 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Specific Pruning with LLM-Sieve: How Many Parameters Does Your Task Really Need?
May 23, 2025



As Large Language Models (LLMs) are increasingly being adopted for narrow tasks - such as medical question answering or sentiment analysis - and deployed in resource-constrained settings, a key question arises: how many parameters does a task actually need? In this work, we present LLM-Sieve, the first comprehensive framework for task-specific pruning of LLMs that achieves 20-75% parameter reduction with only 1-5% accuracy degradation across diverse domains. Unlike prior methods that apply uniform pruning or rely on low-rank approximations of weight matrices or inputs in isolation, LLM-Sieve (i) learns task-aware joint projections to better approximate output behavior, and (ii) employs a Genetic Algorithm to discover differentiated pruning levels for each matrix. LLM-Sieve is fully compatible with LoRA fine-tuning and quantization, and uniquely demonstrates strong generalization across datasets within the same task domain. Together, these results establish a practical and robust mechanism to generate smaller performant task-specific models.
MSCCL++: Rethinking GPU Communication Abstractions for Cutting-edge AI Applications
Apr 11, 2025

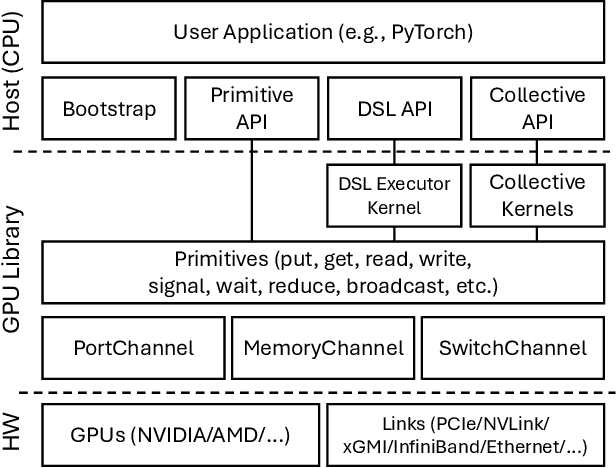
Modern cutting-edge AI applications are being developed over fast-evolving, heterogeneous, nascent hardware devices. This requires frequent reworking of the AI software stack to adopt bottom-up changes from new hardware, which takes time for general-purpose software libraries. Consequently, real applications often develop custom software stacks optimized for their specific workloads and hardware. Custom stacks help quick development and optimization, but incur a lot of redundant efforts across applications in writing non-portable code. This paper discusses an alternative communication library interface for AI applications that offers both portability and performance by reducing redundant efforts while maintaining flexibility for customization. We present MSCCL++, a novel abstraction of GPU communication based on separation of concerns: (1) a primitive interface provides a minimal hardware abstraction as a common ground for software and hardware developers to write custom communication, and (2) higher-level portable interfaces and specialized implementations enable optimization for different hardware environments. This approach makes the primitive interface reusable across applications while enabling highly flexible optimization. Compared to state-of-the-art baselines (NCCL, RCCL, and MSCCL), MSCCL++ achieves speedups of up to 3.8$\times$ for collective communication and up to 15\% for real-world AI inference workloads. MSCCL++ is in production of multiple AI services provided by Microsoft Azure, and is also adopted by RCCL, the GPU collective communication library maintained by AMD. MSCCL++ is open-source and available at https://github.com/microsoft/mscclpp.
Knowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs
Aug 22, 2023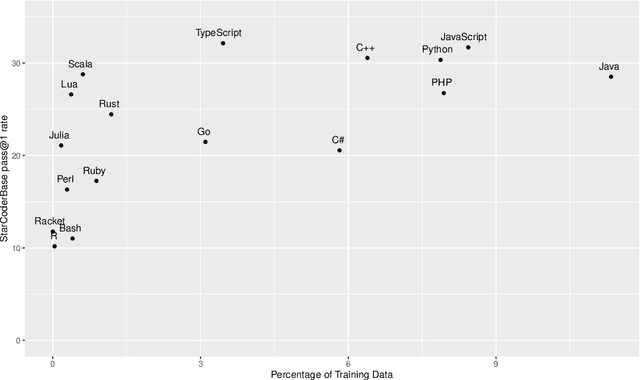

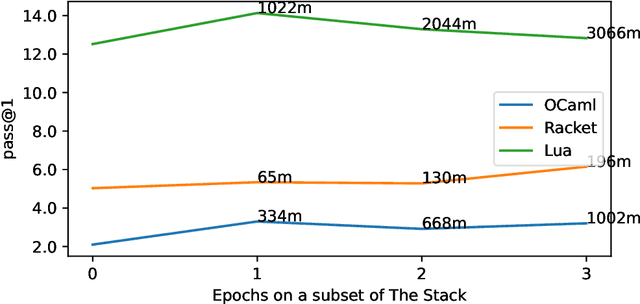
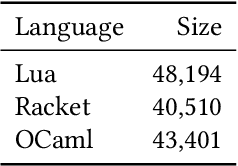
Over the past few years, Large Language Models of Code (Code LLMs) have started to have a significant impact on programming practice. Code LLMs are also emerging as a building block for research in programming languages and software engineering. However, the quality of code produced by a Code LLM varies significantly by programming languages. Code LLMs produce impressive results on programming languages that are well represented in their training data (e.g., Java, Python, or JavaScript), but struggle with low-resource languages, like OCaml and Racket. This paper presents an effective approach for boosting the performance of Code LLMs on low-resource languages using semi-synthetic data. Our approach generates high-quality datasets for low-resource languages, which can then be used to fine-tune any pretrained Code LLM. Our approach, called MultiPL-T, translates training data from high-resource languages into training data for low-resource languages. We apply our approach to generate tens of thousands of new, validated training items for Racket, OCaml, and Lua from Python. Moreover, we use an open dataset (The Stack) and model (StarCoderBase), which allow us to decontaminate benchmarks and train models on this data without violating the model license. With MultiPL-T generated data, we present fine-tuned versions of StarCoderBase that achieve state-of-the-art performance for Racket, OCaml, and Lua on benchmark problems. For Lua, our fine-tuned model achieves the same performance as StarCoderBase as Python -- a very high-resource language -- on the MultiPL-E benchmarks. For Racket and OCaml, we double their performance on MultiPL-E, bringing their performance close to higher-resource languages such as Ruby and C#.
A Scalable and Extensible Approach to Benchmarking NL2Code for 18 Programming Languages
Aug 19, 2022
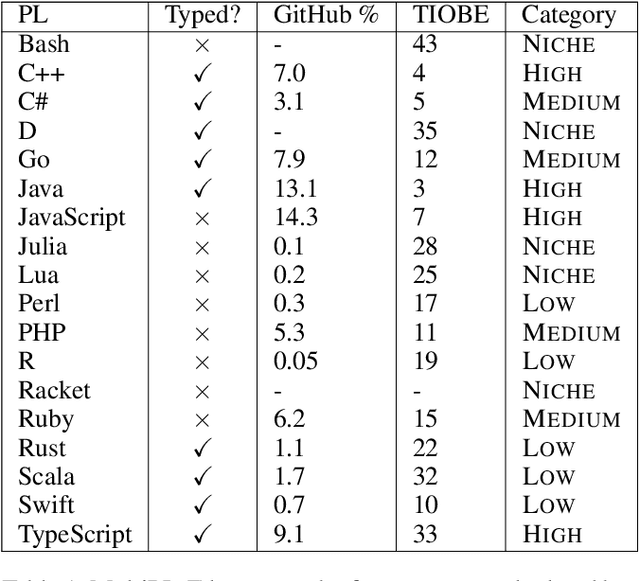

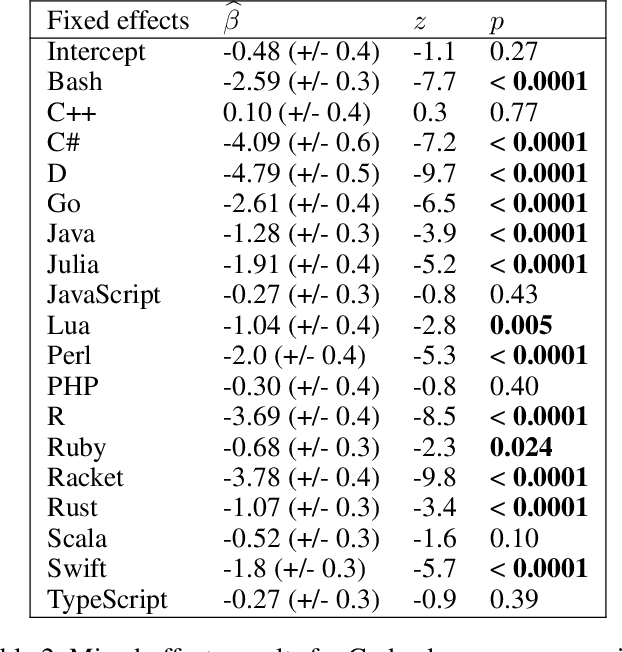
Large language models have demonstrated the ability to condition on and generate both natural language and programming language text. Such models open up the possibility of multi-language code generation: could code generation models generalize knowledge from one language to another? Although contemporary code generation models can generate semantically correct Python code, little is known about their abilities with other languages. We facilitate the exploration of this topic by proposing MultiPL-E, the first multi-language parallel benchmark for natural-language-to-code-generation. MultiPL-E extends the HumanEval benchmark (Chen et al, 2021) to support 18 more programming languages, encompassing a range of programming paradigms and popularity. We evaluate two state-of-the-art code generation models on MultiPL-E: Codex and InCoder. We find that on several languages, Codex matches and even exceeds its performance on Python. The range of programming languages represented in MultiPL-E allow us to explore the impact of language frequency and language features on model performance. Finally, the MultiPL-E approach of compiling code generation benchmarks to new programming languages is both scalable and extensible. We describe a general approach for easily adding support for new benchmarks and languages to MultiPL-E.
CoCoNet: Co-Optimizing Computation and Communication for Distributed Machine Learning
May 13, 2021
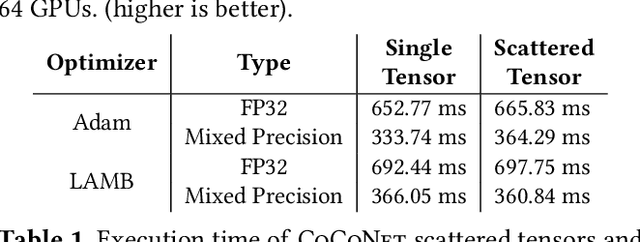

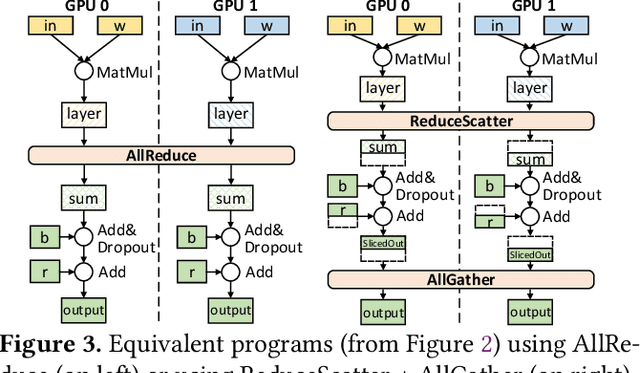
Modern deep learning workloads run on distributed hardware and are difficult to optimize -- data, model, and pipeline parallelism require a developer to thoughtfully restructure their workload around optimized computation and communication kernels in libraries such as cuBLAS and NCCL. The logical separation between computation and communication leaves performance on the table with missed optimization opportunities across abstraction boundaries. To explore these opportunities, this paper presents CoCoNet, which consists of a compute language to express programs with both computation and communication, a scheduling language to apply transformations on such programs, and a compiler to generate high performance kernels. Providing both computation and communication as first class constructs enables new optimizations, such as overlapping or fusion of communication with computation. CoCoNet allowed us to optimize several data, model and pipeline parallel workloads in existing deep learning systems with very few lines of code. We show significant improvements after integrating novel CoCoNet generated kernels.
NextDoor: GPU-Based Graph Sampling for Graph Machine Learning
Sep 17, 2020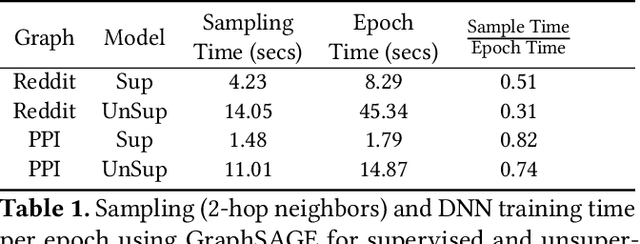


Representation learning is a fundamental task in machine learning. It consists of learning the features of data items automatically, typically using a deep neural network (DNN), instead of selecting hand-engineered features that typically have worse performance. Graph data requires specific algorithms for representation learning such as DeepWalk, node2vec, and GraphSAGE. These algorithms first sample the input graph and then train a DNN based on the samples. It is common to use GPUs for training, but graph sampling on GPUs is challenging. Sampling is an embarrassingly parallel task since each sample can be generated independently. However, the irregularity of graphs makes it hard to use GPU resources effectively. Existing graph processing, mining, and representation learning systems do not effectively parallelize sampling and this negatively impacts the end-to-end performance of representation learning. In this paper, we present NextDoor, the first system specifically designed to perform graph sampling on GPUs. NextDoor introduces a high-level API based on a novel paradigm for parallel graph sampling called transit-parallelism. We implement several graph sampling applications, and show that NextDoor runs them orders of magnitude faster than existing systems
Predicting Variable Types in Dynamically Typed Programming Languages
Jan 16, 2019



Dynamic Programming Languages are quite popular because they increase the programmer's productivity. However, the absence of types in the source code makes the program written in these languages difficult to understand and virtual machines that execute these programs cannot produced optimized code. To overcome this challenge, we develop a technique to predict types of all identifiers including variables, and function return types. We propose the first implementation of $2^{nd}$ order Inside Outside Recursive Neural Networks with two variants (i) Child-Sum Tree-LSTMs and (ii) N-ary RNNs that can handle large number of tree branching. We predict the types of all the identifiers given the Abstract Syntax Tree by performing just two passes over the tree, bottom-up and top-down, keeping both the content and context representation for all the nodes of the tree. This allows these representations to interact by combining different paths from the parent, siblings and children which is crucial for predicting types. Our best model achieves 44.33\% across 21 classes and top-3 accuracy of 71.5\% on our gathered Python data set from popular Python benchmarks.