 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgnostics: Learning to Code in Any Programming Language via Reinforcement with a Universal Learning Environment
Aug 06, 2025Large language models (LLMs) already excel at writing code in high-resource languages such as Python and JavaScript, yet stumble on low-resource languages that remain essential to science and engineering. Besides the obvious shortage of pre-training data, post-training itself is a bottleneck: every new language seems to require new datasets, test harnesses, and reinforcement-learning (RL) infrastructure. We introduce Agnostics, a language-agnostic post-training pipeline that eliminates this per-language engineering. The key idea is to judge code solely by its externally observable behavior, so a single verifier can test solutions written in any language. Concretely, we (i) use an LLM to rewrite existing unit-test datasets into an I/O format, (ii) supply a short configuration that tells the verifier how to compile and run a target language, and (iii) apply reinforcement learning with verifiable rewards (RLVR) in a robust code execution environment. Applied to five low-resource languages--Lua, Julia, R, OCaml, and Fortran--Agnostics (1) improves Qwen-3 4B to performance that rivals other 16B-70B open-weight models; (2) scales cleanly to larger and diverse model families (Qwen-3 8B, DeepSeek Coder 6.7B Instruct, Phi 4 Mini); and (3) for ${\le} 16$B parameter models, sets new state-of-the-art pass@1 results on MultiPL-E and a new multi-language version LiveCodeBench that we introduce. We will release the language-agnostic training datasets (Ag-MBPP-X, Ag-Codeforces-X, Ag-LiveCodeBench-X), training code, and ready-to-use configurations, making RL post-training in any programming language as simple as editing a short YAML file.
PhD Knowledge Not Required: A Reasoning Challenge for Large Language Models
Feb 03, 2025



Existing benchmarks for frontier models often test specialized, ``PhD-level'' knowledge that is difficult for non-experts to grasp. In contrast, we present a benchmark based on the NPR Sunday Puzzle Challenge that requires only general knowledge. Our benchmark is challenging for both humans and models, however correct solutions are easy to verify, and models' mistakes are easy to spot. Our work reveals capability gaps that are not evident in existing benchmarks: OpenAI o1 significantly outperforms other reasoning models that are on par on benchmarks that test specialized knowledge. Furthermore, our analysis of reasoning outputs uncovers new kinds of failures. DeepSeek R1, for instance, often concedes with ``I give up'' before providing an answer that it knows is wrong. R1 can also be remarkably ``uncertain'' in its output and in rare cases, it does not ``finish thinking,'' which suggests the need for an inference-time technique to ``wrap up'' before the context window limit is reached. We also quantify the effectiveness of reasoning longer with R1 and Gemini Thinking to identify the point beyond which more reasoning is unlikely to improve accuracy on our benchmark.
Evaluating Computational Representations of Character: An Austen Character Similarity Benchmark
Aug 28, 2024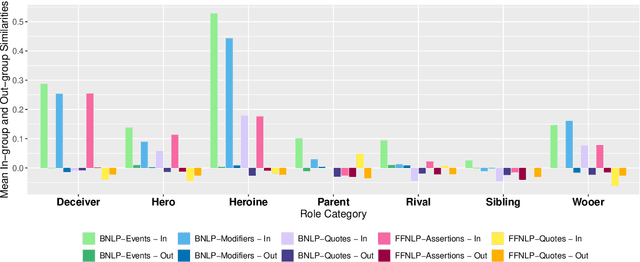



Several systems have been developed to extract information about characters to aid computational analysis of English literature. We propose character similarity grouping as a holistic evaluation task for these pipelines. We present AustenAlike, a benchmark suite of character similarities in Jane Austen's novels. Our benchmark draws on three notions of character similarity: a structurally defined notion of similarity; a socially defined notion of similarity; and an expert defined set extracted from literary criticism. We use AustenAlike to evaluate character features extracted using two pipelines, BookNLP and FanfictionNLP. We build character representations from four kinds of features and compare them to the three AustenAlike benchmarks and to GPT-4 similarity rankings. We find that though computational representations capture some broad similarities based on shared social and narrative roles, the expert pairings in our third benchmark are challenging for all systems, highlighting the subtler aspects of similarity noted by human readers.
GlyphPattern: An Abstract Pattern Recognition for Vision-Language Models
Aug 12, 2024
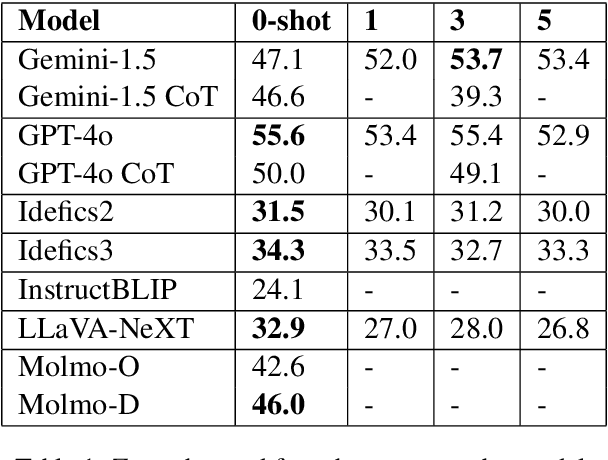
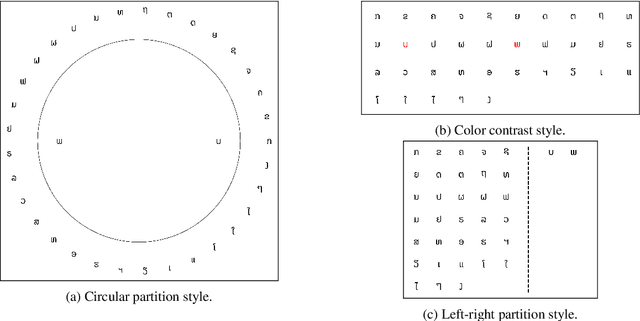
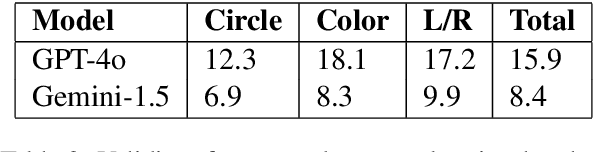
Vision-Language Models (VLMs) building upon the foundation of powerful large language models have made rapid progress in reasoning across visual and textual data. While VLMs perform well on vision tasks that they are trained on, our results highlight key challenges in abstract pattern recognition. We present GlyphPattern, a 954 item dataset that pairs 318 human-written descriptions of visual patterns from 40 writing systems with three visual presentation styles. GlyphPattern evaluates abstract pattern recognition in VLMs, requiring models to understand and judge natural language descriptions of visual patterns. GlyphPattern patterns are drawn from a large-scale cognitive science investigation of human writing systems; as a result, they are rich in spatial reference and compositionality. Our experiments show that GlyphPattern is challenging for state-of-the-art VLMs (GPT-4o achieves only 55% accuracy), with marginal gains from few-shot prompting. Our detailed error analysis reveals challenges at multiple levels, including visual processing, natural language understanding, and pattern generalization.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
Can It Edit? Evaluating the Ability of Large Language Models to Follow Code Editing Instructions
Dec 29, 2023A significant amount of research is focused on developing and evaluating large language models for a variety of code synthesis tasks. These include synthesizing code from natural language instructions, synthesizing tests from code, and synthesizing explanations of code. In contrast, the behavior of instructional code editing with LLMs is understudied. These are tasks in which the model is instructed to update a block of code provided in a prompt. The editing instruction may ask for a feature to added or removed, describe a bug and ask for a fix, ask for a different kind of solution, or many other common code editing tasks. We introduce a carefully crafted benchmark of code editing tasks and use it evaluate several cutting edge LLMs. Our evaluation exposes a significant gap between the capabilities of state-of-the-art open and closed models. For example, even GPT-3.5-Turbo is 8.8% better than the best open model at editing code. We also introduce a new, carefully curated, permissively licensed training set of code edits coupled with natural language instructions. Using this training set, we show that we can fine-tune open Code LLMs to significantly improve their code editing capabilities.
Knowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs
Aug 22, 2023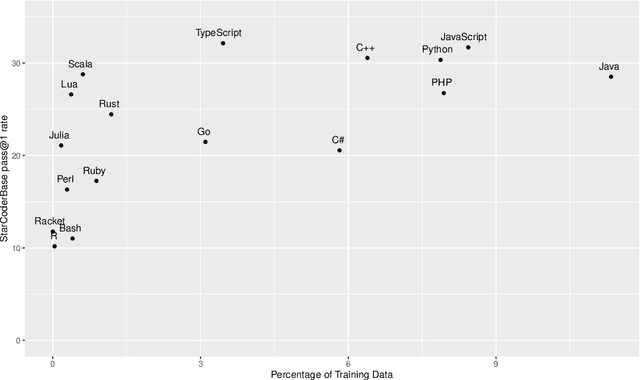

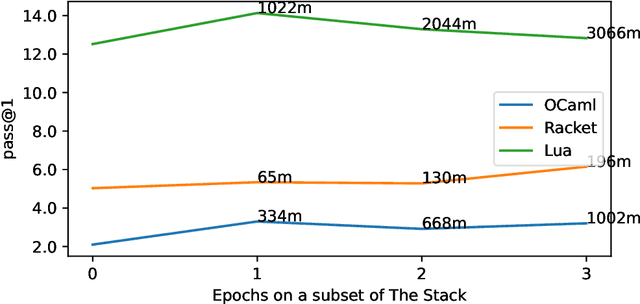
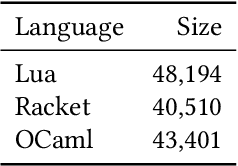
Over the past few years, Large Language Models of Code (Code LLMs) have started to have a significant impact on programming practice. Code LLMs are also emerging as a building block for research in programming languages and software engineering. However, the quality of code produced by a Code LLM varies significantly by programming languages. Code LLMs produce impressive results on programming languages that are well represented in their training data (e.g., Java, Python, or JavaScript), but struggle with low-resource languages, like OCaml and Racket. This paper presents an effective approach for boosting the performance of Code LLMs on low-resource languages using semi-synthetic data. Our approach generates high-quality datasets for low-resource languages, which can then be used to fine-tune any pretrained Code LLM. Our approach, called MultiPL-T, translates training data from high-resource languages into training data for low-resource languages. We apply our approach to generate tens of thousands of new, validated training items for Racket, OCaml, and Lua from Python. Moreover, we use an open dataset (The Stack) and model (StarCoderBase), which allow us to decontaminate benchmarks and train models on this data without violating the model license. With MultiPL-T generated data, we present fine-tuned versions of StarCoderBase that achieve state-of-the-art performance for Racket, OCaml, and Lua on benchmark problems. For Lua, our fine-tuned model achieves the same performance as StarCoderBase as Python -- a very high-resource language -- on the MultiPL-E benchmarks. For Racket and OCaml, we double their performance on MultiPL-E, bringing their performance close to higher-resource languages such as Ruby and C#.
Solving and Generating NPR Sunday Puzzles with Large Language Models
Jun 21, 2023We explore the ability of large language models to solve and generate puzzles from the NPR Sunday Puzzle game show using PUZZLEQA, a dataset comprising 15 years of on-air puzzles. We evaluate four large language models using PUZZLEQA, in both multiple choice and free response formats, and explore two prompt engineering techniques to improve free response performance: chain-of-thought reasoning and prompt summarization. We find that state-of-the-art large language models can solve many PUZZLEQA puzzles: the best model, GPT-3.5, achieves 50.2% loose accuracy. However, in our few-shot puzzle generation experiment, we find no evidence that models can generate puzzles: GPT-3.5 generates puzzles with answers that do not conform to the generated rules. Puzzle generation remains a challenging task for future work.
StudentEval: A Benchmark of Student-Written Prompts for Large Language Models of Code
Jun 07, 2023



Code LLMs are being rapidly deployed and there is evidence that they can make professional programmers more productive. Current benchmarks for code generation measure whether models generate correct programs given an expert prompt. In this paper, we present a new benchmark containing multiple prompts per problem, written by a specific population of non-expert prompters: beginning programmers. StudentEval contains 1,749 prompts for 48 problems, written by 80 students who have only completed one semester of Python programming. Our students wrote these prompts while working interactively with a Code LLM, and we observed very mixed success rates. We use StudentEval to evaluate 5 Code LLMs and find that StudentEval is a better discriminator of model performance than existing benchmarks. We analyze the prompts and find significant variation in students' prompting techniques. We also find that nondeterministic LLM sampling could mislead students into thinking that their prompts are more (or less) effective than they actually are, which has implications for how to teach with Code LLMs.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.