 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Modeling of Domain and Relevance for Adaptable Dense Retrieval
Paper and Code

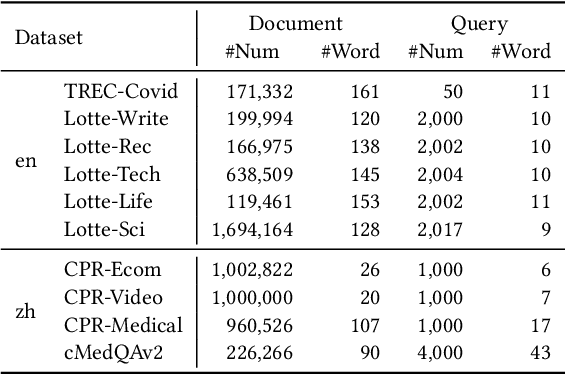
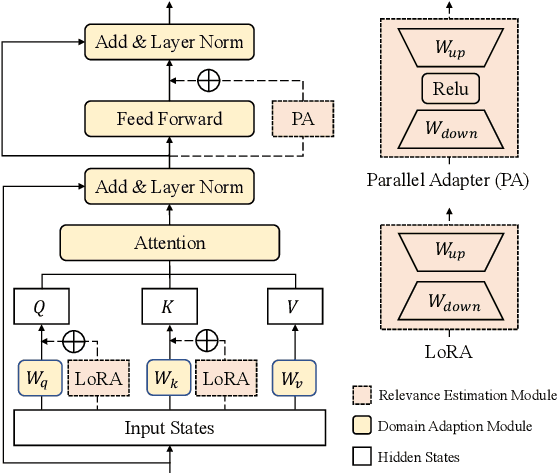
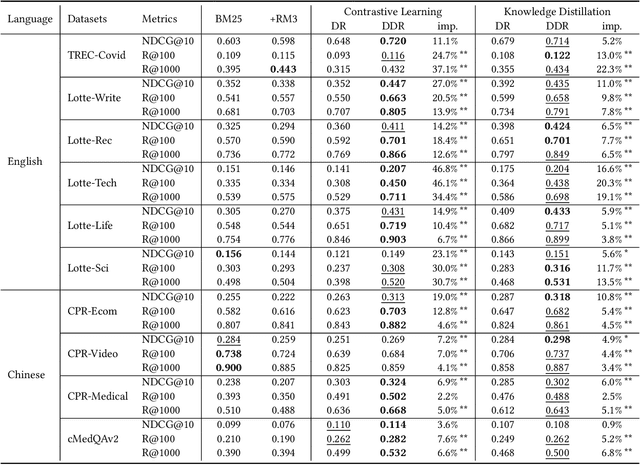
Recent advance in Dense Retrieval (DR) techniques has significantly improved the effectiveness of first-stage retrieval. Trained with large-scale supervised data, DR models can encode queries and documents into a low-dimensional dense space and conduct effective semantic matching. However, previous studies have shown that the effectiveness of DR models would drop by a large margin when the trained DR models are adopted in a target domain that is different from the domain of the labeled data. One of the possible reasons is that the DR model has never seen the target corpus and thus might be incapable of mitigating the difference between the training and target domains. In practice, unfortunately, training a DR model for each target domain to avoid domain shift is often a difficult task as it requires additional time, storage, and domain-specific data labeling, which are not always available. To address this problem, in this paper, we propose a novel DR framework named Disentangled Dense Retrieval (DDR) to support effective and flexible domain adaptation for DR models. DDR consists of a Relevance Estimation Module (REM) for modeling domain-invariant matching patterns and several Domain Adaption Modules (DAMs) for modeling domain-specific features of multiple target corpora. By making the REM and DAMs disentangled, DDR enables a flexible training paradigm in which REM is trained with supervision once and DAMs are trained with unsupervised data. Comprehensive experiments in different domains and languages show that DDR significantly improves ranking performance compared to strong DR baselines and substantially outperforms traditional retrieval methods in most scenarios.