 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs
Paper and Code
Aug 22, 2023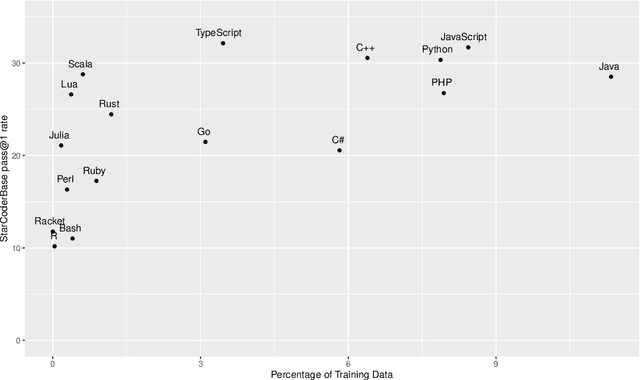

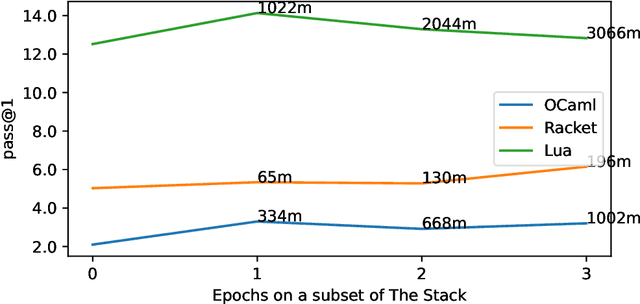
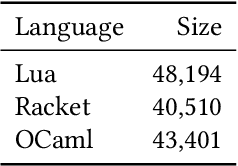
Over the past few years, Large Language Models of Code (Code LLMs) have started to have a significant impact on programming practice. Code LLMs are also emerging as a building block for research in programming languages and software engineering. However, the quality of code produced by a Code LLM varies significantly by programming languages. Code LLMs produce impressive results on programming languages that are well represented in their training data (e.g., Java, Python, or JavaScript), but struggle with low-resource languages, like OCaml and Racket. This paper presents an effective approach for boosting the performance of Code LLMs on low-resource languages using semi-synthetic data. Our approach generates high-quality datasets for low-resource languages, which can then be used to fine-tune any pretrained Code LLM. Our approach, called MultiPL-T, translates training data from high-resource languages into training data for low-resource languages. We apply our approach to generate tens of thousands of new, validated training items for Racket, OCaml, and Lua from Python. Moreover, we use an open dataset (The Stack) and model (StarCoderBase), which allow us to decontaminate benchmarks and train models on this data without violating the model license. With MultiPL-T generated data, we present fine-tuned versions of StarCoderBase that achieve state-of-the-art performance for Racket, OCaml, and Lua on benchmark problems. For Lua, our fine-tuned model achieves the same performance as StarCoderBase as Python -- a very high-resource language -- on the MultiPL-E benchmarks. For Racket and OCaml, we double their performance on MultiPL-E, bringing their performance close to higher-resource languages such as Ruby and C#.