 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlyphPattern: An Abstract Pattern Recognition for Vision-Language Models
Aug 12, 2024
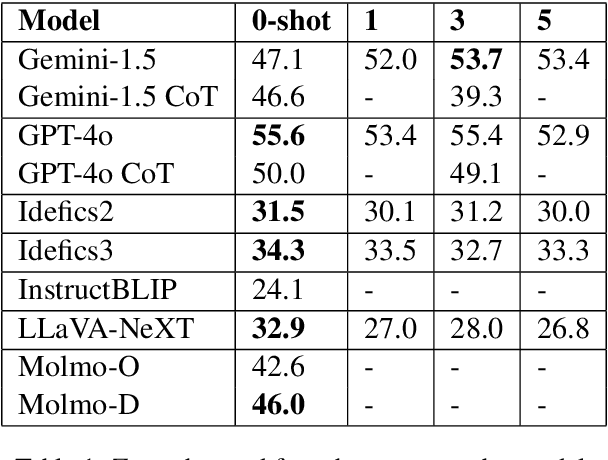
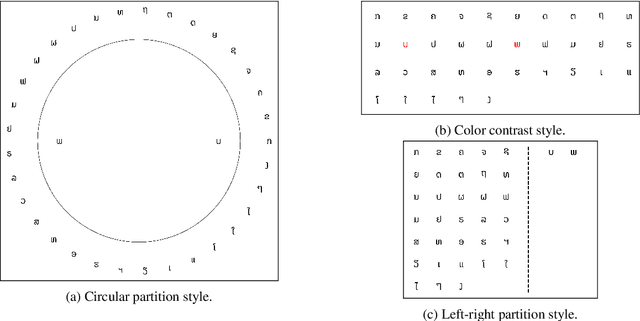
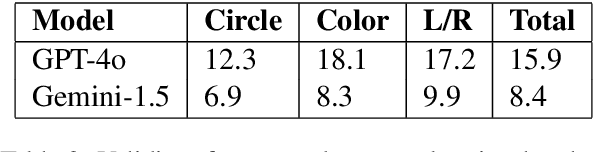
Vision-Language Models (VLMs) building upon the foundation of powerful large language models have made rapid progress in reasoning across visual and textual data. While VLMs perform well on vision tasks that they are trained on, our results highlight key challenges in abstract pattern recognition. We present GlyphPattern, a 954 item dataset that pairs 318 human-written descriptions of visual patterns from 40 writing systems with three visual presentation styles. GlyphPattern evaluates abstract pattern recognition in VLMs, requiring models to understand and judge natural language descriptions of visual patterns. GlyphPattern patterns are drawn from a large-scale cognitive science investigation of human writing systems; as a result, they are rich in spatial reference and compositionality. Our experiments show that GlyphPattern is challenging for state-of-the-art VLMs (GPT-4o achieves only 55% accuracy), with marginal gains from few-shot prompting. Our detailed error analysis reveals challenges at multiple levels, including visual processing, natural language understanding, and pattern generalization.