 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$τ$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Jun 17, 2024Existing benchmarks do not test language agents on their interaction with human users or ability to follow domain-specific rules, both of which are vital for deploying them in real world applications. We propose $\tau$-bench, a benchmark emulating dynamic conversations between a user (simulated by language models) and a language agent provided with domain-specific API tools and policy guidelines. We employ an efficient and faithful evaluation process that compares the database state at the end of a conversation with the annotated goal state. We also propose a new metric (pass^k) to evaluate the reliability of agent behavior over multiple trials. Our experiments show that even state-of-the-art function calling agents (like gpt-4o) succeed on <50% of the tasks, and are quite inconsistent (pass^8 <25% in retail). Our findings point to the need for methods that can improve the ability of agents to act consistently and follow rules reliably.
Can It Edit? Evaluating the Ability of Large Language Models to Follow Code Editing Instructions
Dec 29, 2023A significant amount of research is focused on developing and evaluating large language models for a variety of code synthesis tasks. These include synthesizing code from natural language instructions, synthesizing tests from code, and synthesizing explanations of code. In contrast, the behavior of instructional code editing with LLMs is understudied. These are tasks in which the model is instructed to update a block of code provided in a prompt. The editing instruction may ask for a feature to added or removed, describe a bug and ask for a fix, ask for a different kind of solution, or many other common code editing tasks. We introduce a carefully crafted benchmark of code editing tasks and use it evaluate several cutting edge LLMs. Our evaluation exposes a significant gap between the capabilities of state-of-the-art open and closed models. For example, even GPT-3.5-Turbo is 8.8% better than the best open model at editing code. We also introduce a new, carefully curated, permissively licensed training set of code edits coupled with natural language instructions. Using this training set, we show that we can fine-tune open Code LLMs to significantly improve their code editing capabilities.
Type Prediction With Program Decomposition and Fill-in-the-Type Training
May 25, 2023

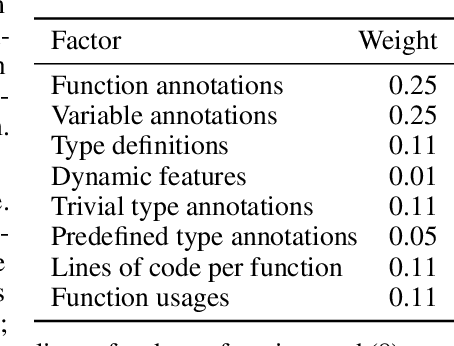
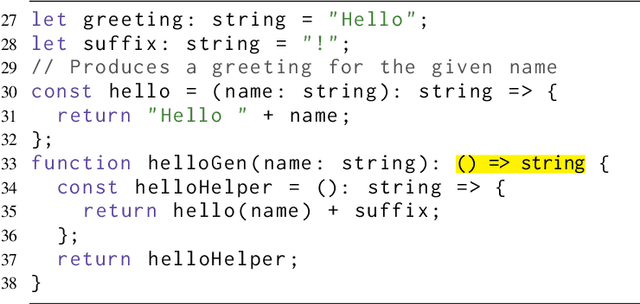
TypeScript and Python are two programming languages that support optional type annotations, which are useful but tedious to introduce and maintain. This has motivated automated type prediction: given an untyped program, produce a well-typed output program. Large language models (LLMs) are promising for type prediction, but there are challenges: fill-in-the-middle performs poorly, programs may not fit into the context window, generated types may not type check, and it is difficult to measure how well-typed the output program is. We address these challenges by building OpenTau, a search-based approach for type prediction that leverages large language models. We propose a new metric for type prediction quality, give a tree-based program decomposition that searches a space of generated types, and present fill-in-the-type fine-tuning for LLMs. We evaluate our work with a new dataset for TypeScript type prediction, and show that 47.4% of files type check (14.5% absolute improvement) with an overall rate of 3.3 type errors per file. All code, data, and models are available at: https://github.com/GammaTauAI/opentau.
Reflexion: an autonomous agent with dynamic memory and self-reflection
Mar 20, 2023



Recent advancements in decision-making large language model (LLM) agents have demonstrated impressive performance across various benchmarks. However, these state-of-the-art approaches typically necessitate internal model fine-tuning, external model fine-tuning, or policy optimization over a defined state space. Implementing these methods can prove challenging due to the scarcity of high-quality training data or the lack of well-defined state space. Moreover, these agents do not possess certain qualities inherent to human decision-making processes, specifically the ability to learn from mistakes. Self-reflection allows humans to efficiently solve novel problems through a process of trial and error. Building on recent research, we propose Reflexion, an approach that endows an agent with dynamic memory and self-reflection capabilities to enhance its existing reasoning trace and task-specific action choice abilities. To achieve full automation, we introduce a straightforward yet effective heuristic that enables the agent to pinpoint hallucination instances, avoid repetition in action sequences, and, in some environments, construct an internal memory map of the given environment. To assess our approach, we evaluate the agent's ability to complete decision-making tasks in AlfWorld environments and knowledge-intensive, search-based question-and-answer tasks in HotPotQA environments. We observe success rates of 97% and 51%, respectively, and provide a discussion on the emergent property of self-reflection.