 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Graphical Perception in Large Multimodal Models
Mar 13, 2025Despite the promising results of large multimodal models (LMMs) in complex vision-language tasks that require knowledge, reasoning, and perception abilities together, we surprisingly found that these models struggle with simple tasks on infographics that require perception only. As existing benchmarks primarily focus on end tasks that require various abilities, they provide limited, fine-grained insights into the limitations of the models' perception abilities. To address this gap, we leverage the theory of graphical perception, an approach used to study how humans decode visual information encoded on charts and graphs, to develop an evaluation framework for analyzing gaps in LMMs' perception abilities in charts. With automated task generation and response evaluation designs, our framework enables comprehensive and controlled testing of LMMs' graphical perception across diverse chart types, visual elements, and task types. We apply our framework to evaluate and diagnose the perception capabilities of state-of-the-art LMMs at three granularity levels (chart, visual element, and pixel). Our findings underscore several critical limitations of current state-of-the-art LMMs, including GPT-4o: their inability to (1) generalize across chart types, (2) understand fundamental visual elements, and (3) cross reference values within a chart. These insights provide guidance for future improvements in perception abilities of LMMs. The evaluation framework and labeled data are publicly available at https://github.com/microsoft/lmm-graphical-perception.
Data Analysis in the Era of Generative AI
Sep 27, 2024



This paper explores the potential of AI-powered tools to reshape data analysis, focusing on design considerations and challenges. We explore how the emergence of large language and multimodal models offers new opportunities to enhance various stages of data analysis workflow by translating high-level user intentions into executable code, charts, and insights. We then examine human-centered design principles that facilitate intuitive interactions, build user trust, and streamline the AI-assisted analysis workflow across multiple apps. Finally, we discuss the research challenges that impede the development of these AI-based systems such as enhancing model capabilities, evaluating and benchmarking, and understanding end-user needs.
Rethinking Interpretability in the Era of Large Language Models
Jan 30, 2024

Interpretable machine learning has exploded as an area of interest over the last decade, sparked by the rise of increasingly large datasets and deep neural networks. Simultaneously, large language models (LLMs) have demonstrated remarkable capabilities across a wide array of tasks, offering a chance to rethink opportunities in interpretable machine learning. Notably, the capability to explain in natural language allows LLMs to expand the scale and complexity of patterns that can be given to a human. However, these new capabilities raise new challenges, such as hallucinated explanations and immense computational costs. In this position paper, we start by reviewing existing methods to evaluate the emerging field of LLM interpretation (both interpreting LLMs and using LLMs for explanation). We contend that, despite their limitations, LLMs hold the opportunity to redefine interpretability with a more ambitious scope across many applications, including in auditing LLMs themselves. We highlight two emerging research priorities for LLM interpretation: using LLMs to directly analyze new datasets and to generate interactive explanations.
Demystifying GPT Self-Repair for Code Generation
Jun 22, 2023Large Language Models (LLMs) have shown remarkable aptitude in code generation but still struggle on challenging programming tasks. Self-repair -- in which the model debugs and fixes mistakes in its own code -- has recently become a popular way to boost performance in these settings. However, only very limited studies on how and when self-repair works effectively exist in the literature, and one might wonder to what extent a model is really capable of providing accurate feedback on why the code is wrong when that code was generated by the same model. In this paper, we analyze GPT-3.5 and GPT-4's ability to perform self-repair on APPS, a challenging dataset consisting of diverse coding challenges. To do so, we first establish a new evaluation strategy dubbed pass@t that measures the pass rate of the tasks against the total number of tokens sampled from the model, enabling a fair comparison to purely sampling-based approaches. With this evaluation strategy, we find that the effectiveness of self-repair is only seen in GPT-4. We also observe that self-repair is bottlenecked by the feedback stage; using GPT-4 to give feedback on the programs generated by GPT-3.5 and using expert human programmers to give feedback on the programs generated by GPT-4, we unlock significant performance gains.
CodeExp: Explanatory Code Document Generation
Nov 25, 2022Developing models that can automatically generate detailed code explanation can greatly benefit software maintenance and programming education. However, existing code-to-text generation models often produce only high-level summaries of code that do not capture implementation-level choices essential for these scenarios. To fill in this gap, we propose the code explanation generation task. We first conducted a human study to identify the criteria for high-quality explanatory docstring for code. Based on that, we collected and refined a large-scale code docstring corpus and formulated automatic evaluation metrics that best match human assessments. Finally, we present a multi-stage fine-tuning strategy and baseline models for the task. Our experiments show that (1) our refined training dataset lets models achieve better performance in the explanation generation tasks compared to larger unrefined data (15x larger), and (2) fine-tuned models can generate well-structured long docstrings comparable to human-written ones. We envision our training dataset, human-evaluation protocol, recommended metrics, and fine-tuning strategy can boost future code explanation research. The code and annotated data are available at https://github.com/subercui/CodeExp.
Execution-based Evaluation for Data Science Code Generation Models
Nov 17, 2022
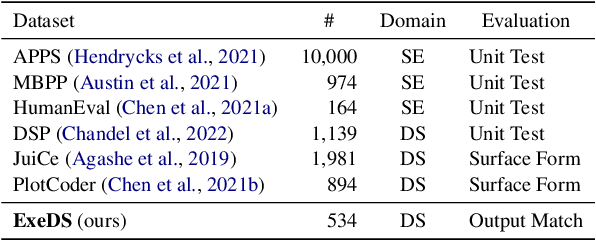
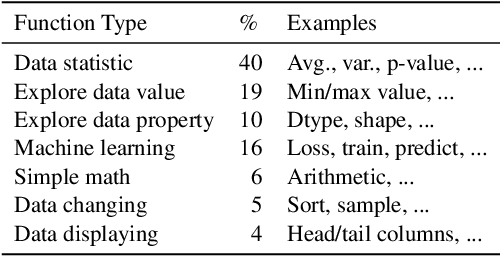
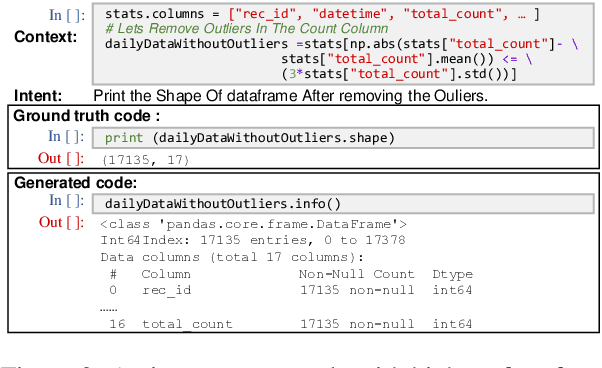
Code generation models can benefit data scientists' productivity by automatically generating code from context and text descriptions. An important measure of the modeling progress is whether a model can generate code that can correctly execute to solve the task. However, due to the lack of an evaluation dataset that directly supports execution-based model evaluation, existing work relies on code surface form similarity metrics (e.g., BLEU, CodeBLEU) for model selection, which can be inaccurate. To remedy this, we introduce ExeDS, an evaluation dataset for execution evaluation for data science code generation tasks. ExeDS contains a set of 534 problems from Jupyter Notebooks, each consisting of code context, task description, reference program, and the desired execution output. With ExeDS, we evaluate the execution performance of five state-of-the-art code generation models that have achieved high surface-form evaluation scores. Our experiments show that models with high surface-form scores do not necessarily perform well on execution metrics, and execution-based metrics can better capture model code generation errors. Source code and data can be found at https://github.com/Jun-jie-Huang/ExeDS
Interactive Code Generation via Test-Driven User-Intent Formalization
Aug 11, 2022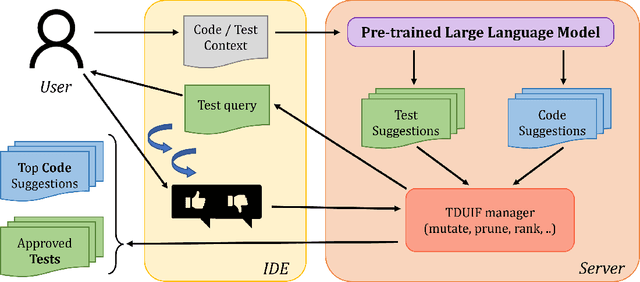



Pre-trained large language models (LLMs) such as OpenAI Codex have shown immense potential in automating significant aspects of coding by producing natural code from informal natural language (NL) intent. However, the code produced does not have any correctness guarantees around satisfying user's intent. In fact, it is hard to define a notion of correctness since natural language can be ambiguous and lacks a formal semantics. In this paper, we take a first step towards addressing the problem above by proposing the workflow of test-driven user-intent formalization (TDUIF), which leverages lightweight user feedback to jointly (a) formalize the user intent as tests (a partial specification), and (b) generates code that meets the formal user intent. To perform a scalable and large-scale automated evaluation of the algorithms without requiring a user in the loop, we describe how to simulate user interaction with high-fidelity using a reference solution. We also describe and implement alternate implementations of several algorithmic components (including mutating and ranking a set of tests) that can be composed for efficient solutions to the TDUIF problem. We have developed a system TICODER that implements several solutions to TDUIF, and compare their relative effectiveness on the MBPP academic code generation benchmark. Our results are promising with using the OpenAI Codex LLM on MBPP: our best algorithm improves the pass@1 code generation accuracy metric from 48.39% to 70.49% with a single user query, and up to 85.48% with up to 5 user queries. Second, we can generate a non-trivial functional unit test consistent with the user intent within an average of 1.69 user queries for 90.40% of the examples for this dataset.
Fault-Aware Neural Code Rankers
Jun 04, 2022


Large language models (LLMs) have demonstrated an impressive ability to generate code for various programming tasks. In many instances, LLMs can generate a correct program for a task when given numerous trials. Consequently, a recent trend is to do large scale sampling of programs using a model and then filtering/ranking the programs based on the program execution on a small number of known unit tests to select one candidate solution. However, these approaches assume that the unit tests are given and assume the ability to safely execute the generated programs (which can do arbitrary dangerous operations such as file manipulations). Both of the above assumptions are impractical in real-world software development. In this paper, we propose fault-aware neural code rankers that can predict the correctness of a sampled program without executing it. The fault-aware rankers are trained to predict different kinds of execution information such as predicting the exact compile/runtime error type (e.g., an IndexError or a TypeError). We show that our fault-aware rankers can significantly increase the pass@1 accuracy of various code generation models (including Codex, GPT-Neo, GPT-J) on APPS, HumanEval and MBPP datasets.
Learning from Self-Sampled Correct and Partially-Correct Programs
May 28, 2022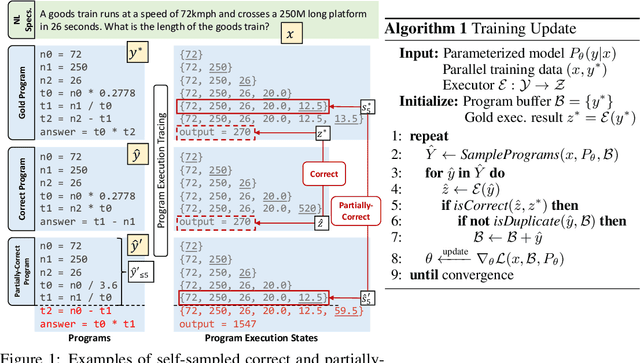

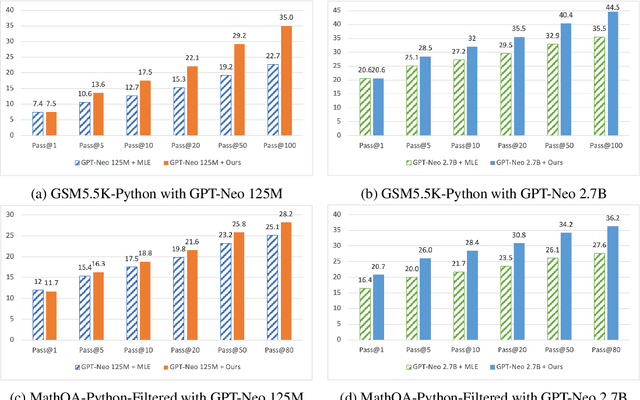
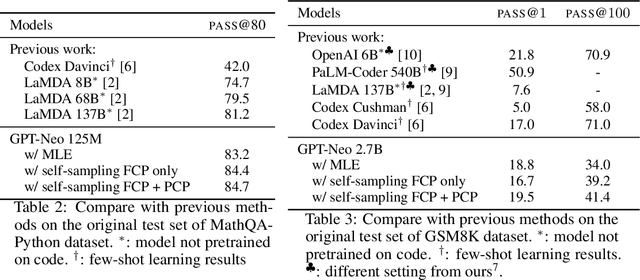
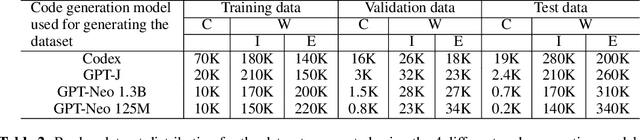
Program synthesis aims to generate executable programs that are consistent with the user specification. While there are often multiple programs that satisfy the same user specification, existing neural program synthesis models are often only learned from one reference program by maximizing its log-likelihood. This causes the model to be overly confident in its predictions as it sees the single solution repeatedly during training. This leads to poor generalization on unseen examples, even when multiple attempts are allowed. To mitigate this issue, we propose to let the model perform sampling during training and learn from both self-sampled fully-correct programs, which yield the gold execution results, as well as partially-correct programs, whose intermediate execution state matches another correct program. We show that our use of self-sampled correct and partially-correct programs can benefit learning and help guide the sampling process, leading to more efficient exploration of the program space. Additionally, we explore various training objectives to support learning from multiple programs per example and find they greatly affect the performance. Experiments on the MathQA and GSM8K datasets show that our proposed method improves the pass@k performance by 3.1% to 12.3% compared to learning from a single reference program with MLE.
Safe Human-Interactive Control via Shielding
Oct 11, 2021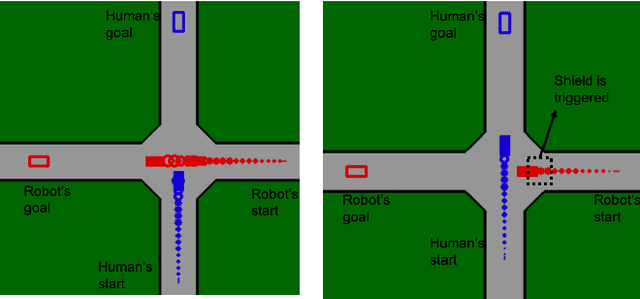
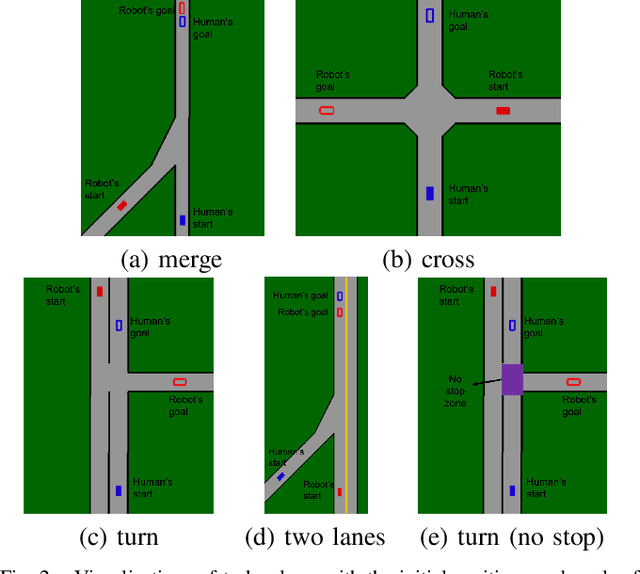
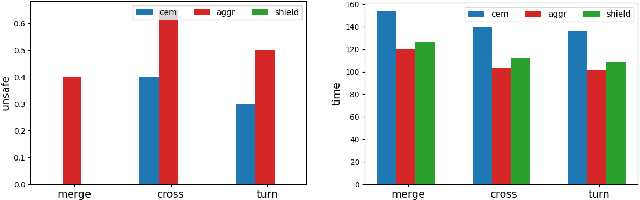
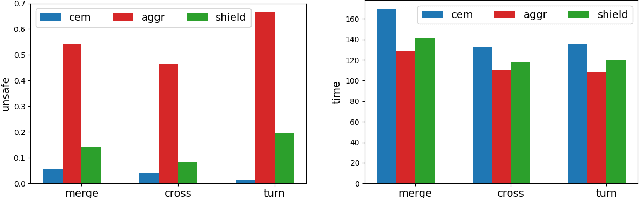
Ensuring safety for human-interactive robotics is important due to the potential for human injury. The key challenge is defining safety in a way that accounts for the complex range of human behaviors without modeling the human as an unconstrained adversary. We propose a novel approach to ensuring safety in these settings. Our approach focuses on defining backup actions that we believe human always considers taking to avoid an accident -- e.g., brake to avoid rear-ending the other agent. Given such a definition, we consider a safety constraint that guarantees safety as long as the human takes the appropriate backup actions when necessary to ensure safety. Then, we propose an algorithm that overrides an arbitrary given controller as needed to ensure that the robot is safe. We evaluate our approach in a simulated environment, interacting with both real and simulated humans.