 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Code Generation via Test-Driven User-Intent Formalization
Paper and Code
Aug 11, 2022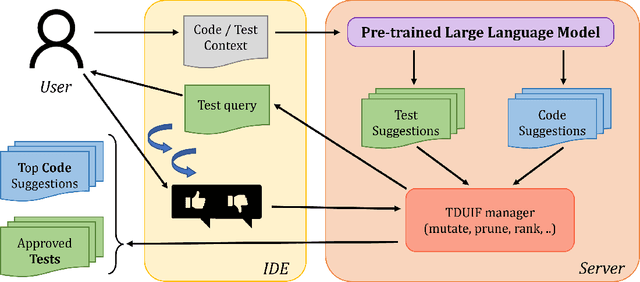



Pre-trained large language models (LLMs) such as OpenAI Codex have shown immense potential in automating significant aspects of coding by producing natural code from informal natural language (NL) intent. However, the code produced does not have any correctness guarantees around satisfying user's intent. In fact, it is hard to define a notion of correctness since natural language can be ambiguous and lacks a formal semantics. In this paper, we take a first step towards addressing the problem above by proposing the workflow of test-driven user-intent formalization (TDUIF), which leverages lightweight user feedback to jointly (a) formalize the user intent as tests (a partial specification), and (b) generates code that meets the formal user intent. To perform a scalable and large-scale automated evaluation of the algorithms without requiring a user in the loop, we describe how to simulate user interaction with high-fidelity using a reference solution. We also describe and implement alternate implementations of several algorithmic components (including mutating and ranking a set of tests) that can be composed for efficient solutions to the TDUIF problem. We have developed a system TICODER that implements several solutions to TDUIF, and compare their relative effectiveness on the MBPP academic code generation benchmark. Our results are promising with using the OpenAI Codex LLM on MBPP: our best algorithm improves the pass@1 code generation accuracy metric from 48.39% to 70.49% with a single user query, and up to 85.48% with up to 5 user queries. Second, we can generate a non-trivial functional unit test consistent with the user intent within an average of 1.69 user queries for 90.40% of the examples for this dataset.