 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeExp: Explanatory Code Document Generation
Nov 25, 2022Developing models that can automatically generate detailed code explanation can greatly benefit software maintenance and programming education. However, existing code-to-text generation models often produce only high-level summaries of code that do not capture implementation-level choices essential for these scenarios. To fill in this gap, we propose the code explanation generation task. We first conducted a human study to identify the criteria for high-quality explanatory docstring for code. Based on that, we collected and refined a large-scale code docstring corpus and formulated automatic evaluation metrics that best match human assessments. Finally, we present a multi-stage fine-tuning strategy and baseline models for the task. Our experiments show that (1) our refined training dataset lets models achieve better performance in the explanation generation tasks compared to larger unrefined data (15x larger), and (2) fine-tuned models can generate well-structured long docstrings comparable to human-written ones. We envision our training dataset, human-evaluation protocol, recommended metrics, and fine-tuning strategy can boost future code explanation research. The code and annotated data are available at https://github.com/subercui/CodeExp.
Synthesizing Collective Communication Algorithms for Heterogeneous Networks with TACCL
Nov 15, 2021
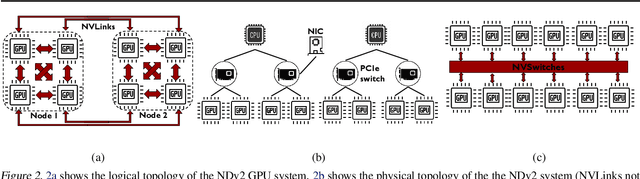
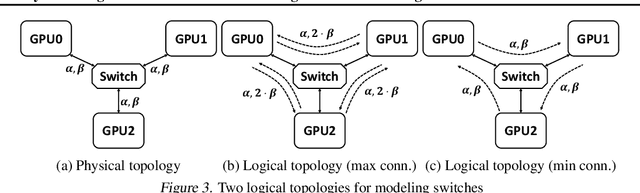
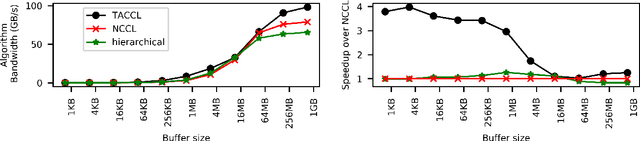
Large ML models and datasets have necessitated the use of multi-GPU systems for distributed model training. To harness the power offered by multi-GPU systems, it is critical to eliminate bottlenecks in inter-GPU communication - a problem made challenging by the heterogeneous nature of interconnects. In this work, we present TACCL, a synthesizer for collective communication primitives for large-scale multi-GPU systems. TACCL encodes a profiled topology and input size into a synthesis problem to generate optimized communication algorithms. TACCL is built on top of the standard NVIDIA Collective Communication Library (NCCL), allowing it to be a drop-in replacement for GPU communication in frameworks like PyTorch with minimal changes. TACCL generates algorithms for communication primitives like Allgather, Alltoall, and Allreduce that are up to $3\times$ faster than NCCL. Using TACCL's algorithms speeds up the end-to-end training of an internal mixture of experts model by $17\%$. By decomposing the optimization problem into parts and leveraging the symmetry in multi-GPU topologies, TACCL synthesizes collectives for up to 80-GPUs in less than 3 minutes, at least two orders of magnitude faster than other synthesis-based state-of-the-art collective communication libraries.
MergeBERT: Program Merge Conflict Resolution via Neural Transformers
Sep 08, 2021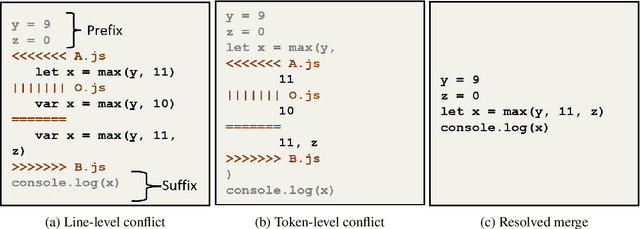

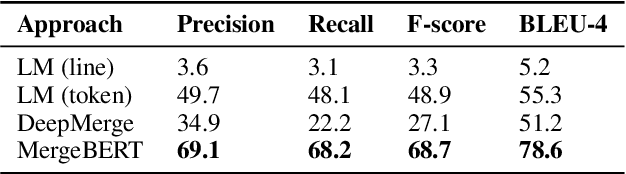
Collaborative software development is an integral part of the modern software development life cycle, essential to the success of large-scale software projects. When multiple developers make concurrent changes around the same lines of code, a merge conflict may occur. Such conflicts stall pull requests and continuous integration pipelines for hours to several days, seriously hurting developer productivity. In this paper, we introduce MergeBERT, a novel neural program merge framework based on the token-level three-way differencing and a transformer encoder model. Exploiting restricted nature of merge conflict resolutions, we reformulate the task of generating the resolution sequence as a classification task over a set of primitive merge patterns extracted from real-world merge commit data. Our model achieves 64--69% precision of merge resolution synthesis, yielding nearly a 2x performance improvement over existing structured and neural program merge tools. Finally, we demonstrate versatility of our model, which is able to perform program merge in a multilingual setting with Java, JavaScript, TypeScript, and C# programming languages, generalizing zero-shot to unseen languages.
CoCoNet: Co-Optimizing Computation and Communication for Distributed Machine Learning
May 13, 2021
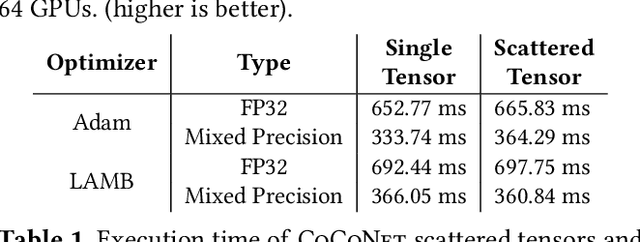

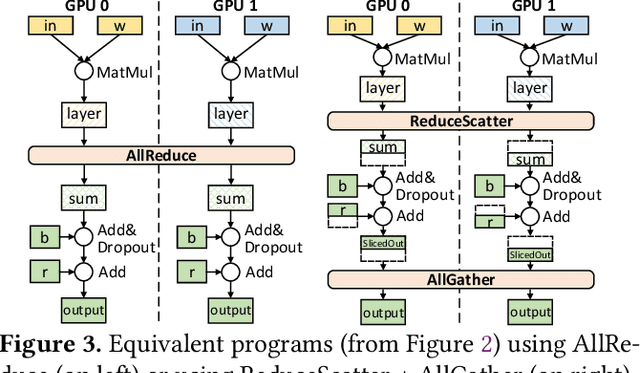
Modern deep learning workloads run on distributed hardware and are difficult to optimize -- data, model, and pipeline parallelism require a developer to thoughtfully restructure their workload around optimized computation and communication kernels in libraries such as cuBLAS and NCCL. The logical separation between computation and communication leaves performance on the table with missed optimization opportunities across abstraction boundaries. To explore these opportunities, this paper presents CoCoNet, which consists of a compute language to express programs with both computation and communication, a scheduling language to apply transformations on such programs, and a compiler to generate high performance kernels. Providing both computation and communication as first class constructs enables new optimizations, such as overlapping or fusion of communication with computation. CoCoNet allowed us to optimize several data, model and pipeline parallel workloads in existing deep learning systems with very few lines of code. We show significant improvements after integrating novel CoCoNet generated kernels.
Scaling Distributed Training with Adaptive Summation
Jun 04, 2020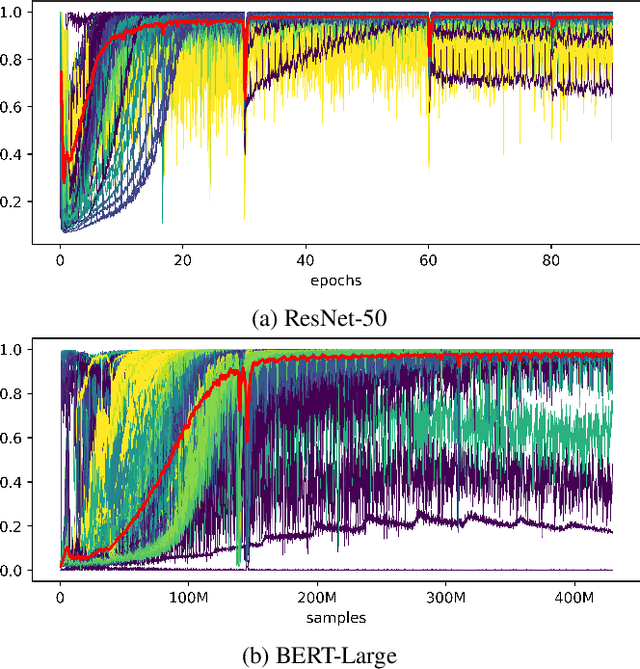
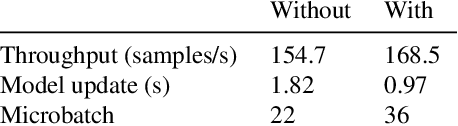
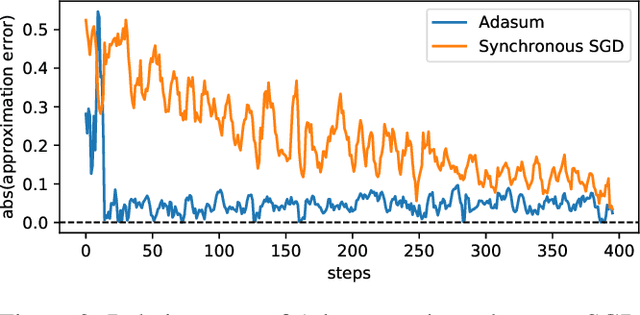

Stochastic gradient descent (SGD) is an inherently sequential training algorithm--computing the gradient at batch $i$ depends on the model parameters learned from batch $i-1$. Prior approaches that break this dependence do not honor them (e.g., sum the gradients for each batch, which is not what sequential SGD would do) and thus potentially suffer from poor convergence. This paper introduces a novel method to combine gradients called Adasum (for adaptive sum) that converges faster than prior work. Adasum is easy to implement, almost as efficient as simply summing gradients, and is integrated into the open-source toolkit Horovod. This paper first provides a formal justification for Adasum and then empirically demonstrates Adasum is more accurate than prior gradient accumulation methods. It then introduces a series of case-studies to show Adasum works with multiple frameworks, (TensorFlow and PyTorch), scales multiple optimizers (Momentum-SGD, Adam, and LAMB) to larger batch-sizes while still giving good downstream accuracy. Finally, it proves that Adasum converges. To summarize, Adasum scales Momentum-SGD on the MLPerf Resnet50 benchmark to 64K examples before communication (no MLPerf v0.5 entry converged with more than 16K), the Adam optimizer to 64K examples before communication on BERT-LARGE (prior work showed Adam stopped scaling at 16K), and the LAMB optimizer to 128K before communication on BERT-LARGE (prior work used 64K), all while maintaining downstream accuracy metrics. Finally, if a user does not need to scale, we show LAMB with Adasum on BERT-LARGE converges in 30% fewer steps than the baseline.
Distributed Word2Vec using Graph Analytics Frameworks
Sep 08, 2019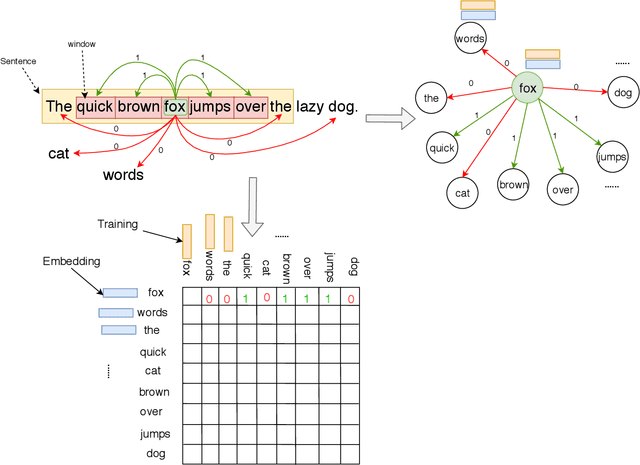
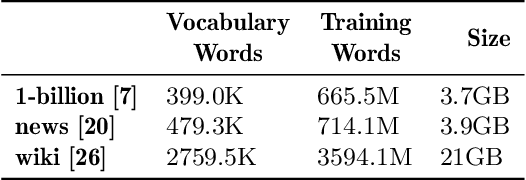
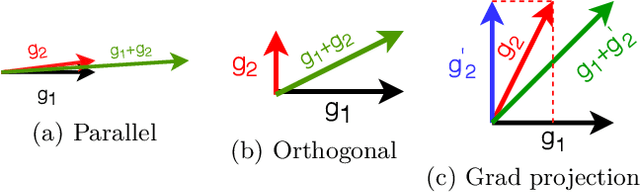
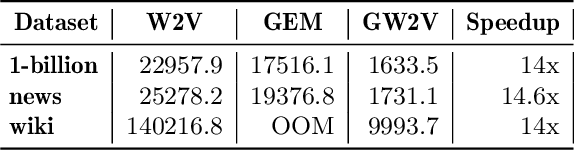
Word embeddings capture semantic and syntactic similarities of words, represented as vectors. Word2Vec is a popular implementation of word embeddings; it takes as input a large corpus of text and learns a model that maps unique words in that corpus to other contextually relevant words. After training, Word2Vec's internal vector representation of words in the corpus map unique words to a vector space, which are then used in many downstream tasks. Training these models requires significant computational resources (training time often measured in days) and is difficult to parallelize. Most word embedding training uses stochastic gradient descent (SGD), an "inherently" sequential algorithm where at each step, the processing of the current example depends on the parameters learned from the previous examples. Prior approaches to parallelizing SGD do not honor these dependencies and thus potentially suffer poor convergence. This paper introduces GraphWord2Vec, a distributedWord2Vec algorithm which formulates the Word2Vec training process as a distributed graph problem and thus leverage state-of-the-art distributed graph analytics frameworks such as D-Galois and Gemini that scale to large distributed clusters. GraphWord2Vec also demonstrates how to use model combiners to honor data dependencies in SGD and thus scale without giving up convergence. We will show that GraphWord2Vec has linear scalability up to 32 machines converging as fast as a sequential run in terms of epochs, thus reducing training time by 14x.
CHET: Compiler and Runtime for Homomorphic Evaluation of Tensor Programs
Oct 01, 2018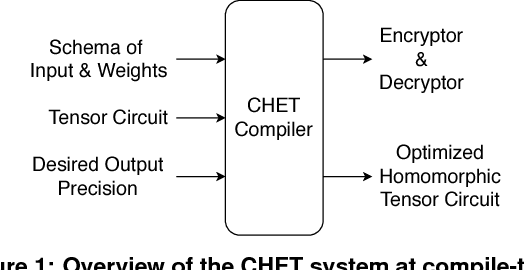
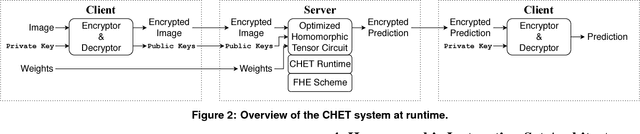
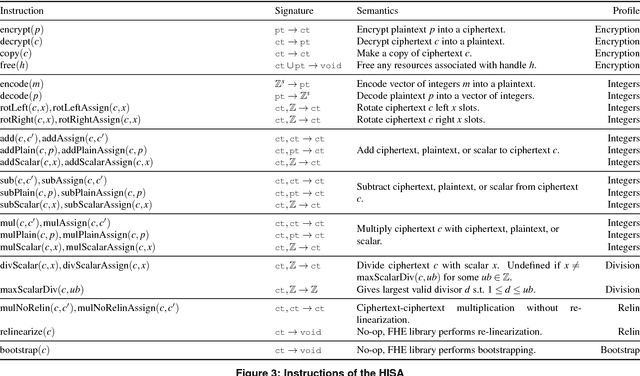
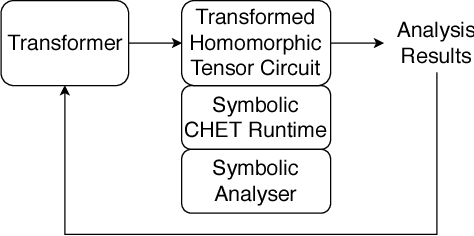
Fully Homomorphic Encryption (FHE) refers to a set of encryption schemes that allow computations to be applied directly on encrypted data without requiring a secret key. This enables novel application scenarios where a client can safely offload storage and computation to a third-party cloud provider without having to trust the software and the hardware vendors with the decryption keys. Recent advances in both FHE schemes and implementations have moved such applications from theoretical possibilities into the realm of practicalities. This paper proposes a compact and well-reasoned interface called the Homomorphic Instruction Set Architecture (HISA) for developing FHE applications. Just as the hardware ISA interface enabled hardware advances to proceed independent of software advances in the compiler and language runtimes, HISA decouples compiler optimizations and runtimes for supporting FHE applications from advancements in the underlying FHE schemes. This paper demonstrates the capabilities of HISA by building an end-to-end software stack for evaluating neural network models on encrypted data. Our stack includes an end-to-end compiler, runtime, and a set of optimizations. Our approach shows generated code, on a set of popular neural network architectures, is faster than hand-optimized implementations.
High Five: Improving Gesture Recognition by Embracing Uncertainty
Oct 25, 2017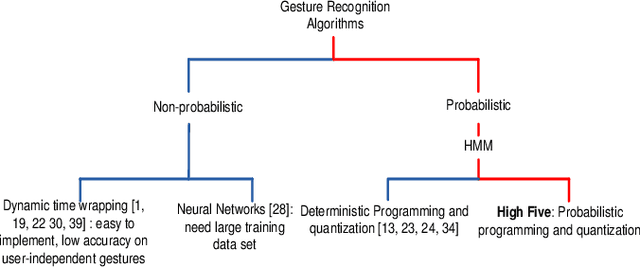
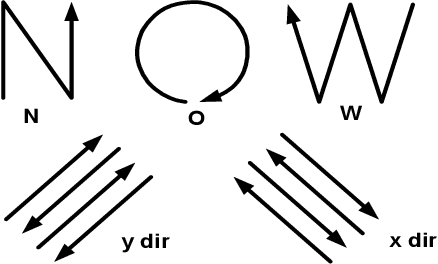
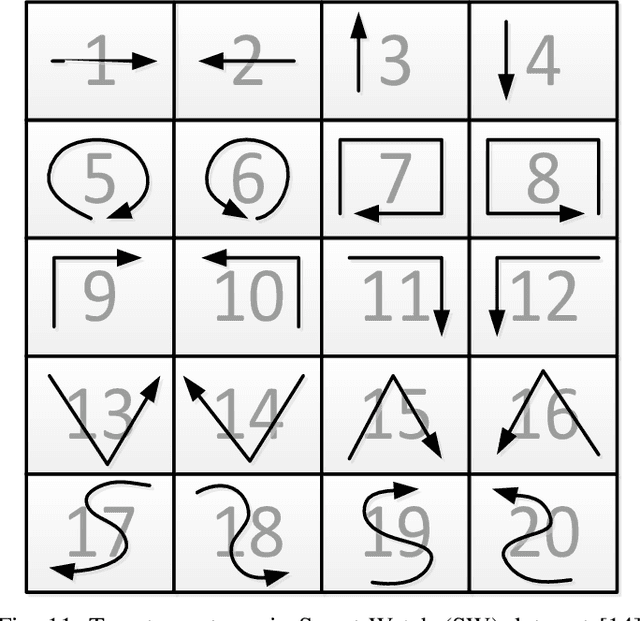
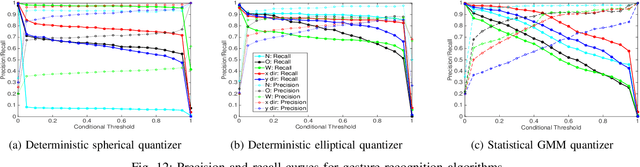
Sensors on mobile devices---accelerometers, gyroscopes, pressure meters, and GPS---invite new applications in gesture recognition, gaming, and fitness tracking. However, programming them remains challenging because human gestures captured by sensors are noisy. This paper illustrates that noisy gestures degrade training and classification accuracy for gesture recognition in state-of-the-art deterministic Hidden Markov Models (HMM). We introduce a new statistical quantization approach that mitigates these problems by (1) during training, producing gesture-specific codebooks, HMMs, and error models for gesture sequences; and (2) during classification, exploiting the error model to explore multiple feasible HMM state sequences. We implement classification in Uncertain<t>, a probabilistic programming system that encapsulates HMMs and error models and then automates sampling and inference in the runtime. Uncertain<T> developers directly express a choice of application-specific trade-off between recall and precision at gesture recognition time, rather than at training time. We demonstrate benefits in configurability, precision, recall, and recognition on two data sets with 25 gestures from 28 people and 4200 total gestures. Incorporating gesture error more accurately in modeling improves the average recognition rate of 20 gestures from 34\% in prior work to 62\%. Incorporating the error model during classification further improves the average gesture recognition rate to 71\%. As far as we are aware, no prior work shows how to generate an HMM error model during training and use it to improve classification rates.
Parallel Stochastic Gradient Descent with Sound Combiners
May 22, 2017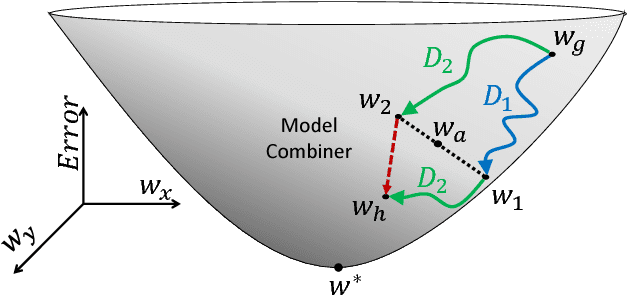

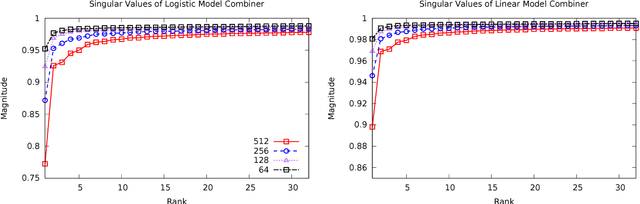
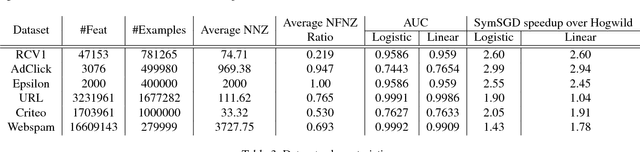
Stochastic gradient descent (SGD) is a well known method for regression and classification tasks. However, it is an inherently sequential algorithm at each step, the processing of the current example depends on the parameters learned from the previous examples. Prior approaches to parallelizing linear learners using SGD, such as HOGWILD! and ALLREDUCE, do not honor these dependencies across threads and thus can potentially suffer poor convergence rates and/or poor scalability. This paper proposes SYMSGD, a parallel SGD algorithm that, to a first-order approximation, retains the sequential semantics of SGD. Each thread learns a local model in addition to a model combiner, which allows local models to be combined to produce the same result as what a sequential SGD would have produced. This paper evaluates SYMSGD's accuracy and performance on 6 datasets on a shared-memory machine shows upto 11x speedup over our heavily optimized sequential baseline on 16 cores and 2.2x, on average, faster than HOGWILD!.