 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMET: Benchmark for Comprehensive Biological Multi-omics Evaluation Tasks and Language Models
Dec 13, 2024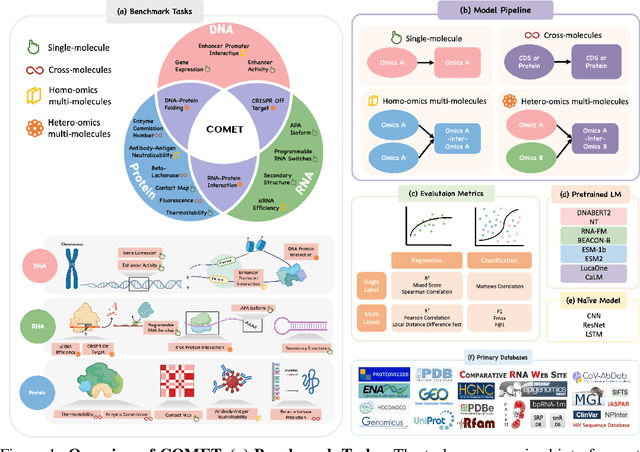
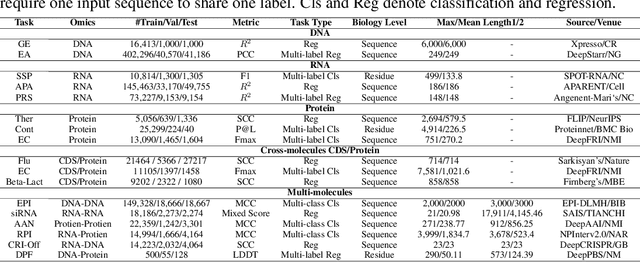
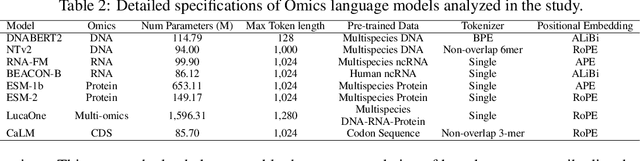
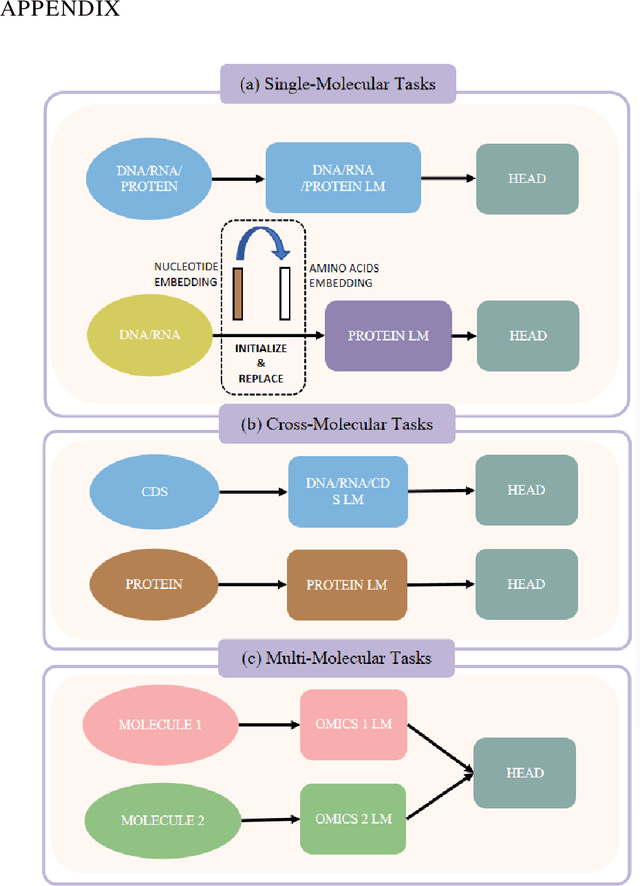
As key elements within the central dogma, DNA, RNA, and proteins play crucial roles in maintaining life by guaranteeing accurate genetic expression and implementation. Although research on these molecules has profoundly impacted fields like medicine, agriculture, and industry, the diversity of machine learning approaches-from traditional statistical methods to deep learning models and large language models-poses challenges for researchers in choosing the most suitable models for specific tasks, especially for cross-omics and multi-omics tasks due to the lack of comprehensive benchmarks. To address this, we introduce the first comprehensive multi-omics benchmark COMET (Benchmark for Biological COmprehensive Multi-omics Evaluation Tasks and Language Models), designed to evaluate models across single-omics, cross-omics, and multi-omics tasks. First, we curate and develop a diverse collection of downstream tasks and datasets covering key structural and functional aspects in DNA, RNA, and proteins, including tasks that span multiple omics levels. Then, we evaluate existing foundational language models for DNA, RNA, and proteins, as well as the newly proposed multi-omics method, offering valuable insights into their performance in integrating and analyzing data from different biological modalities. This benchmark aims to define critical issues in multi-omics research and guide future directions, ultimately promoting advancements in understanding biological processes through integrated and different omics data analysis.
GradiSeg: Gradient-Guided Gaussian Segmentation with Enhanced 3D Boundary Precision
Nov 30, 2024While 3D Gaussian Splatting enables high-quality real-time rendering, existing Gaussian-based frameworks for 3D semantic segmentation still face significant challenges in boundary recognition accuracy. To address this, we propose a novel 3DGS-based framework named GradiSeg, incorporating Identity Encoding to construct a deeper semantic understanding of scenes. Our approach introduces two key modules: Identity Gradient Guided Densification (IGD) and Local Adaptive K-Nearest Neighbors (LA-KNN). The IGD module supervises gradients of Identity Encoding to refine Gaussian distributions along object boundaries, aligning them closely with boundary contours. Meanwhile, the LA-KNN module employs position gradients to adaptively establish locality-aware propagation of Identity Encodings, preventing irregular Gaussian spreads near boundaries. We validate the effectiveness of our method through comprehensive experiments. Results show that GradiSeg effectively addresses boundary-related issues, significantly improving segmentation accuracy without compromising scene reconstruction quality. Furthermore, our method's robust segmentation capability and decoupled Identity Encoding representation make it highly suitable for various downstream scene editing tasks, including 3D object removal, swapping and so on.
An Embarrassingly Simple Approach to Enhance Transformer Performance in Genomic Selection for Crop Breeding
May 15, 2024Genomic selection (GS), as a critical crop breeding strategy, plays a key role in enhancing food production and addressing the global hunger crisis. The predominant approaches in GS currently revolve around employing statistical methods for prediction. However, statistical methods often come with two main limitations: strong statistical priors and linear assumptions. A recent trend is to capture the non-linear relationships between markers by deep learning. However, as crop datasets are commonly long sequences with limited samples, the robustness of deep learning models, especially Transformers, remains a challenge. In this work, to unleash the unexplored potential of attention mechanism for the task of interest, we propose a simple yet effective Transformer-based framework that enables end-to-end training of the whole sequence. Via experiments on rice3k and wheat3k datasets, we show that, with simple tricks such as k-mer tokenization and random masking, Transformer can achieve overall superior performance against seminal methods on GS tasks of interest.
Dual-Modality Vehicle Anomaly Detection via Bilateral Trajectory Tracing
Jun 09, 2021
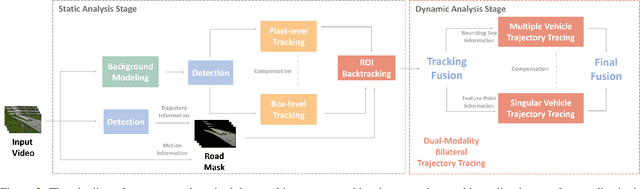
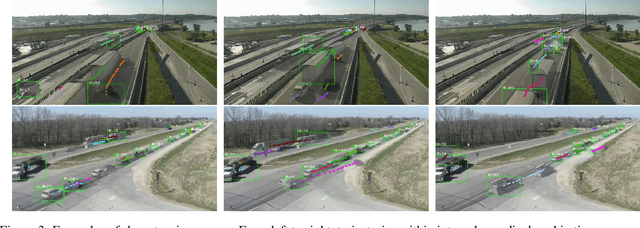
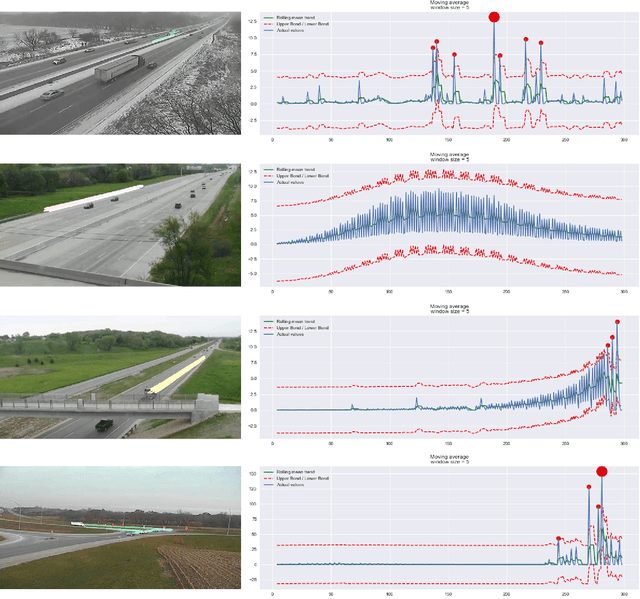
Traffic anomaly detection has played a crucial role in Intelligent Transportation System (ITS). The main challenges of this task lie in the highly diversified anomaly scenes and variational lighting conditions. Although much work has managed to identify the anomaly in homogenous weather and scene, few resolved to cope with complex ones. In this paper, we proposed a dual-modality modularized methodology for the robust detection of abnormal vehicles. We introduced an integrated anomaly detection framework comprising the following modules: background modeling, vehicle tracking with detection, mask construction, Region of Interest (ROI) backtracking, and dual-modality tracing. Concretely, we employed background modeling to filter the motion information and left the static information for later vehicle detection. For the vehicle detection and tracking module, we adopted YOLOv5 and multi-scale tracking to localize the anomalies. Besides, we utilized the frame difference and tracking results to identify the road and obtain the mask. In addition, we introduced multiple similarity estimation metrics to refine the anomaly period via backtracking. Finally, we proposed a dual-modality bilateral tracing module to refine the time further. The experiments conducted on the Track 4 testset of the NVIDIA 2021 AI City Challenge yielded a result of 0.9302 F1-Score and 3.4039 root mean square error (RMSE), indicating the effectiveness of our framework.