 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVCACHE: A Stateful Tool-Value Cache for Post-Training LLM Agents
Feb 11, 2026In RL post-training of LLM agents, calls to external tools take several seconds or even minutes, leaving allocated GPUs idle and inflating post-training time and cost. While many tool invocations repeat across parallel rollouts and could in principle be cached, naively caching their outputs for reuse is incorrect since tool outputs depend on the environment state induced by prior agent interactions. We present TVCACHE, a stateful tool-value cache for LLM agent post-training. TVCACHE maintains a tree of observed tool-call sequences and performs longest-prefix matching for cache lookups: a hit occurs only when the agent's full tool history matches a previously executed sequence, guaranteeing identical environment state. On three diverse workloads-terminal-based tasks, SQL generation, and video understanding. TVCACHE achieves cache hit rates of up to 70% and reduces median tool call execution time by up to 6.9X, with no degradation in post-training reward accumulation.
FlashDMoE: Fast Distributed MoE in a Single Kernel
Jun 05, 2025The computational sparsity of Mixture-of-Experts (MoE) models enables sub-linear growth in compute cost as model size increases, offering a scalable path to training massive neural networks. However, existing implementations suffer from \emph{low GPU utilization}, \emph{significant latency overhead}, and a fundamental \emph{inability to leverage task locality}, primarily due to CPU-managed scheduling, host-initiated communication, and frequent kernel launches. To overcome these limitations, we develop FlashDMoE, a fully GPU-resident MoE operator that fuses expert computation and inter-GPU communication into a \emph{single persistent GPU kernel}. FlashDMoE enables fine-grained pipelining of dispatch, compute, and combine phases, eliminating launch overheads and reducing idle gaps. Its device-initiated communication protocol introduces \emph{payload-efficient} data transfers, significantly shrinking buffer sizes in sparsely activated MoE layers. When evaluated on a single 8-H100 GPU node with MoE models having up to 128 experts and 16K token sequences, FlashDMoE achieves up to \textbf{6}x lower latency, \textbf{5,7}x higher throughput, \textbf{4}x better weak scaling efficiency, and \textbf{9}x higher GPU utilization compared to state-of-the-art baselines, despite using FP32 while baselines use FP16. FlashDMoE demonstrates that principled GPU kernel-hardware co-design is key to unlocking the performance ceiling of large-scale distributed ML workloads.
LUMION: Fast Fault Recovery for ML Jobs Using Programmable Optical Fabrics
May 29, 2025When accelerators fail in modern ML datacenters, operators migrate the affected ML training or inference jobs to entirely new racks. This approach, while preserving network performance, is highly inefficient, requiring datacenters to reserve full racks of idle accelerators for fault tolerance. In this paper, we address this resource inefficiency by introducing LUMION, a novel reconfigurable optical fabric for connecting accelerators within a datacenter rack. Instead of migrating entire ML jobs, LUMION dynamically integrates spare accelerators into ongoing workloads as failures occur, thereby maintaining consistent performance without costly migrations. We show the benefits of LUMION by building an end-to-end hardware prototype. Our experiments fine-tune Llama 3.2 and show that LUMION swaps a failed GPU with a healthy one and restarts the ML job within ~ 1 second of the failure. LUMION achieves higher inter-GPU bandwidth compared to traditional electrical racks after replacing failed accelerators with spare ones, leading to nearly 2X improvement in fine-tuning throughput.
Accelerating AllReduce with a Persistent Straggler
May 29, 2025Distributed machine learning workloads use data and tensor parallelism for training and inference, both of which rely on the AllReduce collective to synchronize gradients or activations. However, bulk-synchronous AllReduce algorithms can be delayed by a persistent straggler that is slower to reach the synchronization barrier required to begin the collective. To address this challenge, we propose StragglAR: an AllReduce algorithm that accelerates distributed training and inference in the presence of persistent stragglers. StragglAR implements a ReduceScatter among the remaining GPUs during the straggler-induced delay, and then executes a novel collective algorithm to complete the AllReduce once the straggler reaches the synchronization barrier. StragglAR achieves a 2x theoretical speedup over popular bandwidth-efficient AllReduce algorithms (e.g., Ring) for large GPU clusters with persistent stragglers. On an 8-GPU server, our implementation of StragglAR yields a 22% speedup over state-of-the-art AllReduce algorithms.
Teal: Learning-Accelerated Optimization of Traffic Engineering
Oct 25, 2022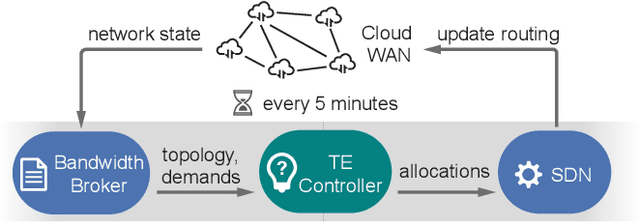
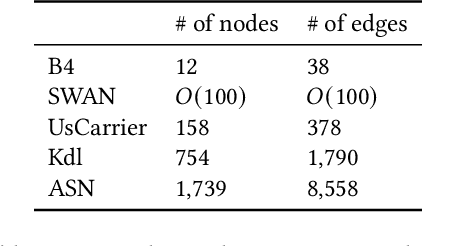
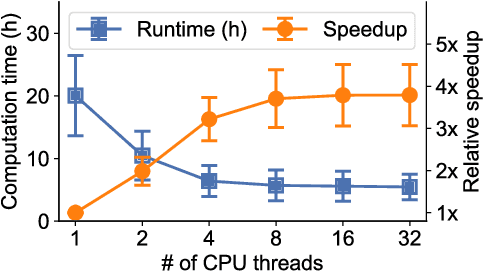

In the last decade, global cloud wide-area networks (WANs) have grown 10$\times$ in size due to the deployment of new network sites and datacenters, making it challenging for commercial optimization engines to solve the network traffic engineering (TE) problem within the temporal budget of a few minutes. In this work, we show that carefully designed deep learning models are key to accelerating the running time of intra-WAN TE systems for large deployments since deep learning is both massively parallel and it benefits from the wealth of historical traffic allocation data from production WANs. However, off-the-shelf deep learning methods fail to perform well on the TE task since they ignore the effects of network connectivity on flow allocations. They are also faced with a tractability challenge posed by the large problem scale of TE optimization. Moreover, neural networks do not have mechanisms to readily enforce hard constraints on model outputs (e.g., link capacity constraints). We tackle these challenges by designing a deep learning-based TE system -- Teal. First, Teal leverages graph neural networks (GNN) to faithfully capture connectivity and model network flows. Second, Teal devises a multi-agent reinforcement learning (RL) algorithm to process individual demands independently in parallel to lower the problem scale. Finally, Teal reduces link capacity violations and improves solution quality using the alternating direction method of multipliers (ADMM). We evaluate Teal on traffic matrices of a global commercial cloud provider and find that Teal computes near-optimal traffic allocations with a 59$\times$ speedup over state-of-the-art TE systems on a WAN topology of over 1,500 nodes.
Synthesizing Collective Communication Algorithms for Heterogeneous Networks with TACCL
Nov 15, 2021
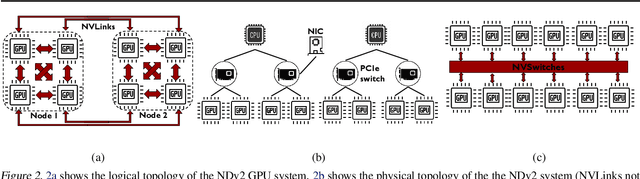
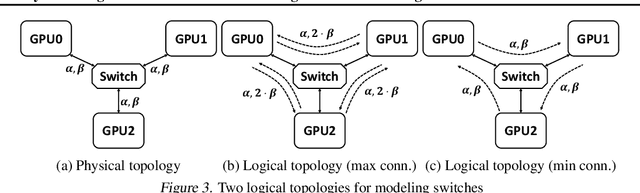
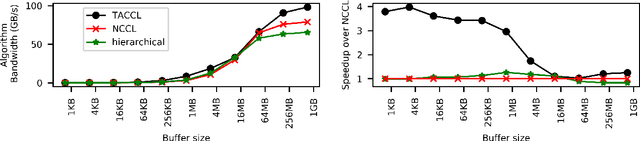
Large ML models and datasets have necessitated the use of multi-GPU systems for distributed model training. To harness the power offered by multi-GPU systems, it is critical to eliminate bottlenecks in inter-GPU communication - a problem made challenging by the heterogeneous nature of interconnects. In this work, we present TACCL, a synthesizer for collective communication primitives for large-scale multi-GPU systems. TACCL encodes a profiled topology and input size into a synthesis problem to generate optimized communication algorithms. TACCL is built on top of the standard NVIDIA Collective Communication Library (NCCL), allowing it to be a drop-in replacement for GPU communication in frameworks like PyTorch with minimal changes. TACCL generates algorithms for communication primitives like Allgather, Alltoall, and Allreduce that are up to $3\times$ faster than NCCL. Using TACCL's algorithms speeds up the end-to-end training of an internal mixture of experts model by $17\%$. By decomposing the optimization problem into parts and leveraging the symmetry in multi-GPU topologies, TACCL synthesizes collectives for up to 80-GPUs in less than 3 minutes, at least two orders of magnitude faster than other synthesis-based state-of-the-art collective communication libraries.