 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedBench: A Multi-task Benchmark for Evaluating Large Language Models in Seed Science
May 19, 2025Seed science is essential for modern agriculture, directly influencing crop yields and global food security. However, challenges such as interdisciplinary complexity and high costs with limited returns hinder progress, leading to a shortage of experts and insufficient technological support. While large language models (LLMs) have shown promise across various fields, their application in seed science remains limited due to the scarcity of digital resources, complex gene-trait relationships, and the lack of standardized benchmarks. To address this gap, we introduce SeedBench -- the first multi-task benchmark specifically designed for seed science. Developed in collaboration with domain experts, SeedBench focuses on seed breeding and simulates key aspects of modern breeding processes. We conduct a comprehensive evaluation of 26 leading LLMs, encompassing proprietary, open-source, and domain-specific fine-tuned models. Our findings not only highlight the substantial gaps between the power of LLMs and the real-world seed science problems, but also make a foundational step for research on LLMs for seed design.
HuixiangDou2: A Robustly Optimized GraphRAG Approach
Mar 09, 2025Large Language Models (LLMs) perform well on familiar queries but struggle with specialized or emerging topics. Graph-based Retrieval-Augmented Generation (GraphRAG) addresses this by structuring domain knowledge as a graph for dynamic retrieval. However, existing pipelines involve complex engineering workflows, making it difficult to isolate the impact of individual components. Evaluating retrieval effectiveness is also challenging due to dataset overlap with LLM pretraining data. In this work, we introduce HuixiangDou2, a robustly optimized GraphRAG framework. Specifically, we leverage the effectiveness of dual-level retrieval and optimize its performance in a 32k context for maximum precision, and compare logic-based retrieval and dual-level retrieval to enhance overall functionality. Our implementation includes comparative experiments on a test set, where Qwen2.5-7B-Instruct initially underperformed. With our approach, the score improved significantly from 60 to 74.5, as illustrated in the Figure. Experiments on domain-specific datasets reveal that dual-level retrieval enhances fuzzy matching, while logic-form retrieval improves structured reasoning. Furthermore, we propose a multi-stage verification mechanism to improve retrieval robustness without increasing computational cost. Empirical results show significant accuracy gains over baselines, highlighting the importance of adaptive retrieval. To support research and adoption, we release HuixiangDou2 as an open-source resource https://github.com/tpoisonooo/huixiangdou2.
StepTool: A Step-grained Reinforcement Learning Framework for Tool Learning in LLMs
Oct 10, 2024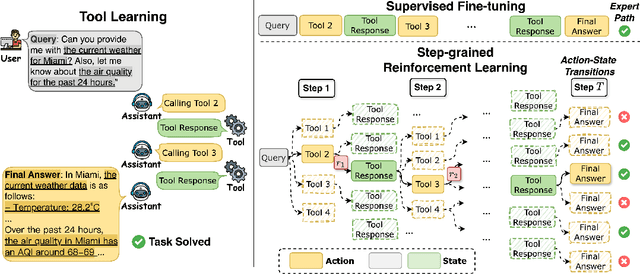

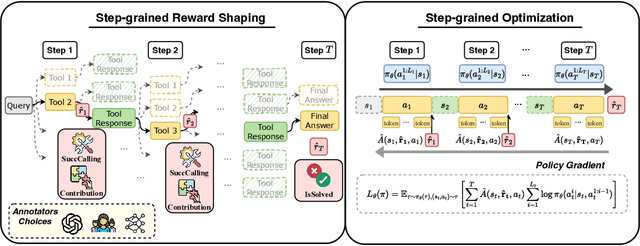
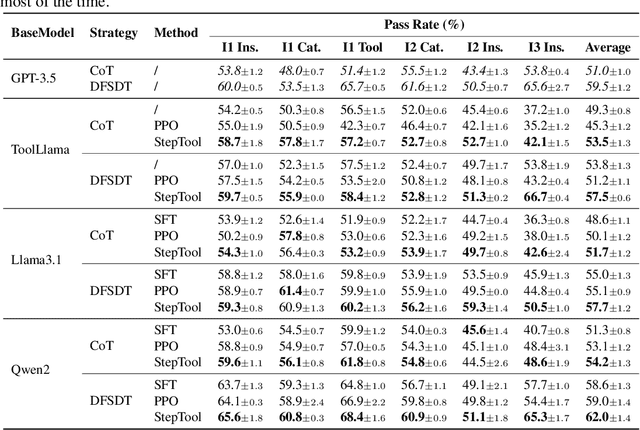
Despite having powerful reasoning and inference capabilities, Large Language Models (LLMs) still need external tools to acquire real-time information retrieval or domain-specific expertise to solve complex tasks, which is referred to as tool learning. Existing tool learning methods primarily rely on tuning with expert trajectories, focusing on token-sequence learning from a linguistic perspective. However, there are several challenges: 1) imitating static trajectories limits their ability to generalize to new tasks. 2) even expert trajectories can be suboptimal, and better solution paths may exist. In this work, we introduce StepTool, a novel step-grained reinforcement learning framework to improve tool learning in LLMs. It consists of two components: Step-grained Reward Shaping, which assigns rewards at each tool interaction based on tool invocation success and its contribution to the task, and Step-grained Optimization, which uses policy gradient methods to optimize the model in a multi-step manner. Experimental results demonstrate that StepTool significantly outperforms existing methods in multi-step, tool-based tasks, providing a robust solution for complex task environments. Codes are available at https://github.com/yuyq18/StepTool.
An Embarrassingly Simple Approach to Enhance Transformer Performance in Genomic Selection for Crop Breeding
May 15, 2024Genomic selection (GS), as a critical crop breeding strategy, plays a key role in enhancing food production and addressing the global hunger crisis. The predominant approaches in GS currently revolve around employing statistical methods for prediction. However, statistical methods often come with two main limitations: strong statistical priors and linear assumptions. A recent trend is to capture the non-linear relationships between markers by deep learning. However, as crop datasets are commonly long sequences with limited samples, the robustness of deep learning models, especially Transformers, remains a challenge. In this work, to unleash the unexplored potential of attention mechanism for the task of interest, we propose a simple yet effective Transformer-based framework that enables end-to-end training of the whole sequence. Via experiments on rice3k and wheat3k datasets, we show that, with simple tricks such as k-mer tokenization and random masking, Transformer can achieve overall superior performance against seminal methods on GS tasks of interest.
To Recommend or Not: Recommendability Identification in Conversations with Pre-trained Language Models
Apr 08, 2024Most current recommender systems primarily focus on what to recommend, assuming users always require personalized recommendations. However, with the widely spread of ChatGPT and other chatbots, a more crucial problem in the context of conversational systems is how to minimize user disruption when we provide recommendation services for users. While previous research has extensively explored different user intents in dialogue systems, fewer efforts are made to investigate whether recommendations should be provided. In this paper, we formally define the recommendability identification problem, which aims to determine whether recommendations are necessary in a specific scenario. First, we propose and define the recommendability identification task, which investigates the need for recommendations in the current conversational context. A new dataset is constructed. Subsequently, we discuss and evaluate the feasibility of leveraging pre-trained language models (PLMs) for recommendability identification. Finally, through comparative experiments, we demonstrate that directly employing PLMs with zero-shot results falls short of meeting the task requirements. Besides, fine-tuning or utilizing soft prompt techniques yields comparable results to traditional classification methods. Our work is the first to study recommendability before recommendation and provides preliminary ways to make it a fundamental component of the future recommendation system.
Multi-Agent Collaboration Framework for Recommender Systems
Feb 23, 2024
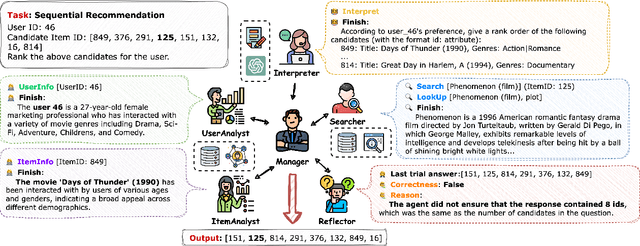


LLM-based agents have gained considerable attention for their decision-making skills and ability to handle complex tasks. Recognizing the current gap in leveraging agent capabilities for multi-agent collaboration in recommendation systems, we introduce MACRec, a novel framework designed to enhance recommendation systems through multi-agent collaboration. Unlike existing work on using agents for user/item simulation, we aim to deploy multi-agents to tackle recommendation tasks directly. In our framework, recommendation tasks are addressed through the collaborative efforts of various specialized agents, including Manager, User/Item Analyst, Reflector, Searcher, and Task Interpreter, with different working flows. Furthermore, we provide application examples of how developers can easily use MACRec on various recommendation tasks, including rating prediction, sequential recommendation, conversational recommendation, and explanation generation of recommendation results. The framework and demonstration video are publicly available at https://github.com/wzf2000/MACRec.
Intent-aware Ranking Ensemble for Personalized Recommendation
Apr 15, 2023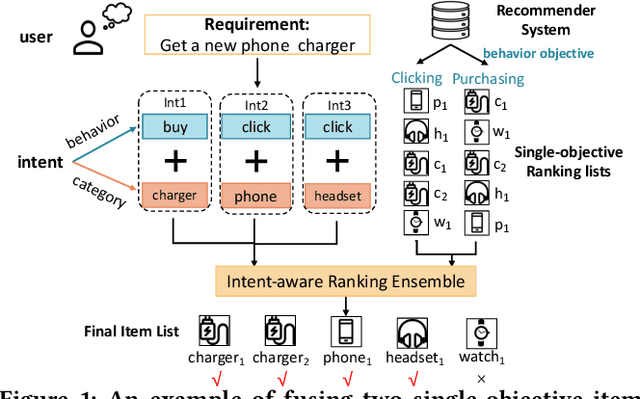

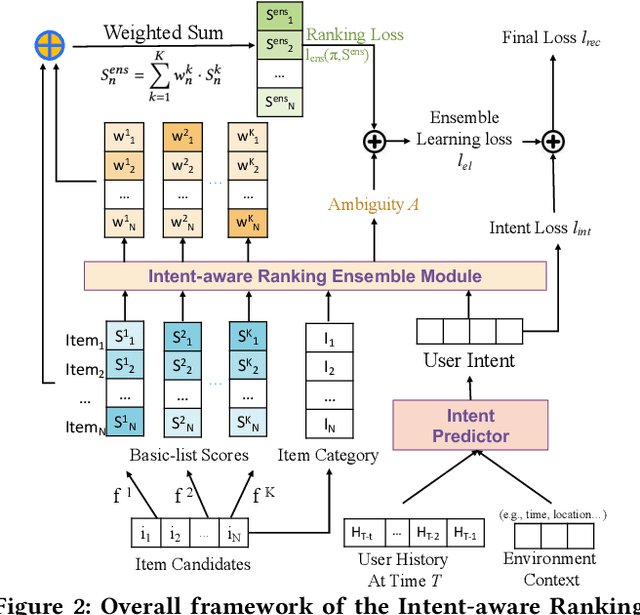
Ranking ensemble is a critical component in real recommender systems. When a user visits a platform, the system will prepare several item lists, each of which is generally from a single behavior objective recommendation model. As multiple behavior intents, e.g., both clicking and buying some specific item category, are commonly concurrent in a user visit, it is necessary to integrate multiple single-objective ranking lists into one. However, previous work on rank aggregation mainly focused on fusing homogeneous item lists with the same objective while ignoring ensemble of heterogeneous lists ranked with different objectives with various user intents. In this paper, we treat a user's possible behaviors and the potential interacting item categories as the user's intent. And we aim to study how to fuse candidate item lists generated from different objectives aware of user intents. To address such a task, we propose an Intent-aware ranking Ensemble Learning~(IntEL) model to fuse multiple single-objective item lists with various user intents, in which item-level personalized weights are learned. Furthermore, we theoretically prove the effectiveness of IntEL with point-wise, pair-wise, and list-wise loss functions via error-ambiguity decomposition. Experiments on two large-scale real-world datasets also show significant improvements of IntEL on multiple behavior objectives simultaneously compared to previous ranking ensemble models.