 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCP: Accelerating Discovery with a Global Web of Autonomous Scientific Agents
Dec 30, 2025We introduce SCP: the Science Context Protocol, an open-source standard designed to accelerate discovery by enabling a global network of autonomous scientific agents. SCP is built on two foundational pillars: (1) Unified Resource Integration: At its core, SCP provides a universal specification for describing and invoking scientific resources, spanning software tools, models, datasets, and physical instruments. This protocol-level standardization enables AI agents and applications to discover, call, and compose capabilities seamlessly across disparate platforms and institutional boundaries. (2) Orchestrated Experiment Lifecycle Management: SCP complements the protocol with a secure service architecture, which comprises a centralized SCP Hub and federated SCP Servers. This architecture manages the complete experiment lifecycle (registration, planning, execution, monitoring, and archival), enforces fine-grained authentication and authorization, and orchestrates traceable, end-to-end workflows that bridge computational and physical laboratories. Based on SCP, we have constructed a scientific discovery platform that offers researchers and agents a large-scale ecosystem of more than 1,600 tool resources. Across diverse use cases, SCP facilitates secure, large-scale collaboration between heterogeneous AI systems and human researchers while significantly reducing integration overhead and enhancing reproducibility. By standardizing scientific context and tool orchestration at the protocol level, SCP establishes essential infrastructure for scalable, multi-institution, agent-driven science.
PRISM: A Framework Harnessing Unsupervised Visual Representations and Textual Prompts for Explainable MACE Survival Prediction from Cardiac Cine MRI
Aug 26, 2025Accurate prediction of major adverse cardiac events (MACE) remains a central challenge in cardiovascular prognosis. We present PRISM (Prompt-guided Representation Integration for Survival Modeling), a self-supervised framework that integrates visual representations from non-contrast cardiac cine magnetic resonance imaging with structured electronic health records (EHRs) for survival analysis. PRISM extracts temporally synchronized imaging features through motion-aware multi-view distillation and modulates them using medically informed textual prompts to enable fine-grained risk prediction. Across four independent clinical cohorts, PRISM consistently surpasses classical survival prediction models and state-of-the-art (SOTA) deep learning baselines under internal and external validation. Further clinical findings demonstrate that the combined imaging and EHR representations derived from PRISM provide valuable insights into cardiac risk across diverse cohorts. Three distinct imaging signatures associated with elevated MACE risk are uncovered, including lateral wall dyssynchrony, inferior wall hypersensitivity, and anterior elevated focus during diastole. Prompt-guided attribution further identifies hypertension, diabetes, and smoking as dominant contributors among clinical and physiological EHR factors.
CTSL: Codebook-based Temporal-Spatial Learning for Accurate Non-Contrast Cardiac Risk Prediction Using Cine MRIs
Jul 22, 2025Accurate and contrast-free Major Adverse Cardiac Events (MACE) prediction from Cine MRI sequences remains a critical challenge. Existing methods typically necessitate supervised learning based on human-refined masks in the ventricular myocardium, which become impractical without contrast agents. We introduce a self-supervised framework, namely Codebook-based Temporal-Spatial Learning (CTSL), that learns dynamic, spatiotemporal representations from raw Cine data without requiring segmentation masks. CTSL decouples temporal and spatial features through a multi-view distillation strategy, where the teacher model processes multiple Cine views, and the student model learns from reduced-dimensional Cine-SA sequences. By leveraging codebook-based feature representations and dynamic lesion self-detection through motion cues, CTSL captures intricate temporal dependencies and motion patterns. High-confidence MACE risk predictions are achieved through our model, providing a rapid, non-invasive solution for cardiac risk assessment that outperforms traditional contrast-dependent methods, thereby enabling timely and accessible heart disease diagnosis in clinical settings.
A Composite Alignment-Aware Framework for Myocardial Lesion Segmentation in Multi-sequence CMR Images
Jul 16, 2025Accurate segmentation of myocardial lesions from multi-sequence cardiac magnetic resonance imaging is essential for cardiac disease diagnosis and treatment planning. However, achieving optimal feature correspondence is challenging due to intensity variations across modalities and spatial misalignment caused by inconsistent slice acquisition protocols. We propose CAA-Seg, a composite alignment-aware framework that addresses these challenges through a two-stage approach. First, we introduce a selective slice alignment method that dynamically identifies and aligns anatomically corresponding slice pairs while excluding mismatched sections, ensuring reliable spatial correspondence between sequences. Second, we develop a hierarchical alignment network that processes multi-sequence features at different semantic levels, i.e., local deformation correction modules address geometric variations in low-level features, while global semantic fusion blocks enable semantic fusion at high levels where intensity discrepancies diminish. We validate our method on a large-scale dataset comprising 397 patients. Experimental results show that our proposed CAA-Seg achieves superior performance on most evaluation metrics, with particularly strong results in myocardial infarction segmentation, representing a substantial 5.54% improvement over state-of-the-art approaches. The code is available at https://github.com/yifangao112/CAA-Seg.
CardioCoT: Hierarchical Reasoning for Multimodal Survival Analysis
May 25, 2025


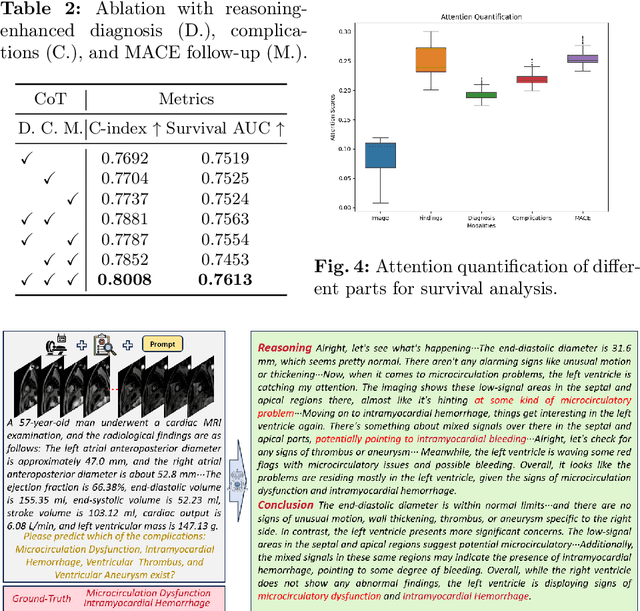
Accurate prediction of major adverse cardiovascular events recurrence risk in acute myocardial infarction patients based on postoperative cardiac MRI and associated clinical notes is crucial for precision treatment and personalized intervention. Existing methods primarily focus on risk stratification capability while overlooking the need for intermediate robust reasoning and model interpretability in clinical practice. Moreover, end-to-end risk prediction using LLM/VLM faces significant challenges due to data limitations and modeling complexity. To bridge this gap, we propose CardioCoT, a novel two-stage hierarchical reasoning-enhanced survival analysis framework designed to enhance both model interpretability and predictive performance. In the first stage, we employ an evidence-augmented self-refinement mechanism to guide LLM/VLMs in generating robust hierarchical reasoning trajectories based on associated radiological findings. In the second stage, we integrate the reasoning trajectories with imaging data for risk model training and prediction. CardioCoT demonstrates superior performance in MACE recurrence risk prediction while providing interpretable reasoning processes, offering valuable insights for clinical decision-making.
SeedBench: A Multi-task Benchmark for Evaluating Large Language Models in Seed Science
May 19, 2025Seed science is essential for modern agriculture, directly influencing crop yields and global food security. However, challenges such as interdisciplinary complexity and high costs with limited returns hinder progress, leading to a shortage of experts and insufficient technological support. While large language models (LLMs) have shown promise across various fields, their application in seed science remains limited due to the scarcity of digital resources, complex gene-trait relationships, and the lack of standardized benchmarks. To address this gap, we introduce SeedBench -- the first multi-task benchmark specifically designed for seed science. Developed in collaboration with domain experts, SeedBench focuses on seed breeding and simulates key aspects of modern breeding processes. We conduct a comprehensive evaluation of 26 leading LLMs, encompassing proprietary, open-source, and domain-specific fine-tuned models. Our findings not only highlight the substantial gaps between the power of LLMs and the real-world seed science problems, but also make a foundational step for research on LLMs for seed design.
AI-Driven Automation Can Become the Foundation of Next-Era Science of Science Research
May 17, 2025The Science of Science (SoS) explores the mechanisms underlying scientific discovery, and offers valuable insights for enhancing scientific efficiency and fostering innovation. Traditional approaches often rely on simplistic assumptions and basic statistical tools, such as linear regression and rule-based simulations, which struggle to capture the complexity and scale of modern research ecosystems. The advent of artificial intelligence (AI) presents a transformative opportunity for the next generation of SoS, enabling the automation of large-scale pattern discovery and uncovering insights previously unattainable. This paper offers a forward-looking perspective on the integration of Science of Science with AI for automated research pattern discovery and highlights key open challenges that could greatly benefit from AI. We outline the advantages of AI over traditional methods, discuss potential limitations, and propose pathways to overcome them. Additionally, we present a preliminary multi-agent system as an illustrative example to simulate research societies, showcasing AI's ability to replicate real-world research patterns and accelerate progress in Science of Science research.
Towards Efficient and Intelligent Laser Weeding: Method and Dataset for Weed Stem Detection
Feb 10, 2025



Weed control is a critical challenge in modern agriculture, as weeds compete with crops for essential nutrient resources, significantly reducing crop yield and quality. Traditional weed control methods, including chemical and mechanical approaches, have real-life limitations such as associated environmental impact and efficiency. An emerging yet effective approach is laser weeding, which uses a laser beam as the stem cutter. Although there have been studies that use deep learning in weed recognition, its application in intelligent laser weeding still requires a comprehensive understanding. Thus, this study represents the first empirical investigation of weed recognition for laser weeding. To increase the efficiency of laser beam cut and avoid damaging the crops of interest, the laser beam shall be directly aimed at the weed root. Yet, weed stem detection remains an under-explored problem. We integrate the detection of crop and weed with the localization of weed stem into one end-to-end system. To train and validate the proposed system in a real-life scenario, we curate and construct a high-quality weed stem detection dataset with human annotations. The dataset consists of 7,161 high-resolution pictures collected in the field with annotations of 11,151 instances of weed. Experimental results show that the proposed system improves weeding accuracy by 6.7% and reduces energy cost by 32.3% compared to existing weed recognition systems.
Two Heads Are Better Than One: A Multi-Agent System Has the Potential to Improve Scientific Idea Generation
Oct 12, 2024



The rapid advancement of scientific progress requires innovative tools that can accelerate discovery. While recent AI methods, particularly large language models (LLMs), have shown promise in tasks such as hypothesis generation and experimental design, they fall short in replicating the collaborative nature of real-world scientific practices, where diverse teams of experts work together to tackle complex problems. To address the limitation, we propose an LLM-based multi-agent system, i.e., Virtual Scientists (VirSci), designed to mimic the teamwork inherent in scientific research. VirSci organizes a team of agents to collaboratively generate, evaluate, and refine research ideas. Through comprehensive experiments, we demonstrate that this multi-agent approach outperforms the state-of-the-art method in producing novel and impactful scientific ideas, showing potential in aligning with key insights in the Science of Science field. Our findings suggest that integrating collaborative agents can lead to more innovative scientific outputs, offering a robust system for autonomous scientific discovery.
From Incomplete Coarse-Grained to Complete Fine-Grained: A Two-Stage Framework for Spatiotemporal Data Reconstruction
Oct 05, 2024With the rapid development of various sensing devices, spatiotemporal data is becoming increasingly important nowadays. However, due to sensing costs and privacy concerns, the collected data is often incomplete and coarse-grained, limiting its application to specific tasks. To address this, we propose a new task called spatiotemporal data reconstruction, which aims to infer complete and fine-grained data from sparse and coarse-grained observations. To achieve this, we introduce a two-stage data inference framework, DiffRecon, grounded in the Denoising Diffusion Probabilistic Model (DDPM). In the first stage, we present Diffusion-C, a diffusion model augmented by ST-PointFormer, a powerful encoder designed to leverage the spatial correlations between sparse data points. Following this, the second stage introduces Diffusion-F, which incorporates the proposed T-PatternNet to capture the temporal pattern within sequential data. Together, these two stages form an end-to-end framework capable of inferring complete, fine-grained data from incomplete and coarse-grained observations. We conducted experiments on multiple real-world datasets to demonstrate the superiority of our method.