 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA3-FPN: Asymptotic Content-Aware Pyramid Attention Network for Dense Visual Prediction
Apr 11, 2026Learning multi-scale representations is the common strategy to tackle object scale variation in dense prediction tasks. Although existing feature pyramid networks have greatly advanced visual recognition, inherent design defects inhibit them from capturing discriminative features and recognizing small objects. In this work, we propose Asymptotic Content-Aware Pyramid Attention Network (A3-FPN), to augment multi-scale feature representation via the asymptotically disentangled framework and content-aware attention modules. Specifically, A3-FPN employs a horizontally-spread column network that enables asymptotically global feature interaction and disentangles each level from all hierarchical representations. In feature fusion, it collects supplementary content from the adjacent level to generate position-wise offsets and weights for context-aware resampling, and learns deep context reweights to improve intra-category similarity. In feature reassembly, it further strengthens intra-scale discriminative feature learning and reassembles redundant features based on information content and spatial variation of feature maps. Extensive experiments on MS COCO, VisDrone2019-DET and Cityscapes demonstrate that A3-FPN can be easily integrated into state-of-the-art CNN and Transformer-based architectures, yielding remarkable performance gains. Notably, when paired with OneFormer and Swin-L backbone, A3-FPN achieves 49.6 mask AP on MS COCO and 85.6 mIoU on Cityscapes. Codes are available at https://github.com/mason-ching/A3-FPN.
Significance and Stability Analysis of Gene-Environment Interaction using RGxEStat
Apr 03, 2026Genotype-by-Environment (GxE) interactions influence the performance of genotypes across diverse environments, reducing the predictability of phenotypes in target environments. In-depth analysis of GxE interactions facilitates the identification of how genetic advantages or defects are expressed or suppressed under specific environmental conditions, thereby enabling genetic selection and enhancing breeding practices. This paper introduces two key models for GxE interaction research. Specifically, it includes significance analysis based on the mixed effect model to determine whether genes or GxE interactions significantly affect phenotypic traits; stability analysis, which further investigates the interactive relationships between genes and environments, as well as the relative superiority or inferiority of genotypes across environments. Additionally, this paper presents RGxEStat, a lightweight interactive tool, which is developed by the authors and integrates the construction, solution, and visualization of the aforementioned models. Designed to eliminate the need for breeders and agronomists to learn complex SAS or R programming, RGxEStat provides a user-friendly interface for streamlined breeding data analysis, significantly accelerating research cycles. Codes and datasets are available at https://github.com/mason-ching/RGxEStat.
PJB: A Reasoning-Aware Benchmark for Person-Job Retrieval
Mar 18, 2026As retrieval models converge on generic benchmarks, the pressing question is no longer "who scores higher" but rather "where do systems fail, and why?" Person-job matching is a domain that urgently demands such diagnostic capability -- it requires systems not only to verify explicit constraints but also to perform skill-transfer inference and job-competency reasoning, yet existing benchmarks provide no systematic diagnostic support for this task. We introduce PJB (Person-Job Benchmark), a reasoning-aware retrieval evaluation dataset that uses complete job descriptions as queries and complete resumes as documents, defines relevance through job-competency judgment, is grounded in real-world recruitment data spanning six industry domains and nearly 200,000 resumes, and upgrades evaluation from "who scores higher" to "where do systems differ, and why" through domain-family and reasoning-type diagnostic labels. Diagnostic experiments using dense retrieval reveal that performance heterogeneity across industry domains far exceeds the gains from module upgrades for the same model, indicating that aggregate scores alone can severely mislead optimization decisions. At the module level, reranking yields stable improvements while query understanding not only fails to help but actually degrades overall performance when combined with reranking -- the two modules face fundamentally different improvement bottlenecks. The value of PJB lies not in yet another leaderboard of average scores, but in providing recruitment retrieval systems with a capability map that pinpoints where to invest.
Uncertainty-oriented Order Learning for Facial Beauty Prediction
Sep 01, 2024



Previous Facial Beauty Prediction (FBP) methods generally model FB feature of an image as a point on the latent space, and learn a mapping from the point to a precise score. Although existing regression methods perform well on a single dataset, they are inclined to be sensitive to test data and have weak generalization ability. We think they underestimate two inconsistencies existing in the FBP problem: 1. inconsistency of FB standards among multiple datasets, and 2. inconsistency of human cognition on FB of an image. To address these issues, we propose a new Uncertainty-oriented Order Learning (UOL), where the order learning addresses the inconsistency of FB standards by learning the FB order relations among face images rather than a mapping, and the uncertainty modeling represents the inconsistency in human cognition. The key contribution of UOL is a designed distribution comparison module, which enables conventional order learning to learn the order of uncertain data. Extensive experiments on five datasets show that UOL outperforms the state-of-the-art methods on both accuracy and generalization ability.
IB-AdCSCNet:Adaptive Convolutional Sparse Coding Network Driven by Information Bottleneck
May 23, 2024



In the realm of neural network models, the perpetual challenge remains in retaining task-relevant information while effectively discarding redundant data during propagation. In this paper, we introduce IB-AdCSCNet, a deep learning model grounded in information bottleneck theory. IB-AdCSCNet seamlessly integrates the information bottleneck trade-off strategy into deep networks by dynamically adjusting the trade-off hyperparameter $\lambda$ through gradient descent, updating it within the FISTA(Fast Iterative Shrinkage-Thresholding Algorithm ) framework. By optimizing the compressive excitation loss function induced by the information bottleneck principle, IB-AdCSCNet achieves an optimal balance between compression and fitting at a global level, approximating the globally optimal representation feature. This information bottleneck trade-off strategy driven by downstream tasks not only helps to learn effective features of the data, but also improves the generalization of the model. This study's contribution lies in presenting a model with consistent performance and offering a fresh perspective on merging deep learning with sparse representation theory, grounded in the information bottleneck concept. Experimental results on CIFAR-10 and CIFAR-100 datasets demonstrate that IB-AdCSCNet not only matches the performance of deep residual convolutional networks but also outperforms them when handling corrupted data. Through the inference of the IB trade-off, the model's robustness is notably enhanced.
Multiple Key-value Strategy in Recommendation Systems Incorporating Large Language Model
Oct 25, 2023Recommendation system (RS) plays significant roles in matching users information needs for Internet applications, and it usually utilizes the vanilla neural network as the backbone to handle embedding details. Recently, the large language model (LLM) has exhibited emergent abilities and achieved great breakthroughs both in the CV and NLP communities. Thus, it is logical to incorporate RS with LLM better, which has become an emerging research direction. Although some existing works have made their contributions to this issue, they mainly consider the single key situation (e.g. historical interactions), especially in sequential recommendation. The situation of multiple key-value data is simply neglected. This significant scenario is mainstream in real practical applications, where the information of users (e.g. age, occupation, etc) and items (e.g. title, category, etc) has more than one key. Therefore, we aim to implement sequential recommendations based on multiple key-value data by incorporating RS with LLM. In particular, we instruct tuning a prevalent open-source LLM (Llama 7B) in order to inject domain knowledge of RS into the pre-trained LLM. Since we adopt multiple key-value strategies, LLM is hard to learn well among these keys. Thus the general and innovative shuffle and mask strategies, as an innovative manner of data argument, are designed. To demonstrate the effectiveness of our approach, extensive experiments are conducted on the popular and suitable dataset MovieLens which contains multiple keys-value. The experimental results demonstrate that our approach can nicely and effectively complete this challenging issue.
Stable and Compact Face Recognition via Unlabeled Data Driven Sparse Representation-Based Classification
Nov 04, 2021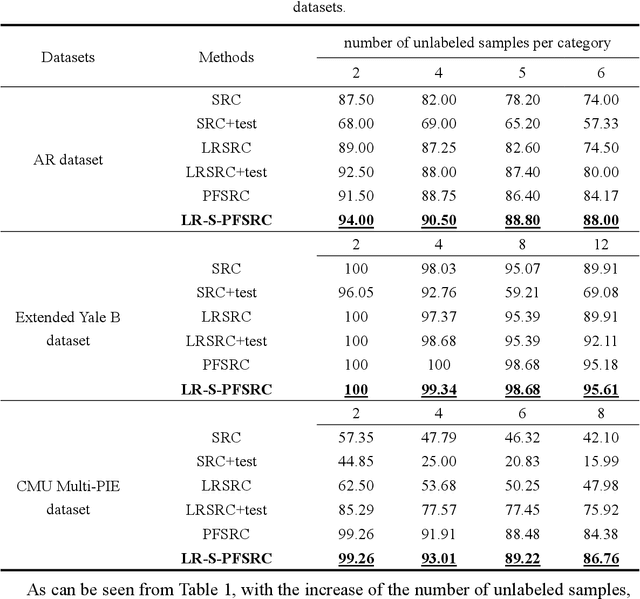
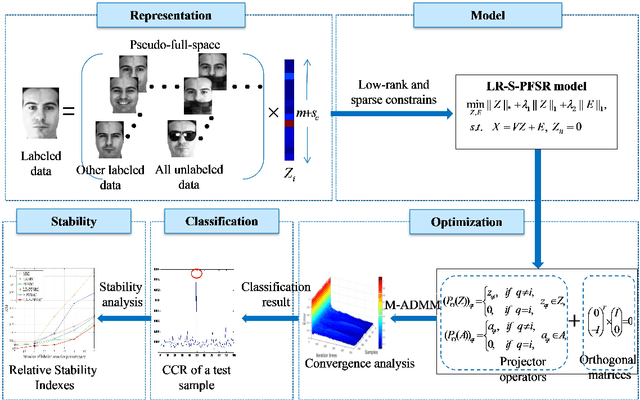
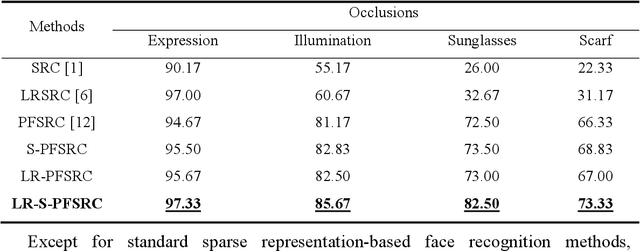

Sparse representation-based classification (SRC) has attracted much attention by casting the recognition problem as simple linear regression problem. SRC methods, however, still is limited to enough labeled samples per category, insufficient use of unlabeled samples, and instability of representation. For tackling these problems, an unlabeled data driven inverse projection pseudo-full-space representation-based classification model is proposed with low-rank sparse constraints. The proposed model aims to mine the hidden semantic information and intrinsic structure information of all available data, which is suitable for few labeled samples and proportion imbalance between labeled samples and unlabeled samples problems in frontal face recognition. The mixed Gauss-Seidel and Jacobian ADMM algorithm is introduced to solve the model. The convergence, representation capability and stability of the model are analyzed. Experiments on three public datasets show that the proposed LR-S-PFSRC model achieves stable results, especially for proportion imbalance of samples.
Breast Tumor Classification Based on Decision Information Genes and Inverse Projection Sparse Representation
Apr 17, 2018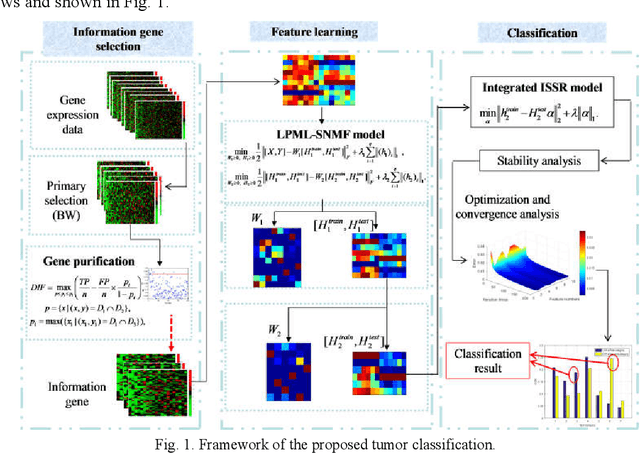
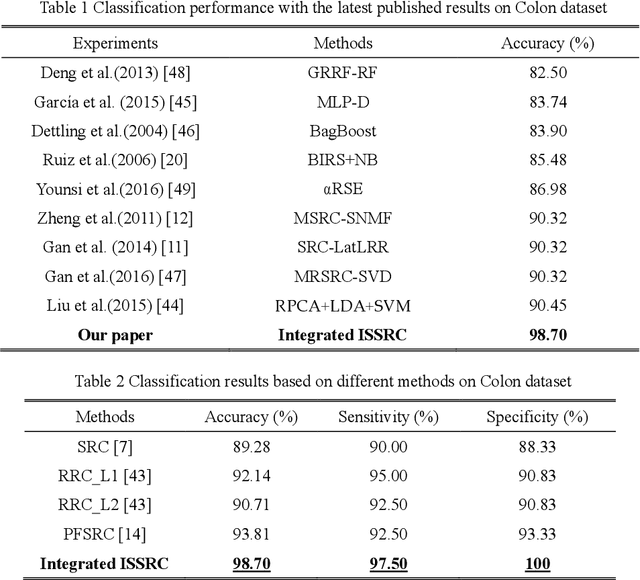
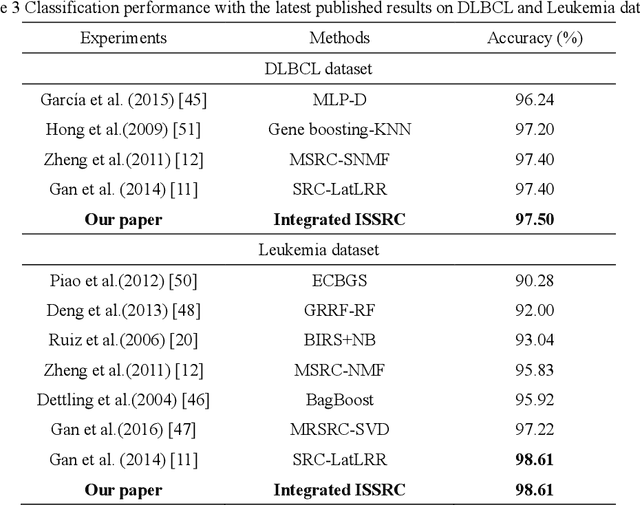
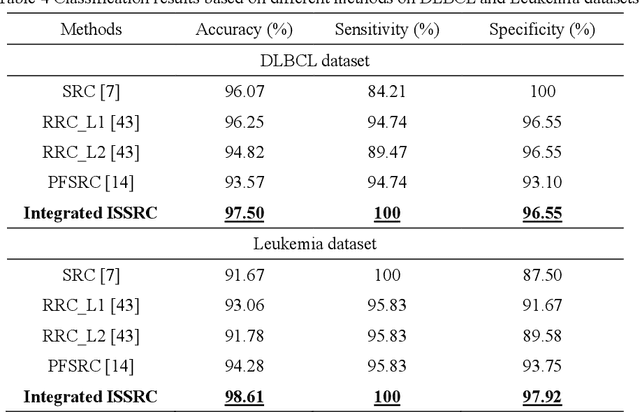
Microarray gene expression data-based breast tumor classification is an active and challenging issue. In this paper, a robust framework of breast tumor recognition is presented aiming at reducing clinical misdiagnosis rate and exploiting available information in existing samples. A wrapper gene selection method is established from a new perspective of reducing clinical misdiagnosis rate. The further feature selection of information genes is achieved using the modified NMF model, which is rooted in the use of hierarchical learning and layer-wise pre-training strategy in deep learning. For completing the classification, an inverse projection sparse representation (IPSR) model is constructed to exploit information embedded in existing samples, especially in the test ones. Moreover, the IPSR model is optimized through generalized ADMM and the corresponding convergence is analyzed. Extensive experiments on public microarray gene expression datasets show that the proposed method is stable and effective for breast tumor classification. Compared to the latest open literature, there is 14% higher in classification accuracy. Specificity and sensitivity achieve 94.17% and 97.5%, respectively.
Low Rank Variation Dictionary and Inverse Projection Group Sparse Representation Model for Breast Tumor Classification
Mar 10, 2018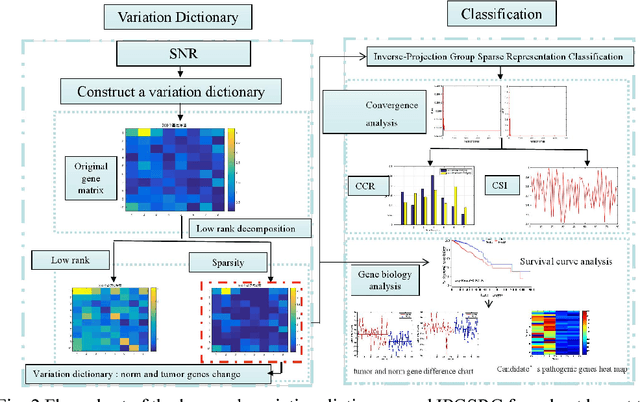
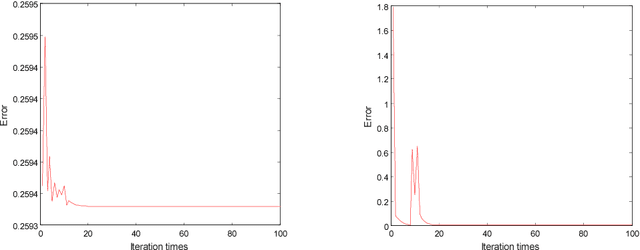
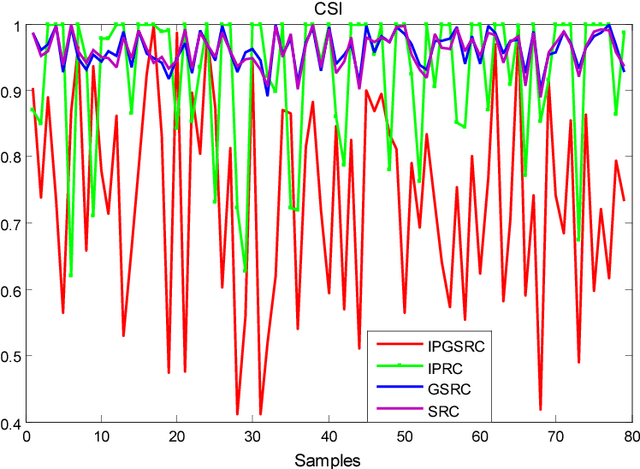
Sparse representation classification achieves good results by addressing recognition problem with sufficient training samples per subject. However, SRC performs not very well for small sample data. In this paper, an inverse-projection group sparse representation model is presented for breast tumor classification, which is based on constructing low-rank variation dictionary. The proposed low-rank variation dictionary tackles tumor recognition problem from the viewpoint of detecting and using variations in gene expression profiles of normal and patients, rather than directly using these samples. The inverse projection group sparsity representation model is constructed based on taking full using of exist samples and group effect of microarray gene data. Extensive experiments on public breast tumor microarray gene expression datasets demonstrate the proposed technique is competitive with state-of-the-art methods. The results of Breast-1, Breast-2 and Breast-3 databases are 80.81%, 89.10% and 100% respectively, which are better than the latest literature.