 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Key-value Strategy in Recommendation Systems Incorporating Large Language Model
Oct 25, 2023Recommendation system (RS) plays significant roles in matching users information needs for Internet applications, and it usually utilizes the vanilla neural network as the backbone to handle embedding details. Recently, the large language model (LLM) has exhibited emergent abilities and achieved great breakthroughs both in the CV and NLP communities. Thus, it is logical to incorporate RS with LLM better, which has become an emerging research direction. Although some existing works have made their contributions to this issue, they mainly consider the single key situation (e.g. historical interactions), especially in sequential recommendation. The situation of multiple key-value data is simply neglected. This significant scenario is mainstream in real practical applications, where the information of users (e.g. age, occupation, etc) and items (e.g. title, category, etc) has more than one key. Therefore, we aim to implement sequential recommendations based on multiple key-value data by incorporating RS with LLM. In particular, we instruct tuning a prevalent open-source LLM (Llama 7B) in order to inject domain knowledge of RS into the pre-trained LLM. Since we adopt multiple key-value strategies, LLM is hard to learn well among these keys. Thus the general and innovative shuffle and mask strategies, as an innovative manner of data argument, are designed. To demonstrate the effectiveness of our approach, extensive experiments are conducted on the popular and suitable dataset MovieLens which contains multiple keys-value. The experimental results demonstrate that our approach can nicely and effectively complete this challenging issue.
Intent-aware Ranking Ensemble for Personalized Recommendation
Apr 15, 2023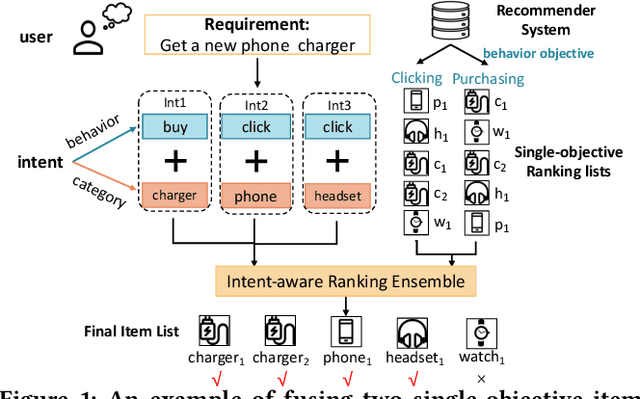

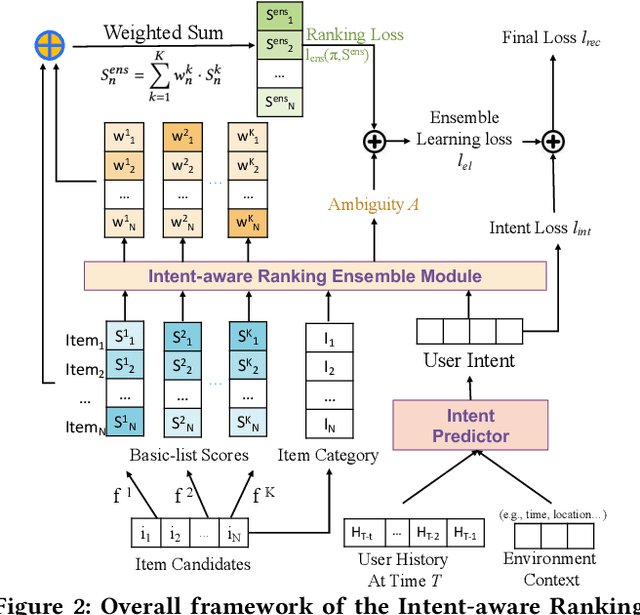
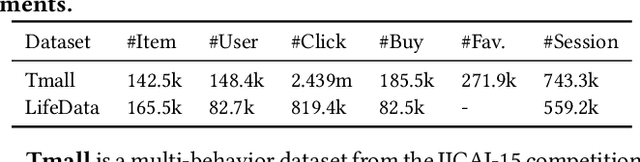
Ranking ensemble is a critical component in real recommender systems. When a user visits a platform, the system will prepare several item lists, each of which is generally from a single behavior objective recommendation model. As multiple behavior intents, e.g., both clicking and buying some specific item category, are commonly concurrent in a user visit, it is necessary to integrate multiple single-objective ranking lists into one. However, previous work on rank aggregation mainly focused on fusing homogeneous item lists with the same objective while ignoring ensemble of heterogeneous lists ranked with different objectives with various user intents. In this paper, we treat a user's possible behaviors and the potential interacting item categories as the user's intent. And we aim to study how to fuse candidate item lists generated from different objectives aware of user intents. To address such a task, we propose an Intent-aware ranking Ensemble Learning~(IntEL) model to fuse multiple single-objective item lists with various user intents, in which item-level personalized weights are learned. Furthermore, we theoretically prove the effectiveness of IntEL with point-wise, pair-wise, and list-wise loss functions via error-ambiguity decomposition. Experiments on two large-scale real-world datasets also show significant improvements of IntEL on multiple behavior objectives simultaneously compared to previous ranking ensemble models.
Learning Self-Modulating Attention in Continuous Time Space with Applications to Sequential Recommendation
Mar 30, 2022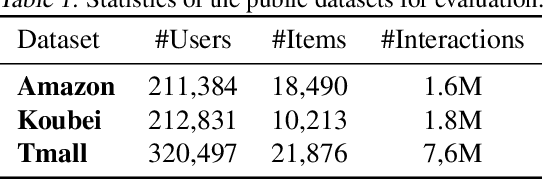
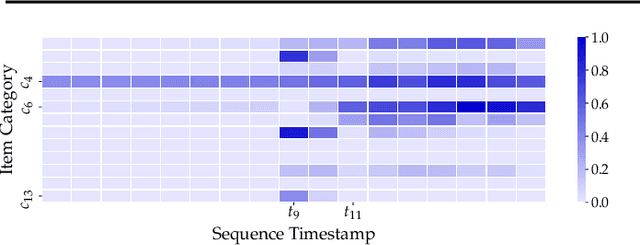
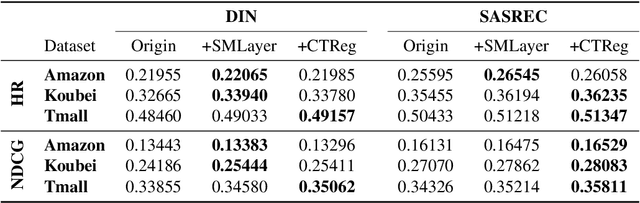
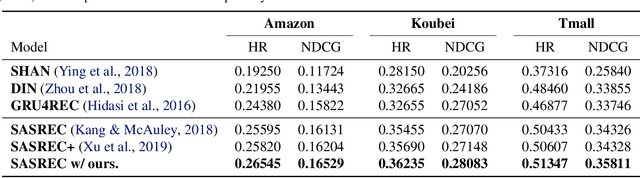
User interests are usually dynamic in the real world, which poses both theoretical and practical challenges for learning accurate preferences from rich behavior data. Among existing user behavior modeling solutions, attention networks are widely adopted for its effectiveness and relative simplicity. Despite being extensively studied, existing attentions still suffer from two limitations: i) conventional attentions mainly take into account the spatial correlation between user behaviors, regardless the distance between those behaviors in the continuous time space; and ii) these attentions mostly provide a dense and undistinguished distribution over all past behaviors then attentively encode them into the output latent representations. This is however not suitable in practical scenarios where a user's future actions are relevant to a small subset of her/his historical behaviors. In this paper, we propose a novel attention network, named self-modulating attention, that models the complex and non-linearly evolving dynamic user preferences. We empirically demonstrate the effectiveness of our method on top-N sequential recommendation tasks, and the results on three large-scale real-world datasets show that our model can achieve state-of-the-art performance.