 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Incomplete Coarse-Grained to Complete Fine-Grained: A Two-Stage Framework for Spatiotemporal Data Reconstruction
Oct 05, 2024With the rapid development of various sensing devices, spatiotemporal data is becoming increasingly important nowadays. However, due to sensing costs and privacy concerns, the collected data is often incomplete and coarse-grained, limiting its application to specific tasks. To address this, we propose a new task called spatiotemporal data reconstruction, which aims to infer complete and fine-grained data from sparse and coarse-grained observations. To achieve this, we introduce a two-stage data inference framework, DiffRecon, grounded in the Denoising Diffusion Probabilistic Model (DDPM). In the first stage, we present Diffusion-C, a diffusion model augmented by ST-PointFormer, a powerful encoder designed to leverage the spatial correlations between sparse data points. Following this, the second stage introduces Diffusion-F, which incorporates the proposed T-PatternNet to capture the temporal pattern within sequential data. Together, these two stages form an end-to-end framework capable of inferring complete, fine-grained data from incomplete and coarse-grained observations. We conducted experiments on multiple real-world datasets to demonstrate the superiority of our method.
Evaluating Computational Representations of Character: An Austen Character Similarity Benchmark
Aug 28, 2024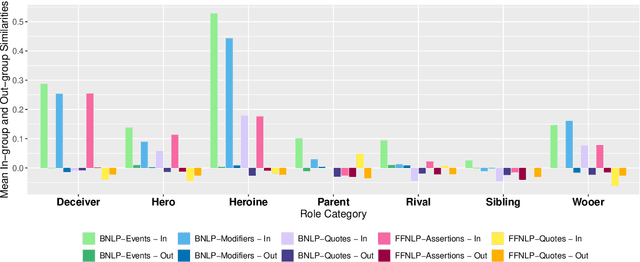



Several systems have been developed to extract information about characters to aid computational analysis of English literature. We propose character similarity grouping as a holistic evaluation task for these pipelines. We present AustenAlike, a benchmark suite of character similarities in Jane Austen's novels. Our benchmark draws on three notions of character similarity: a structurally defined notion of similarity; a socially defined notion of similarity; and an expert defined set extracted from literary criticism. We use AustenAlike to evaluate character features extracted using two pipelines, BookNLP and FanfictionNLP. We build character representations from four kinds of features and compare them to the three AustenAlike benchmarks and to GPT-4 similarity rankings. We find that though computational representations capture some broad similarities based on shared social and narrative roles, the expert pairings in our third benchmark are challenging for all systems, highlighting the subtler aspects of similarity noted by human readers.
Curriculum Dataset Distillation
May 15, 2024



Most dataset distillation methods struggle to accommodate large-scale datasets due to their substantial computational and memory requirements. In this paper, we present a curriculum-based dataset distillation framework designed to harmonize scalability with efficiency. This framework strategically distills synthetic images, adhering to a curriculum that transitions from simple to complex. By incorporating curriculum evaluation, we address the issue of previous methods generating images that tend to be homogeneous and simplistic, doing so at a manageable computational cost. Furthermore, we introduce adversarial optimization towards synthetic images to further improve their representativeness and safeguard against their overfitting to the neural network involved in distilling. This enhances the generalization capability of the distilled images across various neural network architectures and also increases their robustness to noise. Extensive experiments demonstrate that our framework sets new benchmarks in large-scale dataset distillation, achieving substantial improvements of 11.1\% on Tiny-ImageNet, 9.0\% on ImageNet-1K, and 7.3\% on ImageNet-21K. The source code will be released to the community.