 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhD Knowledge Not Required: A Reasoning Challenge for Large Language Models
Feb 03, 2025



Existing benchmarks for frontier models often test specialized, ``PhD-level'' knowledge that is difficult for non-experts to grasp. In contrast, we present a benchmark based on the NPR Sunday Puzzle Challenge that requires only general knowledge. Our benchmark is challenging for both humans and models, however correct solutions are easy to verify, and models' mistakes are easy to spot. Our work reveals capability gaps that are not evident in existing benchmarks: OpenAI o1 significantly outperforms other reasoning models that are on par on benchmarks that test specialized knowledge. Furthermore, our analysis of reasoning outputs uncovers new kinds of failures. DeepSeek R1, for instance, often concedes with ``I give up'' before providing an answer that it knows is wrong. R1 can also be remarkably ``uncertain'' in its output and in rare cases, it does not ``finish thinking,'' which suggests the need for an inference-time technique to ``wrap up'' before the context window limit is reached. We also quantify the effectiveness of reasoning longer with R1 and Gemini Thinking to identify the point beyond which more reasoning is unlikely to improve accuracy on our benchmark.
NNsight and NDIF: Democratizing Access to Foundation Model Internals
Jul 18, 2024



The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists, because customized experiments at large model sizes require costly hardware and complex engineering that is impractical for most researchers. To alleviate these problems, we introduce NNsight, an open-source Python package with a simple, flexible API that can express interventions on any PyTorch model by building computation graphs. We also introduce NDIF, a collaborative research platform providing researchers access to foundation-scale LLMs via the NNsight API. Code, documentation, and tutorials are available at https://www.nnsight.net.
Activation Steering for Robust Type Prediction in CodeLLMs
Apr 02, 2024



Contemporary LLMs pretrained on code are capable of succeeding at a wide variety of programming tasks. However, their performance is very sensitive to syntactic features, such as the names of variables and types, the structure of code, and presence of type hints. We contribute an inference-time technique to make CodeLLMs more robust to syntactic distractors that are semantically irrelevant. Our methodology relies on activation steering, which involves editing internal model activations to steer the model towards the correct prediction. We contribute a novel way to construct steering vectors by taking inspiration from mutation testing, which constructs minimal semantics-breaking code edits. In contrast, we construct steering vectors from semantics-preserving code edits. We apply our approach to the task of type prediction for the gradually typed languages Python and TypeScript. This approach corrects up to 90% of type mispredictions. Finally, we show that steering vectors calculated from Python activations reliably correct type mispredictions in TypeScript, and vice versa. This result suggests that LLMs may be learning to transfer knowledge of types across programming languages.
Deploying and Evaluating LLMs to Program Service Mobile Robots
Nov 18, 2023



Recent advancements in large language models (LLMs) have spurred interest in using them for generating robot programs from natural language, with promising initial results. We investigate the use of LLMs to generate programs for service mobile robots leveraging mobility, perception, and human interaction skills, and where accurate sequencing and ordering of actions is crucial for success. We contribute CodeBotler, an open-source robot-agnostic tool to program service mobile robots from natural language, and RoboEval, a benchmark for evaluating LLMs' capabilities of generating programs to complete service robot tasks. CodeBotler performs program generation via few-shot prompting of LLMs with an embedded domain-specific language (eDSL) in Python, and leverages skill abstractions to deploy generated programs on any general-purpose mobile robot. RoboEval evaluates the correctness of generated programs by checking execution traces starting with multiple initial states, and checking whether the traces satisfy temporal logic properties that encode correctness for each task. RoboEval also includes multiple prompts per task to test for the robustness of program generation. We evaluate several popular state-of-the-art LLMs with the RoboEval benchmark, and perform a thorough analysis of the modes of failures, resulting in a taxonomy that highlights common pitfalls of LLMs at generating robot programs. We release our code and benchmark at https://amrl.cs.utexas.edu/codebotler/.
Knowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs
Aug 22, 2023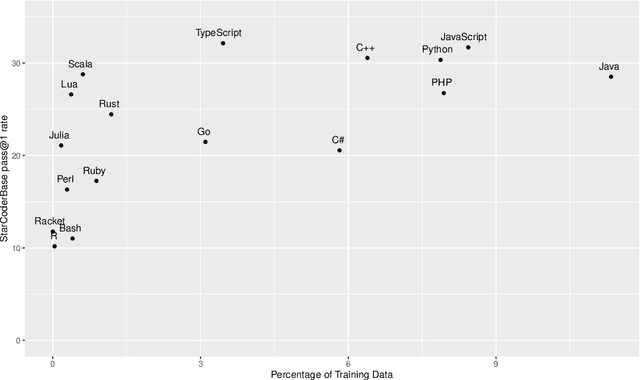

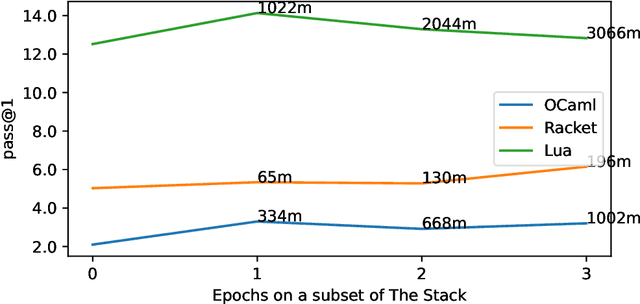
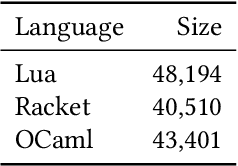
Over the past few years, Large Language Models of Code (Code LLMs) have started to have a significant impact on programming practice. Code LLMs are also emerging as a building block for research in programming languages and software engineering. However, the quality of code produced by a Code LLM varies significantly by programming languages. Code LLMs produce impressive results on programming languages that are well represented in their training data (e.g., Java, Python, or JavaScript), but struggle with low-resource languages, like OCaml and Racket. This paper presents an effective approach for boosting the performance of Code LLMs on low-resource languages using semi-synthetic data. Our approach generates high-quality datasets for low-resource languages, which can then be used to fine-tune any pretrained Code LLM. Our approach, called MultiPL-T, translates training data from high-resource languages into training data for low-resource languages. We apply our approach to generate tens of thousands of new, validated training items for Racket, OCaml, and Lua from Python. Moreover, we use an open dataset (The Stack) and model (StarCoderBase), which allow us to decontaminate benchmarks and train models on this data without violating the model license. With MultiPL-T generated data, we present fine-tuned versions of StarCoderBase that achieve state-of-the-art performance for Racket, OCaml, and Lua on benchmark problems. For Lua, our fine-tuned model achieves the same performance as StarCoderBase as Python -- a very high-resource language -- on the MultiPL-E benchmarks. For Racket and OCaml, we double their performance on MultiPL-E, bringing their performance close to higher-resource languages such as Ruby and C#.