 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreast Tumor Classification Based on Decision Information Genes and Inverse Projection Sparse Representation
Apr 17, 2018
Microarray gene expression data-based breast tumor classification is an active and challenging issue. In this paper, a robust framework of breast tumor recognition is presented aiming at reducing clinical misdiagnosis rate and exploiting available information in existing samples. A wrapper gene selection method is established from a new perspective of reducing clinical misdiagnosis rate. The further feature selection of information genes is achieved using the modified NMF model, which is rooted in the use of hierarchical learning and layer-wise pre-training strategy in deep learning. For completing the classification, an inverse projection sparse representation (IPSR) model is constructed to exploit information embedded in existing samples, especially in the test ones. Moreover, the IPSR model is optimized through generalized ADMM and the corresponding convergence is analyzed. Extensive experiments on public microarray gene expression datasets show that the proposed method is stable and effective for breast tumor classification. Compared to the latest open literature, there is 14% higher in classification accuracy. Specificity and sensitivity achieve 94.17% and 97.5%, respectively.
Low Rank Variation Dictionary and Inverse Projection Group Sparse Representation Model for Breast Tumor Classification
Mar 10, 2018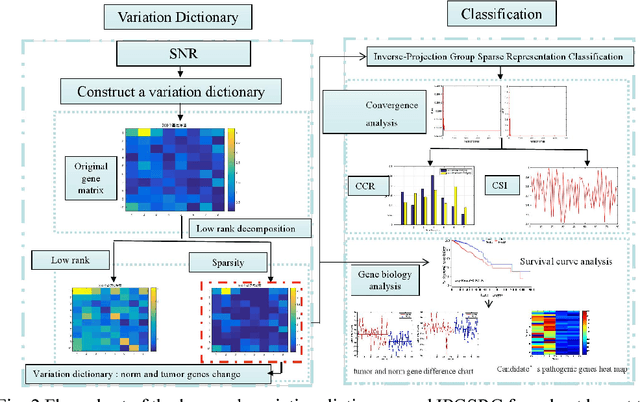
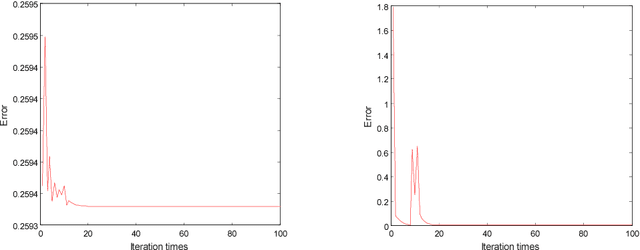
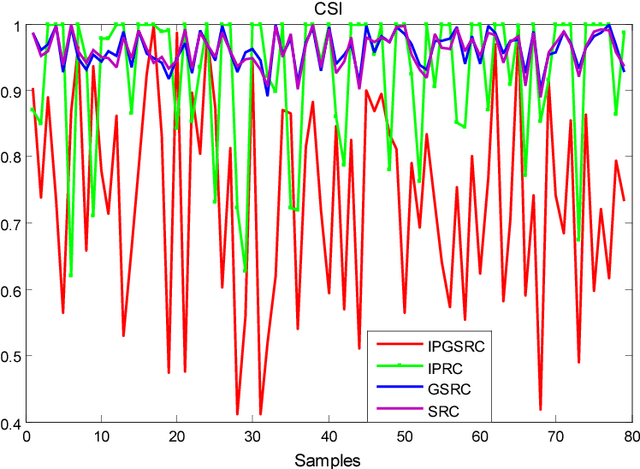
Sparse representation classification achieves good results by addressing recognition problem with sufficient training samples per subject. However, SRC performs not very well for small sample data. In this paper, an inverse-projection group sparse representation model is presented for breast tumor classification, which is based on constructing low-rank variation dictionary. The proposed low-rank variation dictionary tackles tumor recognition problem from the viewpoint of detecting and using variations in gene expression profiles of normal and patients, rather than directly using these samples. The inverse projection group sparsity representation model is constructed based on taking full using of exist samples and group effect of microarray gene data. Extensive experiments on public breast tumor microarray gene expression datasets demonstrate the proposed technique is competitive with state-of-the-art methods. The results of Breast-1, Breast-2 and Breast-3 databases are 80.81%, 89.10% and 100% respectively, which are better than the latest literature.