 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEC: A Collection of Human Trial-and-error Trajectories for Problem Solving
Apr 09, 2026Trial-and-error is a fundamental strategy for humans to solve complex problems and a necessary capability for Artificial Intelligence (AI) systems operating in real-world environments. Although several trial-and-error AI techniques have recently been proposed, most of them rely on simple heuristics designed by researchers and achieve limited performance gains. The core issue is the absence of appropriate data: current models cannot learn from detailed records of how humans actually conduct trial-and-error in practice. To address this gap, we introduce a data annotation platform and a corresponding dataset, termed Trial-and-Error Collection (TEC). The platform records users' complete trajectories across multiple trials and collects their reflections after receiving error feedback. Using this platform, we record the problem-solving processes of 46 participants on 58 tasks, resulting in 5,370 trial trajectories along with error reflections across 41,229 webpages. With this dataset, we observe that humans achieve substantially higher accuracy compared to LLMs, which demonstrates that humans are more effective in trial-and-error than LLMs. We believe that the TEC platform and dataset provide a valuable foundation for understanding human trial-and-error behavior and for developing more capable AI systems. Platform and dataset are publicly available.
Relative-Based Scaling Law for Neural Language Models
Oct 23, 2025Scaling laws aim to accurately predict model performance across different scales. Existing scaling-law studies almost exclusively rely on cross-entropy as the evaluation metric. However, cross-entropy provides only a partial view of performance: it measures the absolute probability assigned to the correct token, but ignores the relative ordering between correct and incorrect tokens. Yet, relative ordering is crucial for language models, such as in greedy-sampling scenario. To address this limitation, we investigate scaling from the perspective of relative ordering. We first propose the Relative-Based Probability (RBP) metric, which quantifies the probability that the correct token is ranked among the top predictions. Building on this metric, we establish the Relative-Based Scaling Law, which characterizes how RBP improves with increasing model size. Through extensive experiments on four datasets and four model families spanning five orders of magnitude, we demonstrate the robustness and accuracy of this law. Finally, we illustrate the broad application of this law with two examples, namely providing a deeper explanation of emergence phenomena and facilitating finding fundamental theories of scaling laws. In summary, the Relative-Based Scaling Law complements the cross-entropy perspective and contributes to a more complete understanding of scaling large language models. Thus, it offers valuable insights for both practical development and theoretical exploration.
Dynamic and Parametric Retrieval-Augmented Generation
Jun 07, 2025Retrieval-Augmented Generation (RAG) has become a foundational paradigm for equipping large language models (LLMs) with external knowledge, playing a critical role in information retrieval and knowledge-intensive applications. However, conventional RAG systems typically adopt a static retrieve-then-generate pipeline and rely on in-context knowledge injection, which can be suboptimal for complex tasks that require multihop reasoning, adaptive information access, and deeper integration of external knowledge. Motivated by these limitations, the research community has moved beyond static retrieval and in-context knowledge injection. Among the emerging directions, this tutorial delves into two rapidly growing and complementary research areas on RAG: Dynamic RAG and Parametric RAG. Dynamic RAG adaptively determines when and what to retrieve during the LLM's generation process, enabling real-time adaptation to the LLM's evolving information needs. Parametric RAG rethinks how retrieved knowledge should be injected into LLMs, transitioning from input-level to parameter-level knowledge injection for enhanced efficiency and effectiveness. This tutorial offers a comprehensive overview of recent advances in these emerging research areas. It also shares theoretical foundations and practical insights to support and inspire further research in RAG.
Intelligence Test
Feb 26, 2025How does intelligence emerge? We propose that intelligence is not a sudden gift or random occurrence, but rather a necessary trait for species to survive through Natural Selection. If a species passes the test of Natural Selection, it demonstrates the intelligence to survive in nature. Extending this perspective, we introduce Intelligence Test, a method to quantify the intelligence of any subject on any task. Like how species evolve by trial and error, Intelligence Test quantifies intelligence by the number of failed attempts before success. Fewer failures correspond to higher intelligence. When the expectation and variance of failure counts are both finite, it signals the achievement of an autonomous level of intelligence. Using Intelligence Test, we comprehensively evaluate existing AI systems. Our results show that while AI systems achieve a level of autonomy in simple tasks, they are still far from autonomous in more complex tasks, such as vision, search, recommendation, and language. While scaling model size might help, this would come at an astronomical cost. Projections suggest that achieving general autonomy would require unimaginable $10^{26}$ parameters. Even if Moore's Law continuously holds, such a parameter scale would take $70$ years. This staggering cost highlights the complexity of human tasks and the inadequacies of current AI. To further understand this phenomenon, we conduct a theoretical analysis. Our simulations suggest that human tasks possess a criticality property. As a result, autonomy requires a deep understanding of the task's underlying mechanisms. Current AI, however, does not fully grasp these mechanisms and instead relies on superficial mimicry, making it difficult to reach an autonomous level. We believe Intelligence Test can not only guide the future development of AI but also offer profound insights into the intelligence of humans ourselves.
Foundations of GenIR
Jan 06, 2025

The chapter discusses the foundational impact of modern generative AI models on information access (IA) systems. In contrast to traditional AI, the large-scale training and superior data modeling of generative AI models enable them to produce high-quality, human-like responses, which brings brand new opportunities for the development of IA paradigms. In this chapter, we identify and introduce two of them in details, i.e., information generation and information synthesis. Information generation allows AI to create tailored content addressing user needs directly, enhancing user experience with immediate, relevant outputs. Information synthesis leverages the ability of generative AI to integrate and reorganize existing information, providing grounded responses and mitigating issues like model hallucination, which is particularly valuable in scenarios requiring precision and external knowledge. This chapter delves into the foundational aspects of generative models, including architecture, scaling, and training, and discusses their applications in multi-modal scenarios. Additionally, it examines the retrieval-augmented generation paradigm and other methods for corpus modeling and understanding, demonstrating how generative AI can enhance information access systems. It also summarizes potential challenges and fruitful directions for future studies.
StepTool: A Step-grained Reinforcement Learning Framework for Tool Learning in LLMs
Oct 10, 2024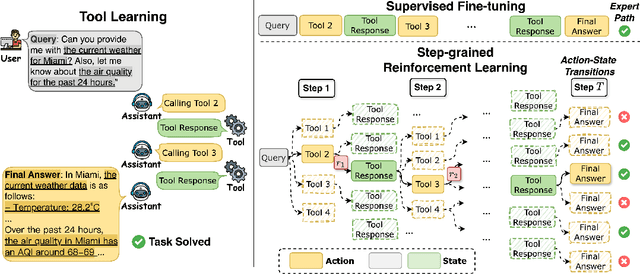

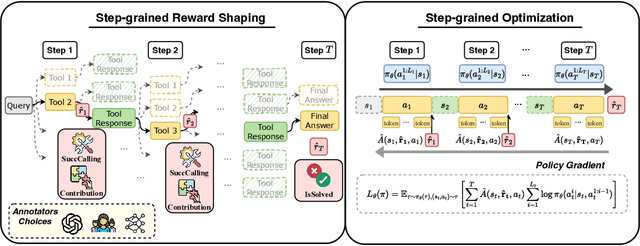
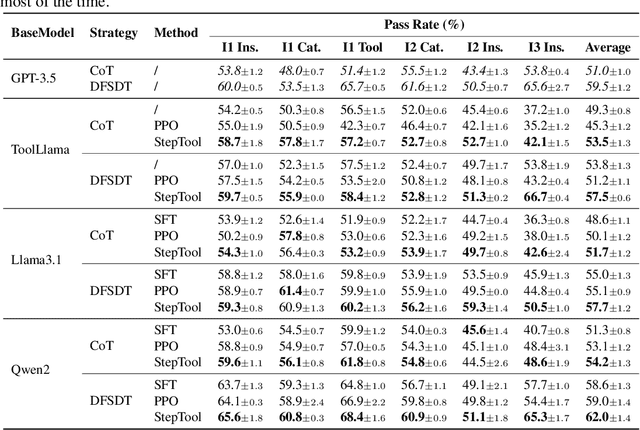
Despite having powerful reasoning and inference capabilities, Large Language Models (LLMs) still need external tools to acquire real-time information retrieval or domain-specific expertise to solve complex tasks, which is referred to as tool learning. Existing tool learning methods primarily rely on tuning with expert trajectories, focusing on token-sequence learning from a linguistic perspective. However, there are several challenges: 1) imitating static trajectories limits their ability to generalize to new tasks. 2) even expert trajectories can be suboptimal, and better solution paths may exist. In this work, we introduce StepTool, a novel step-grained reinforcement learning framework to improve tool learning in LLMs. It consists of two components: Step-grained Reward Shaping, which assigns rewards at each tool interaction based on tool invocation success and its contribution to the task, and Step-grained Optimization, which uses policy gradient methods to optimize the model in a multi-step manner. Experimental results demonstrate that StepTool significantly outperforms existing methods in multi-step, tool-based tasks, providing a robust solution for complex task environments. Codes are available at https://github.com/yuyq18/StepTool.
Prompt Refinement with Image Pivot for Text-to-Image Generation
Jun 28, 2024
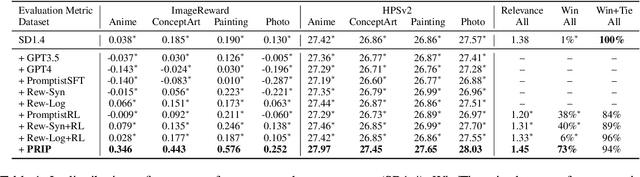
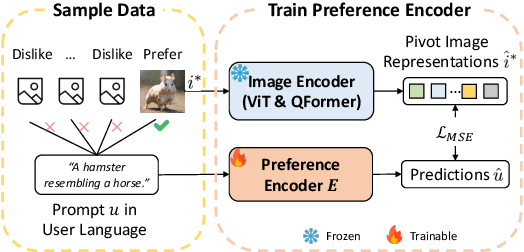
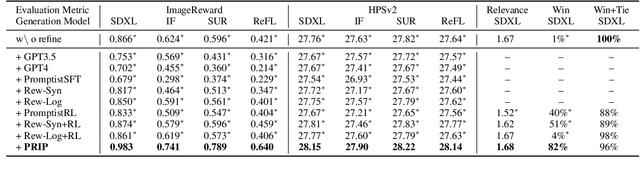
For text-to-image generation, automatically refining user-provided natural language prompts into the keyword-enriched prompts favored by systems is essential for the user experience. Such a prompt refinement process is analogous to translating the prompt from "user languages" into "system languages". However, the scarcity of such parallel corpora makes it difficult to train a prompt refinement model. Inspired by zero-shot machine translation techniques, we introduce Prompt Refinement with Image Pivot (PRIP). PRIP innovatively uses the latent representation of a user-preferred image as an intermediary "pivot" between the user and system languages. It decomposes the refinement process into two data-rich tasks: inferring representations of user-preferred images from user languages and subsequently translating image representations into system languages. Thus, it can leverage abundant data for training. Extensive experiments show that PRIP substantially outperforms a wide range of baselines and effectively transfers to unseen systems in a zero-shot manner.
Scaling Laws For Dense Retrieval
Mar 27, 2024Scaling up neural models has yielded significant advancements in a wide array of tasks, particularly in language generation. Previous studies have found that the performance of neural models frequently adheres to predictable scaling laws, correlated with factors such as training set size and model size. This insight is invaluable, especially as large-scale experiments grow increasingly resource-intensive. Yet, such scaling law has not been fully explored in dense retrieval due to the discrete nature of retrieval metrics and complex relationships between training data and model sizes in retrieval tasks. In this study, we investigate whether the performance of dense retrieval models follows the scaling law as other neural models. We propose to use contrastive log-likelihood as the evaluation metric and conduct extensive experiments with dense retrieval models implemented with different numbers of parameters and trained with different amounts of annotated data. Results indicate that, under our settings, the performance of dense retrieval models follows a precise power-law scaling related to the model size and the number of annotations. Additionally, we examine scaling with prevalent data augmentation methods to assess the impact of annotation quality, and apply the scaling law to find the best resource allocation strategy under a budget constraint. We believe that these insights will significantly contribute to understanding the scaling effect of dense retrieval models and offer meaningful guidance for future research endeavors.
Capability-aware Prompt Reformulation Learning for Text-to-Image Generation
Mar 27, 2024Text-to-image generation systems have emerged as revolutionary tools in the realm of artistic creation, offering unprecedented ease in transforming textual prompts into visual art. However, the efficacy of these systems is intricately linked to the quality of user-provided prompts, which often poses a challenge to users unfamiliar with prompt crafting. This paper addresses this challenge by leveraging user reformulation data from interaction logs to develop an automatic prompt reformulation model. Our in-depth analysis of these logs reveals that user prompt reformulation is heavily dependent on the individual user's capability, resulting in significant variance in the quality of reformulation pairs. To effectively use this data for training, we introduce the Capability-aware Prompt Reformulation (CAPR) framework. CAPR innovatively integrates user capability into the reformulation process through two key components: the Conditional Reformulation Model (CRM) and Configurable Capability Features (CCF). CRM reformulates prompts according to a specified user capability, as represented by CCF. The CCF, in turn, offers the flexibility to tune and guide the CRM's behavior. This enables CAPR to effectively learn diverse reformulation strategies across various user capacities and to simulate high-capability user reformulation during inference. Extensive experiments on standard text-to-image generation benchmarks showcase CAPR's superior performance over existing baselines and its remarkable robustness on unseen systems. Furthermore, comprehensive analyses validate the effectiveness of different components. CAPR can facilitate user-friendly interaction with text-to-image systems and make advanced artistic creation more achievable for a broader range of users.
Query Augmentation by Decoding Semantics from Brain Signals
Mar 03, 2024



Query augmentation is a crucial technique for refining semantically imprecise queries. Traditionally, query augmentation relies on extracting information from initially retrieved, potentially relevant documents. If the quality of the initially retrieved documents is low, then the effectiveness of query augmentation would be limited as well. We propose Brain-Aug, which enhances a query by incorporating semantic information decoded from brain signals. BrainAug generates the continuation of the original query with a prompt constructed with brain signal information and a ranking-oriented inference approach. Experimental results on fMRI (functional magnetic resonance imaging) datasets show that Brain-Aug produces semantically more accurate queries, leading to improved document ranking performance. Such improvement brought by brain signals is particularly notable for ambiguous queries.