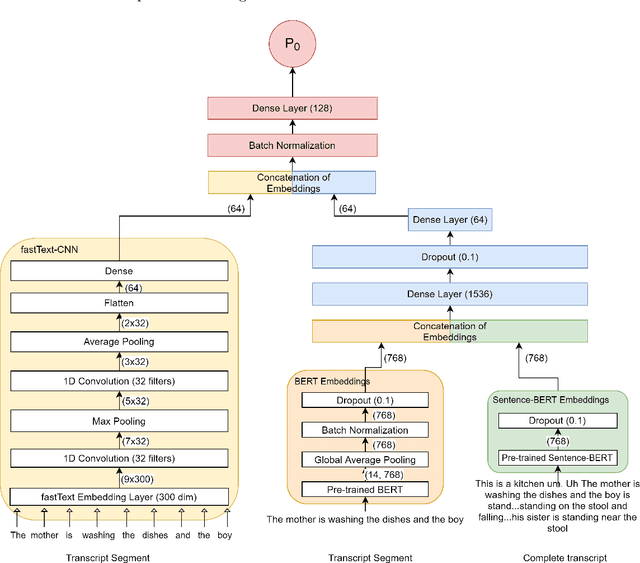
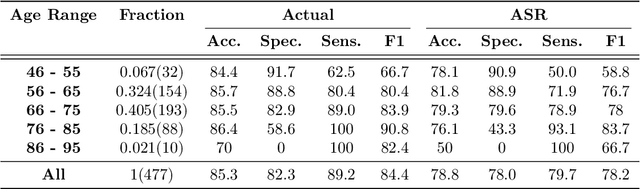
Reliable detection of the prodromal stages of Alzheimer's disease (AD) remains difficult even today because, unlike other neurocognitive impairments, there is no definitive diagnosis of AD in vivo. In this context, existing research has shown that patients often develop language impairment even in mild AD conditions. We propose a multimodal deep learning method that utilizes speech and the corresponding transcript simultaneously to detect AD. For audio signals, the proposed audio-based network, a convolutional neural network (CNN) based model, predicts the diagnosis for multiple speech segments, which are combined for the final prediction. Similarly, we use contextual embedding extracted from BERT concatenated with a CNN-generated embedding for classifying the transcript. The individual predictions of the two models are then combined to make the final classification. We also perform experiments to analyze the model performance when Automated Speech Recognition (ASR) system generated transcripts are used instead of manual transcription in the text-based model. The proposed method achieves 85.3% 10-fold cross-validation accuracy when trained and evaluated on the Dementiabank Pitt corpus.