 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPAO: Adaptive Prefix-Aware Optimization for Generative Recommendation
Mar 03, 2026Generative recommendation has recently emerged as a promising paradigm in sequential recommendation. It formulates the task as an autoregressive generation process, predicting discrete tokens of the next item conditioned on user interaction histories. Existing generative recommendation models are typically trained with token-level likelihood objectives, such as cross-entropy loss, while employing multi-step beam search during inference to generate ranked item candidates. However, this leads to a fundamental training-inference inconsistency: standard training assumes ground-truth history is always available, ignoring the fact that beam search prunes low-probability branches during inference. Consequently, the correct item may be prematurely discarded simply because its initial tokens (prefixes) have low scores. To address this issue, we propose the Adaptive Prefix-Aware Optimization (APAO) framework, which introduces prefix-level optimization losses to better align the training objective with the inference setting. Furthermore, we design an adaptive worst-prefix optimization strategy that dynamically focuses on the most vulnerable prefixes during training, thereby enhancing the model's ability to retain correct candidates under beam search constraints. We provide theoretical analyses to demonstrate the effectiveness and efficiency of our framework. Extensive experiments on multiple datasets further show that APAO consistently alleviates the training-inference inconsistency and improves performance across various generative recommendation backbones. Our codes are publicly available at https://github.com/yuyq18/APAO.
Don't Miss the Forest for the Trees: In-Depth Confidence Estimation for LLMs via Reasoning over the Answer Space
Nov 18, 2025Knowing the reliability of a model's response is essential in application. With the strong generation capabilities of LLMs, research has focused on generating verbalized confidence. This is further enhanced by combining chain-of-thought reasoning, which provides logical and transparent estimation. However, how reasoning strategies affect the estimated confidence is still under-explored. In this work, we demonstrate that predicting a verbalized probability distribution can effectively encourage in-depth reasoning for confidence estimation. Intuitively, it requires an LLM to consider all candidates within the answer space instead of basing on a single guess, and to carefully assign confidence scores to meet the requirements of a distribution. This method shows an advantage across different models and various tasks, regardless of whether the answer space is known. Its advantage is maintained even after reinforcement learning, and further analysis shows its reasoning patterns are aligned with human expectations.
GSE: Evaluating Sticker Visual Semantic Similarity via a General Sticker Encoder
Nov 07, 2025
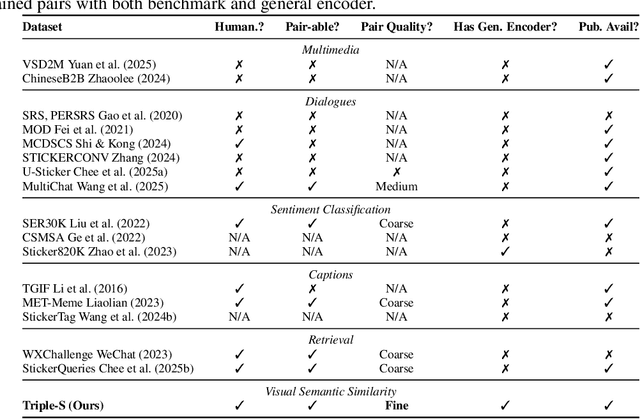
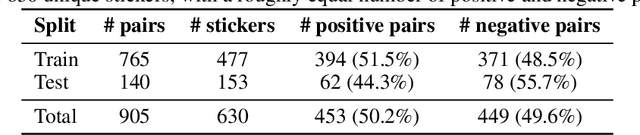
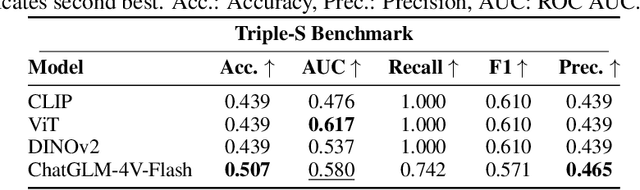
Stickers have become a popular form of visual communication, yet understanding their semantic relationships remains challenging due to their highly diverse and symbolic content. In this work, we formally {define the Sticker Semantic Similarity task} and introduce {Triple-S}, the first benchmark for this task, consisting of 905 human-annotated positive and negative sticker pairs. Through extensive evaluation, we show that existing pretrained vision and multimodal models struggle to capture nuanced sticker semantics. To address this, we propose the {General Sticker Encoder (GSE)}, a lightweight and versatile model that learns robust sticker embeddings using both Triple-S and additional datasets. GSE achieves superior performance on unseen stickers, and demonstrates strong results on downstream tasks such as emotion classification and sticker-to-sticker retrieval. By releasing both Triple-S and GSE, we provide standardized evaluation tools and robust embeddings, enabling future research in sticker understanding, retrieval, and multimodal content generation. The Triple-S benchmark and GSE have been publicly released and are available here.
Doctor-R1: Mastering Clinical Inquiry with Experiential Agentic Reinforcement Learning
Oct 05, 2025The professionalism of a human doctor in outpatient service depends on two core abilities: the ability to make accurate medical decisions and the medical consultation skill to conduct strategic, empathetic patient inquiry. Existing Large Language Models (LLMs) have achieved remarkable accuracy on medical decision-making benchmarks. However, they often lack the ability to conduct the strategic and empathetic consultation, which is essential for real-world clinical scenarios. To address this gap, we propose Doctor-R1, an AI doctor agent trained to master both of the capabilities by ask high-yield questions and conduct strategic multi-turn inquiry to guide decision-making. Our framework introduces three key components: a multi-agent interactive environment, a two-tiered reward architecture that separately optimizes clinical decision-making and communicative inquiry skills, and an experience repository to ground policy learning in high-quality prior trajectories. We evaluate Doctor-R1 on OpenAI's HealthBench and MAQuE, assessed across multi-facet metrics, such as communication quality, user experience, and task accuracy. Remarkably, Doctor-R1 surpasses state-of-the-art open-source specialized LLMs by a substantial margin with higher parameter efficiency and outperforms powerful proprietary models. Furthermore, the human evaluations show a strong preference for Doctor-R1 to generate human-preferred clinical dialogue, demonstrating the effectiveness of the framework.
UR$^2$: Unify RAG and Reasoning through Reinforcement Learning
Aug 08, 2025Large Language Models (LLMs) have shown remarkable capabilities through two complementary paradigms: Retrieval-Augmented Generation (RAG), which enhances knowledge grounding, and Reinforcement Learning from Verifiable Rewards (RLVR), which optimizes complex reasoning abilities. However, these two capabilities are often developed in isolation, and existing efforts to unify them remain narrow in scope-typically limited to open-domain QA with fixed retrieval settings and task-specific assumptions. This lack of integration constrains generalization and limits the applicability of RAG-RL methods to broader domains. To bridge this gap, we propose UR2 (Unified RAG and Reasoning), a general framework that unifies retrieval and reasoning through reinforcement learning. UR2 introduces two key contributions: a difficulty-aware curriculum training that selectively invokes retrieval only for challenging problems, and a hybrid knowledge access strategy combining domain-specific offline corpora with LLM-generated summaries. These components are designed to enable dynamic coordination between retrieval and reasoning, improving adaptability across a diverse range of tasks. Experiments across open-domain QA, MMLU-Pro, medical, and mathematical reasoning tasks demonstrate that UR2 (built on Qwen2.5-3/7B and LLaMA-3.1-8B) significantly outperforms existing RAG and RL methods, achieving comparable performance to GPT-4o-mini and GPT-4.1-mini on several benchmarks. We have released all code, models, and data at https://github.com/Tsinghua-dhy/UR2.
How Far Can LLMs Improve from Experience? Measuring Test-Time Learning Ability in LLMs with Human Comparison
Jun 17, 2025As evaluation designs of large language models may shape our trajectory toward artificial general intelligence, comprehensive and forward-looking assessment is essential. Existing benchmarks primarily assess static knowledge, while intelligence also entails the ability to rapidly learn from experience. To this end, we advocate for the evaluation of Test-time Learning, the capacity to improve performance in experience-based, reasoning-intensive tasks during test time. In this work, we propose semantic games as effective testbeds for evaluating test-time learning, due to their resistance to saturation and inherent demand for strategic reasoning. We introduce an objective evaluation framework that compares model performance under both limited and cumulative experience settings, and contains four forms of experience representation. To provide a comparative baseline, we recruit eight human participants to complete the same task. Results show that LLMs exhibit measurable test-time learning capabilities; however, their improvements are less stable under cumulative experience and progress more slowly than those observed in humans. These findings underscore the potential of LLMs as general-purpose learning machines, while also revealing a substantial intellectual gap between models and humans, irrespective of how well LLMs perform on static benchmarks.
StoryBench: A Dynamic Benchmark for Evaluating Long-Term Memory with Multi Turns
Jun 16, 2025Long-term memory (LTM) is essential for large language models (LLMs) to achieve autonomous intelligence in complex, evolving environments. Despite increasing efforts in memory-augmented and retrieval-based architectures, there remains a lack of standardized benchmarks to systematically evaluate LLMs' long-term memory abilities. Existing benchmarks still face challenges in evaluating knowledge retention and dynamic sequential reasoning, and in their own flexibility, all of which limit their effectiveness in assessing models' LTM capabilities. To address these gaps, we propose a novel benchmark framework based on interactive fiction games, featuring dynamically branching storylines with complex reasoning structures. These structures simulate real-world scenarios by requiring LLMs to navigate hierarchical decision trees, where each choice triggers cascading dependencies across multi-turn interactions. Our benchmark emphasizes two distinct settings to test reasoning complexity: one with immediate feedback upon incorrect decisions, and the other requiring models to independently trace back and revise earlier choices after failure. As part of this benchmark, we also construct a new dataset designed to test LLMs' LTM within narrative-driven environments. We further validate the effectiveness of our approach through detailed experiments. Experimental results demonstrate the benchmark's ability to robustly and reliably assess LTM in LLMs.
Effective and Transparent RAG: Adaptive-Reward Reinforcement Learning for Decision Traceability
May 19, 2025Retrieval-Augmented Generation (RAG) has significantly improved the performance of large language models (LLMs) on knowledge-intensive domains. However, although RAG achieved successes across distinct domains, there are still some unsolved challenges: 1) Effectiveness. Existing research mainly focuses on developing more powerful RAG retrievers, but how to enhance the generator's (LLM's) ability to utilize the retrieved information for reasoning and generation? 2) Transparency. Most RAG methods ignore which retrieved content actually contributes to the reasoning process, resulting in a lack of interpretability and visibility. To address this, we propose ARENA (Adaptive-Rewarded Evidence Navigation Agent), a transparent RAG generator framework trained via reinforcement learning (RL) with our proposed rewards. Based on the structured generation and adaptive reward calculation, our RL-based training enables the model to identify key evidence, perform structured reasoning, and generate answers with interpretable decision traces. Applied to Qwen2.5-7B-Instruct and Llama3.1-8B-Instruct, abundant experiments with various RAG baselines demonstrate that our model achieves 10-30% improvements on all multi-hop QA datasets, which is comparable with the SOTA Commercially-developed LLMs (e.g., OpenAI-o1, DeepSeek-R1). Further analyses show that ARENA has strong flexibility to be adopted on new datasets without extra training. Our models and codes are publicly released.
Short Video Segment-level User Dynamic Interests Modeling in Personalized Recommendation
Apr 05, 2025



The rapid growth of short videos has necessitated effective recommender systems to match users with content tailored to their evolving preferences. Current video recommendation models primarily treat each video as a whole, overlooking the dynamic nature of user preferences with specific video segments. In contrast, our research focuses on segment-level user interest modeling, which is crucial for understanding how users' preferences evolve during video browsing. To capture users' dynamic segment interests, we propose an innovative model that integrates a hybrid representation module, a multi-modal user-video encoder, and a segment interest decoder. Our model addresses the challenges of capturing dynamic interest patterns, missing segment-level labels, and fusing different modalities, achieving precise segment-level interest prediction. We present two downstream tasks to evaluate the effectiveness of our segment interest modeling approach: video-skip prediction and short video recommendation. Our experiments on real-world short video datasets with diverse modalities show promising results on both tasks. It demonstrates that segment-level interest modeling brings a deep understanding of user engagement and enhances video recommendations. We also release a unique dataset that includes segment-level video data and diverse user behaviors, enabling further research in segment-level interest modeling. This work pioneers a novel perspective on understanding user segment-level preference, offering the potential for more personalized and engaging short video experiences.
Efficient Dynamic Clustering-Based Document Compression for Retrieval-Augmented-Generation
Apr 04, 2025



Retrieval-Augmented Generation (RAG) has emerged as a widely adopted approach for knowledge integration during large language model (LLM) inference in recent years. However, current RAG implementations face challenges in effectively addressing noise, repetition and redundancy in retrieved content, primarily due to their limited ability to exploit fine-grained inter-document relationships. To address these limitations, we propose an \textbf{E}fficient \textbf{D}ynamic \textbf{C}lustering-based document \textbf{C}ompression framework (\textbf{EDC\textsuperscript{2}-RAG}) that effectively utilizes latent inter-document relationships while simultaneously removing irrelevant information and redundant content. We validate our approach, built upon GPT-3.5, on widely used knowledge-QA and hallucination-detected datasets. The results show that this method achieves consistent performance improvements across various scenarios and experimental settings, demonstrating strong robustness and applicability. Our code and datasets can be found at https://github.com/Tsinghua-dhy/EDC-2-RAG.