 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-reasoning Technical Report
Apr 30, 2025We introduce Phi-4-reasoning, a 14-billion parameter reasoning model that achieves strong performance on complex reasoning tasks. Trained via supervised fine-tuning of Phi-4 on carefully curated set of "teachable" prompts-selected for the right level of complexity and diversity-and reasoning demonstrations generated using o3-mini, Phi-4-reasoning generates detailed reasoning chains that effectively leverage inference-time compute. We further develop Phi-4-reasoning-plus, a variant enhanced through a short phase of outcome-based reinforcement learning that offers higher performance by generating longer reasoning traces. Across a wide range of reasoning tasks, both models outperform significantly larger open-weight models such as DeepSeek-R1-Distill-Llama-70B model and approach the performance levels of full DeepSeek-R1 model. Our comprehensive evaluations span benchmarks in math and scientific reasoning, coding, algorithmic problem solving, planning, and spatial understanding. Interestingly, we observe a non-trivial transfer of improvements to general-purpose benchmarks as well. In this report, we provide insights into our training data, our training methodologies, and our evaluations. We show that the benefit of careful data curation for supervised fine-tuning (SFT) extends to reasoning language models, and can be further amplified by reinforcement learning (RL). Finally, our evaluation points to opportunities for improving how we assess the performance and robustness of reasoning models.
MSCCL++: Rethinking GPU Communication Abstractions for Cutting-edge AI Applications
Apr 11, 2025

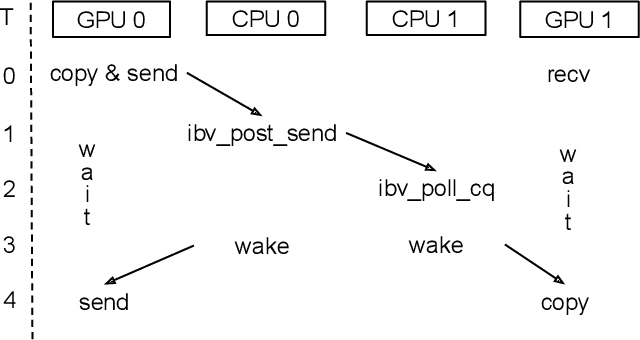
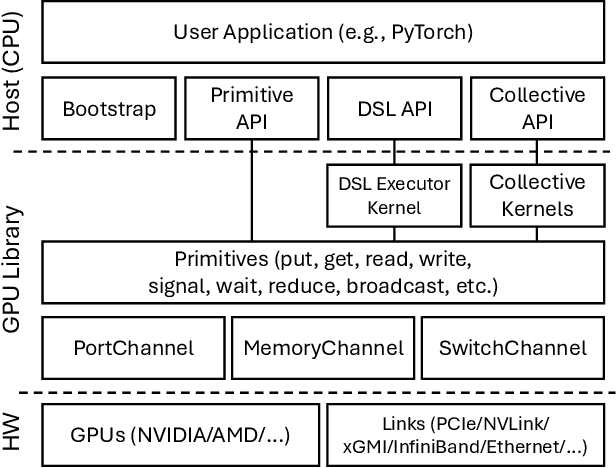
Modern cutting-edge AI applications are being developed over fast-evolving, heterogeneous, nascent hardware devices. This requires frequent reworking of the AI software stack to adopt bottom-up changes from new hardware, which takes time for general-purpose software libraries. Consequently, real applications often develop custom software stacks optimized for their specific workloads and hardware. Custom stacks help quick development and optimization, but incur a lot of redundant efforts across applications in writing non-portable code. This paper discusses an alternative communication library interface for AI applications that offers both portability and performance by reducing redundant efforts while maintaining flexibility for customization. We present MSCCL++, a novel abstraction of GPU communication based on separation of concerns: (1) a primitive interface provides a minimal hardware abstraction as a common ground for software and hardware developers to write custom communication, and (2) higher-level portable interfaces and specialized implementations enable optimization for different hardware environments. This approach makes the primitive interface reusable across applications while enabling highly flexible optimization. Compared to state-of-the-art baselines (NCCL, RCCL, and MSCCL), MSCCL++ achieves speedups of up to 3.8$\times$ for collective communication and up to 15\% for real-world AI inference workloads. MSCCL++ is in production of multiple AI services provided by Microsoft Azure, and is also adopted by RCCL, the GPU collective communication library maintained by AMD. MSCCL++ is open-source and available at https://github.com/microsoft/mscclpp.
Phi-4 Technical Report
Dec 12, 2024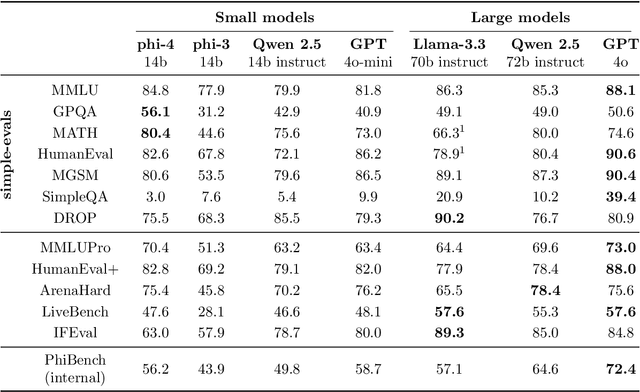
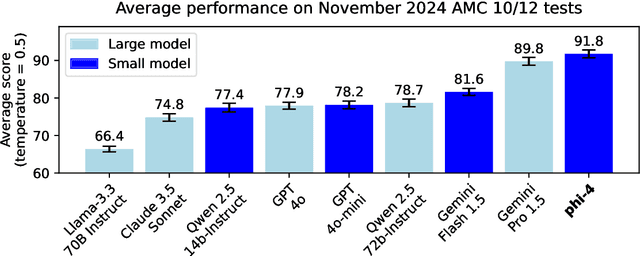

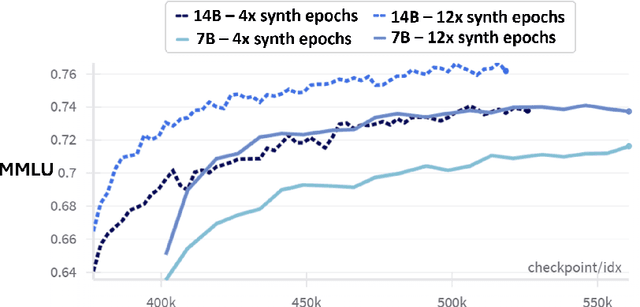
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Tessel: Boosting Distributed Execution of Large DNN Models via Flexible Schedule Search
Nov 26, 2023Increasingly complex and diverse deep neural network (DNN) models necessitate distributing the execution across multiple devices for training and inference tasks, and also require carefully planned schedules for performance. However, existing practices often rely on predefined schedules that may not fully exploit the benefits of emerging diverse model-aware operator placement strategies. Handcrafting high-efficiency schedules can be challenging due to the large and varying schedule space. This paper presents Tessel, an automated system that searches for efficient schedules for distributed DNN training and inference for diverse operator placement strategies. To reduce search costs, Tessel leverages the insight that the most efficient schedules often exhibit repetitive pattern (repetend) across different data inputs. This leads to a two-phase approach: repetend construction and schedule completion. By exploring schedules for various operator placement strategies, Tessel significantly improves both training and inference performance. Experiments with representative DNN models demonstrate that Tessel achieves up to 5.5x training performance speedup and up to 38% inference latency reduction.
Textbooks Are All You Need
Jun 20, 2023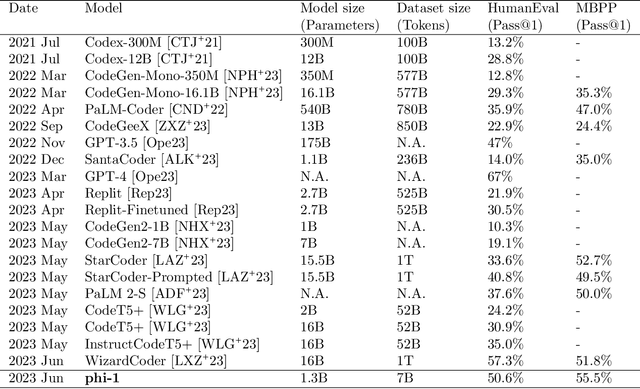
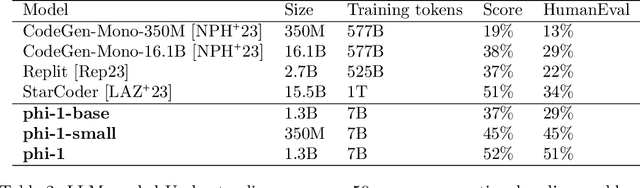
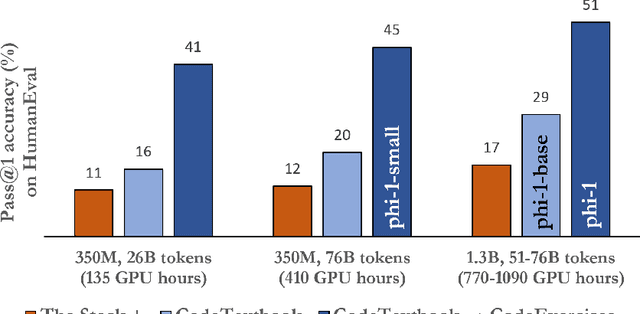
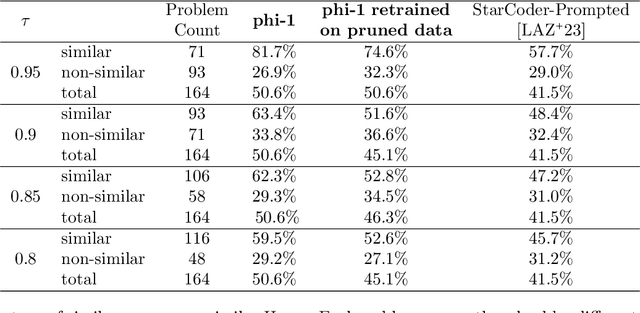
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
Synthesizing Collective Communication Algorithms for Heterogeneous Networks with TACCL
Nov 15, 2021
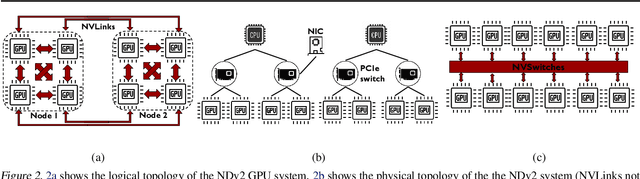
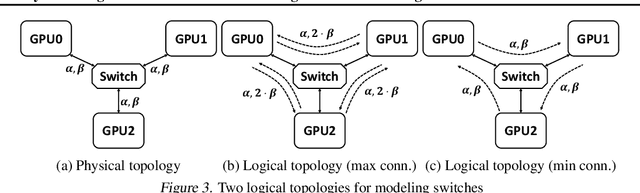
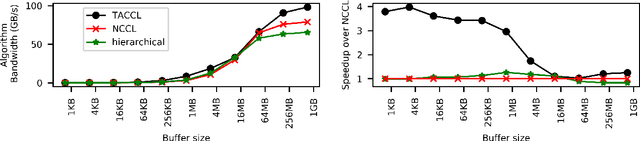
Large ML models and datasets have necessitated the use of multi-GPU systems for distributed model training. To harness the power offered by multi-GPU systems, it is critical to eliminate bottlenecks in inter-GPU communication - a problem made challenging by the heterogeneous nature of interconnects. In this work, we present TACCL, a synthesizer for collective communication primitives for large-scale multi-GPU systems. TACCL encodes a profiled topology and input size into a synthesis problem to generate optimized communication algorithms. TACCL is built on top of the standard NVIDIA Collective Communication Library (NCCL), allowing it to be a drop-in replacement for GPU communication in frameworks like PyTorch with minimal changes. TACCL generates algorithms for communication primitives like Allgather, Alltoall, and Allreduce that are up to $3\times$ faster than NCCL. Using TACCL's algorithms speeds up the end-to-end training of an internal mixture of experts model by $17\%$. By decomposing the optimization problem into parts and leveraging the symmetry in multi-GPU topologies, TACCL synthesizes collectives for up to 80-GPUs in less than 3 minutes, at least two orders of magnitude faster than other synthesis-based state-of-the-art collective communication libraries.
Scaling Distributed Training with Adaptive Summation
Jun 04, 2020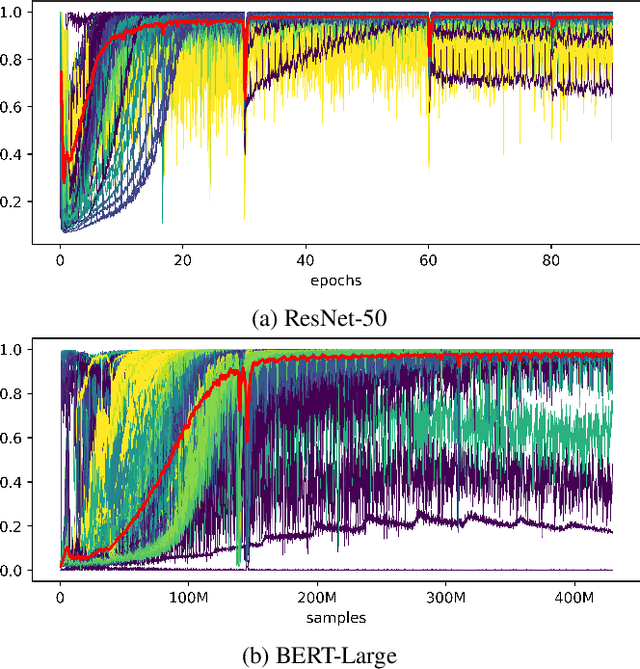
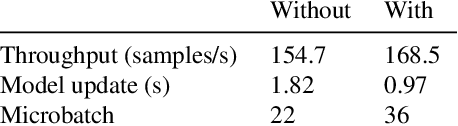
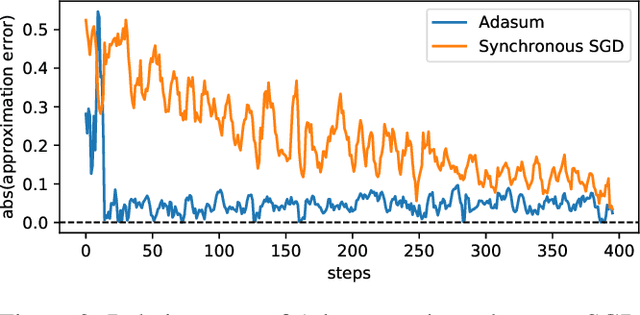

Stochastic gradient descent (SGD) is an inherently sequential training algorithm--computing the gradient at batch $i$ depends on the model parameters learned from batch $i-1$. Prior approaches that break this dependence do not honor them (e.g., sum the gradients for each batch, which is not what sequential SGD would do) and thus potentially suffer from poor convergence. This paper introduces a novel method to combine gradients called Adasum (for adaptive sum) that converges faster than prior work. Adasum is easy to implement, almost as efficient as simply summing gradients, and is integrated into the open-source toolkit Horovod. This paper first provides a formal justification for Adasum and then empirically demonstrates Adasum is more accurate than prior gradient accumulation methods. It then introduces a series of case-studies to show Adasum works with multiple frameworks, (TensorFlow and PyTorch), scales multiple optimizers (Momentum-SGD, Adam, and LAMB) to larger batch-sizes while still giving good downstream accuracy. Finally, it proves that Adasum converges. To summarize, Adasum scales Momentum-SGD on the MLPerf Resnet50 benchmark to 64K examples before communication (no MLPerf v0.5 entry converged with more than 16K), the Adam optimizer to 64K examples before communication on BERT-LARGE (prior work showed Adam stopped scaling at 16K), and the LAMB optimizer to 128K before communication on BERT-LARGE (prior work used 64K), all while maintaining downstream accuracy metrics. Finally, if a user does not need to scale, we show LAMB with Adasum on BERT-LARGE converges in 30% fewer steps than the baseline.
EVA: An Encrypted Vector Arithmetic Language and Compiler for Efficient Homomorphic Computation
Dec 27, 2019
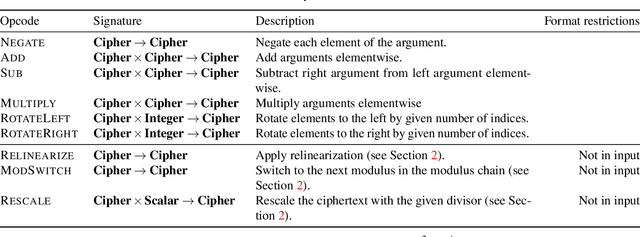
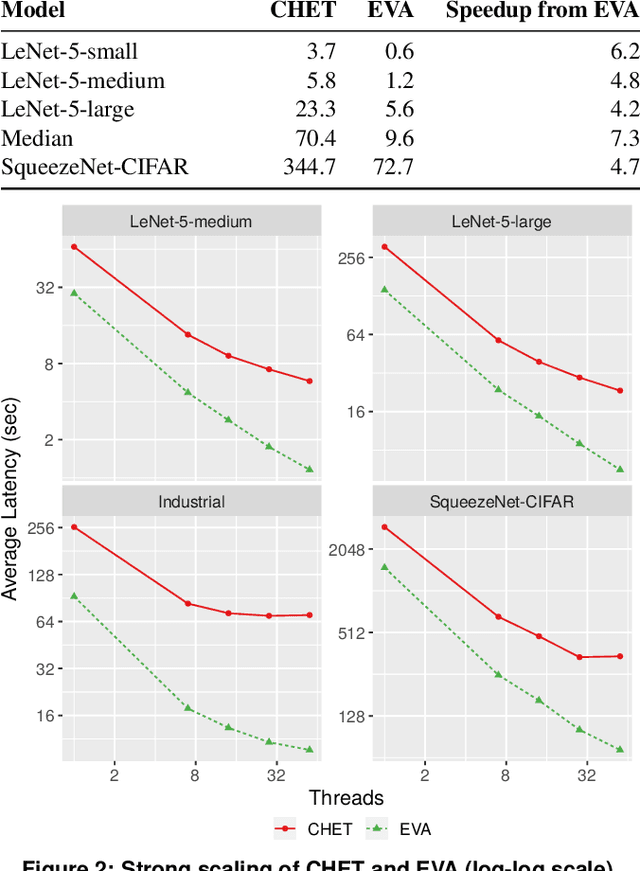
Fully-Homomorphic Encryption (FHE) offers powerful capabilities by enabling secure offloading of both storage and computation, and recent innovations in schemes and implementation have made it all the more attractive. At the same time, FHE is notoriously hard to use with a very constrained programming model, a very unusual performance profile, and many cryptographic constraints. Existing compilers for FHE either target simpler but less efficient FHE schemes or only support specific domains where they can rely on expert provided high-level runtimes to hide complications. This paper presents a new FHE language called Encrypted Vector Arithmetic (EVA), which includes an optimizing compiler that generates correct and secure FHE programs, while hiding all the complexities of the target FHE scheme. Bolstered by our optimizing compiler, programmers can develop efficient general purpose FHE applications directly in EVA. For example, we have developed image processing applications using EVA, with very few lines of code. EVA is designed to also work as an intermediate representation that can be a target for compiling higher-level domain-specific languages. To demonstrate this we have re-targeted CHET, an existing domain-specific compiler for neural network inference, onto EVA. Due to the novel optimizations in EVA, its programs are on average 5.3x faster than those generated by CHET. We believe EVA would enable a wider adoption of FHE by making it easier to develop FHE applications and domain-specific FHE compilers.
Distributed Word2Vec using Graph Analytics Frameworks
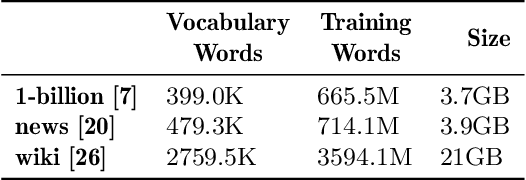
Sep 08, 2019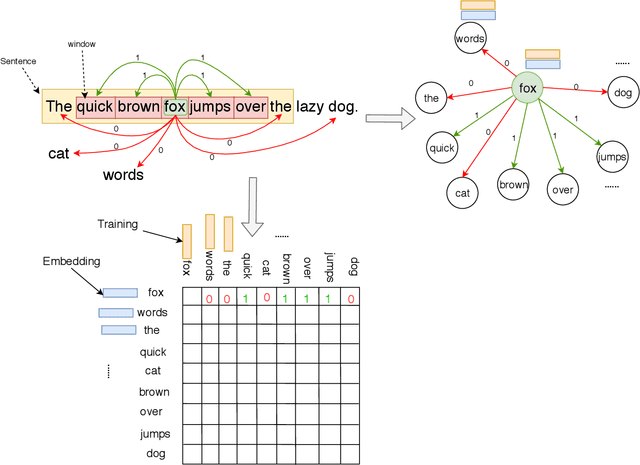
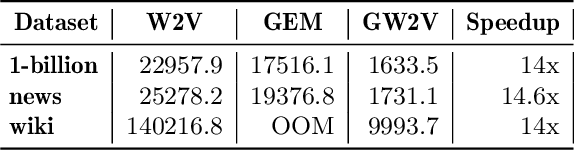
Word embeddings capture semantic and syntactic similarities of words, represented as vectors. Word2Vec is a popular implementation of word embeddings; it takes as input a large corpus of text and learns a model that maps unique words in that corpus to other contextually relevant words. After training, Word2Vec's internal vector representation of words in the corpus map unique words to a vector space, which are then used in many downstream tasks. Training these models requires significant computational resources (training time often measured in days) and is difficult to parallelize. Most word embedding training uses stochastic gradient descent (SGD), an "inherently" sequential algorithm where at each step, the processing of the current example depends on the parameters learned from the previous examples. Prior approaches to parallelizing SGD do not honor these dependencies and thus potentially suffer poor convergence. This paper introduces GraphWord2Vec, a distributedWord2Vec algorithm which formulates the Word2Vec training process as a distributed graph problem and thus leverage state-of-the-art distributed graph analytics frameworks such as D-Galois and Gemini that scale to large distributed clusters. GraphWord2Vec also demonstrates how to use model combiners to honor data dependencies in SGD and thus scale without giving up convergence. We will show that GraphWord2Vec has linear scalability up to 32 machines converging as fast as a sequential run in terms of epochs, thus reducing training time by 14x.