 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSE: Evaluating Sticker Visual Semantic Similarity via a General Sticker Encoder
Nov 07, 2025
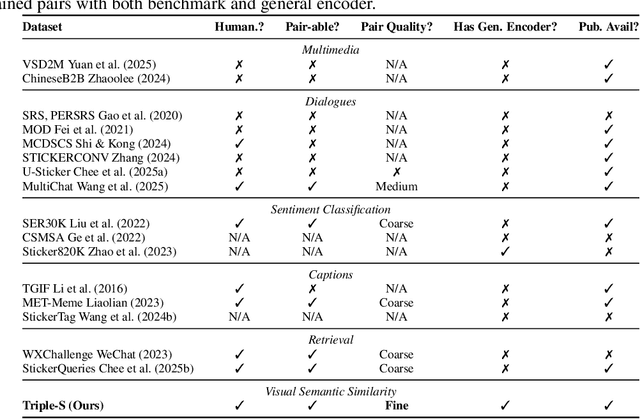
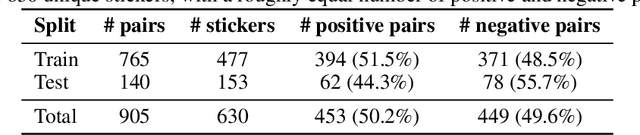
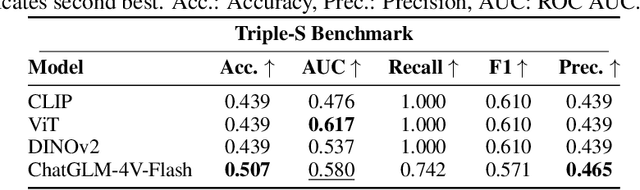
Stickers have become a popular form of visual communication, yet understanding their semantic relationships remains challenging due to their highly diverse and symbolic content. In this work, we formally {define the Sticker Semantic Similarity task} and introduce {Triple-S}, the first benchmark for this task, consisting of 905 human-annotated positive and negative sticker pairs. Through extensive evaluation, we show that existing pretrained vision and multimodal models struggle to capture nuanced sticker semantics. To address this, we propose the {General Sticker Encoder (GSE)}, a lightweight and versatile model that learns robust sticker embeddings using both Triple-S and additional datasets. GSE achieves superior performance on unseen stickers, and demonstrates strong results on downstream tasks such as emotion classification and sticker-to-sticker retrieval. By releasing both Triple-S and GSE, we provide standardized evaluation tools and robust embeddings, enabling future research in sticker understanding, retrieval, and multimodal content generation. The Triple-S benchmark and GSE have been publicly released and are available here.
A 106K Multi-Topic Multilingual Conversational User Dataset with Emoticons
Feb 26, 2025Instant messaging has become a predominant form of communication, with texts and emoticons enabling users to express emotions and ideas efficiently. Emoticons, in particular, have gained significant traction as a medium for conveying sentiments and information, leading to the growing importance of emoticon retrieval and recommendation systems. However, one of the key challenges in this area has been the absence of datasets that capture both the temporal dynamics and user-specific interactions with emoticons, limiting the progress of personalized user modeling and recommendation approaches. To address this, we introduce the emoticon dataset, a comprehensive resource that includes time-based data along with anonymous user identifiers across different conversations. As the largest publicly accessible emoticon dataset to date, it comprises 22K unique users, 370K emoticons, and 8.3M messages. The data was collected from a widely-used messaging platform across 67 conversations and 720 hours of crawling. Strict privacy and safety checks were applied to ensure the integrity of both text and image data. Spanning across 10 distinct domains, the emoticon dataset provides rich insights into temporal, multilingual, and cross-domain behaviors, which were previously unavailable in other emoticon-based datasets. Our in-depth experiments, both quantitative and qualitative, demonstrate the dataset's potential in modeling user behavior and personalized recommendation systems, opening up new possibilities for research in personalized retrieval and conversational AI. The dataset is freely accessible.
PerSRV: Personalized Sticker Retrieval with Vision-Language Model
Oct 29, 2024



Instant Messaging is a popular means for daily communication, allowing users to send text and stickers. As the saying goes, "a picture is worth a thousand words", so developing an effective sticker retrieval technique is crucial for enhancing user experience. However, existing sticker retrieval methods rely on labeled data to interpret stickers, and general-purpose Vision-Language Models (VLMs) often struggle to capture the unique semantics of stickers. Additionally, relevant-based sticker retrieval methods lack personalization, creating a gap between diverse user expectations and retrieval results. To address these, we propose the Personalized Sticker Retrieval with Vision-Language Model framework, namely PerSRV, structured into offline calculations and online processing modules. The online retrieval part follows the paradigm of relevant recall and personalized ranking, supported by the offline pre-calculation parts, which are sticker semantic understanding, utility evaluation and personalization modules. Firstly, for sticker-level semantic understanding, we supervised fine-tuned LLaVA-1.5-7B to generate human-like sticker semantics, complemented by textual content extracted from figures and historical interaction queries. Secondly, we investigate three crowd-sourcing metrics for sticker utility evaluation. Thirdly, we cluster style centroids based on users' historical interactions to achieve personal preference modeling. Finally, we evaluate our proposed PerSRV method on a public sticker retrieval dataset from WeChat, containing 543,098 candidates and 12,568 interactions. Experimental results show that PerSRV significantly outperforms existing methods in multi-modal sticker retrieval. Additionally, our fine-tuned VLM delivers notable improvements in sticker semantic understandings.