 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Distortion Aware Efficient Transformer Adaptation for Image Quality Assessment
Aug 23, 2023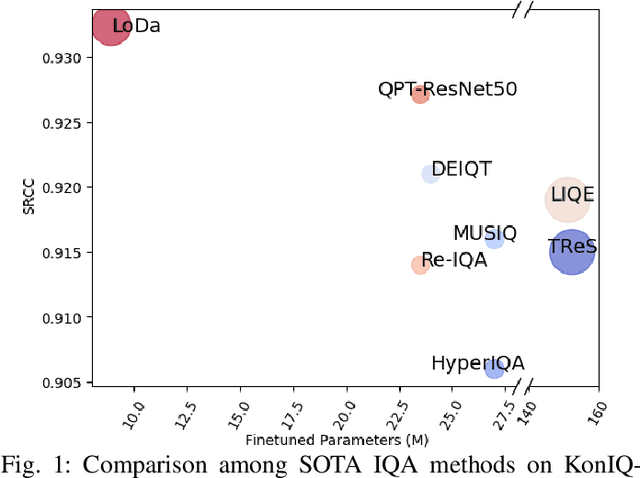
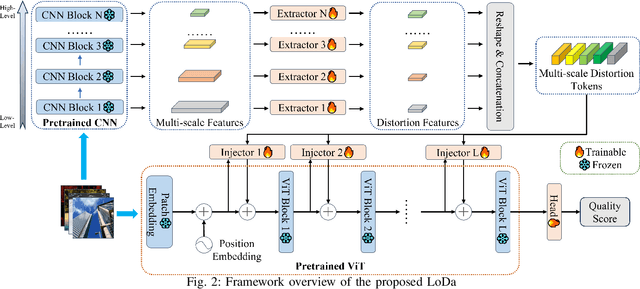
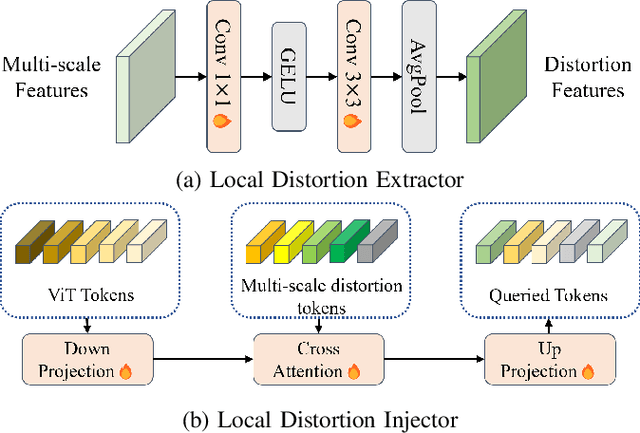
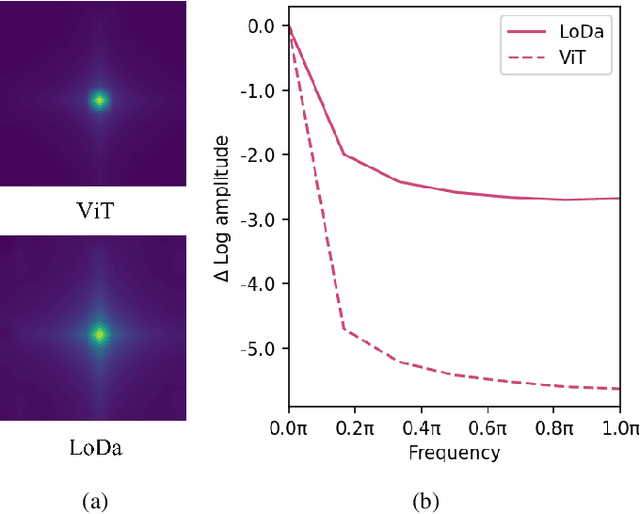
Image Quality Assessment (IQA) constitutes a fundamental task within the field of computer vision, yet it remains an unresolved challenge, owing to the intricate distortion conditions, diverse image contents, and limited availability of data. Recently, the community has witnessed the emergence of numerous large-scale pretrained foundation models, which greatly benefit from dramatically increased data and parameter capacities. However, it remains an open problem whether the scaling law in high-level tasks is also applicable to IQA task which is closely related to low-level clues. In this paper, we demonstrate that with proper injection of local distortion features, a larger pretrained and fixed foundation model performs better in IQA tasks. Specifically, for the lack of local distortion structure and inductive bias of vision transformer (ViT), alongside the large-scale pretrained ViT, we use another pretrained convolution neural network (CNN), which is well known for capturing the local structure, to extract multi-scale image features. Further, we propose a local distortion extractor to obtain local distortion features from the pretrained CNN and a local distortion injector to inject the local distortion features into ViT. By only training the extractor and injector, our method can benefit from the rich knowledge in the powerful foundation models and achieve state-of-the-art performance on popular IQA datasets, indicating that IQA is not only a low-level problem but also benefits from stronger high-level features drawn from large-scale pretrained models.
Exploring the Effectiveness of Video Perceptual Representation in Blind Video Quality Assessment
Jul 08, 2022



With the rapid growth of in-the-wild videos taken by non-specialists, blind video quality assessment (VQA) has become a challenging and demanding problem. Although lots of efforts have been made to solve this problem, it remains unclear how the human visual system (HVS) relates to the temporal quality of videos. Meanwhile, recent work has found that the frames of natural video transformed into the perceptual domain of the HVS tend to form a straight trajectory of the representations. With the obtained insight that distortion impairs the perceived video quality and results in a curved trajectory of the perceptual representation, we propose a temporal perceptual quality index (TPQI) to measure the temporal distortion by describing the graphic morphology of the representation. Specifically, we first extract the video perceptual representations from the lateral geniculate nucleus (LGN) and primary visual area (V1) of the HVS, and then measure the straightness and compactness of their trajectories to quantify the degradation in naturalness and content continuity of video. Experiments show that the perceptual representation in the HVS is an effective way of predicting subjective temporal quality, and thus TPQI can, for the first time, achieve comparable performance to the spatial quality metric and be even more effective in assessing videos with large temporal variations. We further demonstrate that by combining with NIQE, a spatial quality metric, TPQI can achieve top performance over popular in-the-wild video datasets. More importantly, TPQI does not require any additional information beyond the video being evaluated and thus can be applied to any datasets without parameter tuning. Source code is available at https://github.com/UoLMM/TPQI-VQA.
* Will appear on ACM MM 2022
Dual-Modality Vehicle Anomaly Detection via Bilateral Trajectory Tracing
Jun 09, 2021
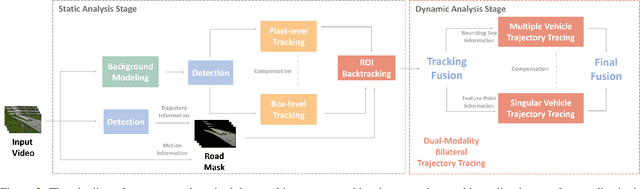
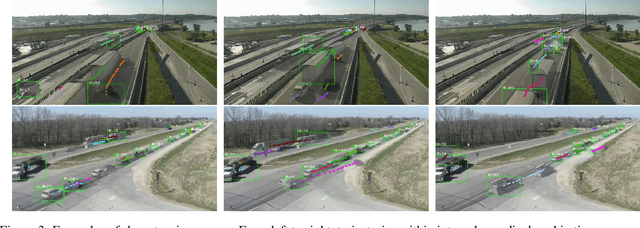
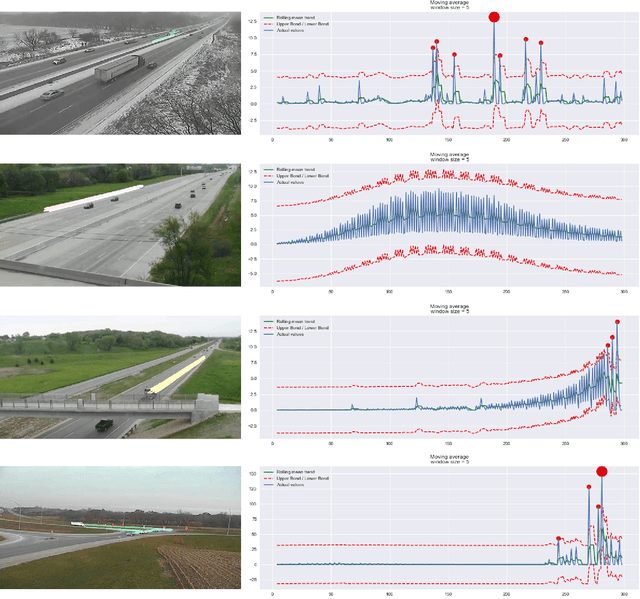
Traffic anomaly detection has played a crucial role in Intelligent Transportation System (ITS). The main challenges of this task lie in the highly diversified anomaly scenes and variational lighting conditions. Although much work has managed to identify the anomaly in homogenous weather and scene, few resolved to cope with complex ones. In this paper, we proposed a dual-modality modularized methodology for the robust detection of abnormal vehicles. We introduced an integrated anomaly detection framework comprising the following modules: background modeling, vehicle tracking with detection, mask construction, Region of Interest (ROI) backtracking, and dual-modality tracing. Concretely, we employed background modeling to filter the motion information and left the static information for later vehicle detection. For the vehicle detection and tracking module, we adopted YOLOv5 and multi-scale tracking to localize the anomalies. Besides, we utilized the frame difference and tracking results to identify the road and obtain the mask. In addition, we introduced multiple similarity estimation metrics to refine the anomaly period via backtracking. Finally, we proposed a dual-modality bilateral tracing module to refine the time further. The experiments conducted on the Track 4 testset of the NVIDIA 2021 AI City Challenge yielded a result of 0.9302 F1-Score and 3.4039 root mean square error (RMSE), indicating the effectiveness of our framework.