 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRUE: A Practical Recipe for Field Boundary Segmentation at Scale
Mar 28, 2026Large-scale maps of field boundaries are essential for agricultural monitoring tasks. Existing deep learning approaches for satellite-based field mapping are sensitive to illumination, spatial scale, and changes in geographic location. We conduct the first systematic evaluation of segmentation and geospatial foundation models (GFMs) for global field boundary delineation using the Fields of The World (FTW) benchmark. We evaluate 18 models under unified experimental settings, showing that a U-Net semantic segmentation model outperforms instance-based and GFM alternatives on a suite of performance and deployment metrics. We propose a new segmentation approach that combines a U-Net backbone, composite loss functions, and targeted data augmentations to enhance performance and robustness under real-world conditions. Our model achieves a 76\% IoU and 47\% object-F1 on FTW, an increase of 6\% and 9\% over the previous baseline. Our approach provides a practical framework for reliable, scalable, and reproducible field boundary delineation across model design, training, and inference. We release all models and model-derived field boundary datasets for five countries.
TimeSense:Making Large Language Models Proficient in Time-Series Analysis
Nov 09, 2025In the time-series domain, an increasing number of works combine text with temporal data to leverage the reasoning capabilities of large language models (LLMs) for various downstream time-series understanding tasks. This enables a single model to flexibly perform tasks that previously required specialized models for each domain. However, these methods typically rely on text labels for supervision during training, biasing the model toward textual cues while potentially neglecting the full temporal features. Such a bias can lead to outputs that contradict the underlying time-series context. To address this issue, we construct the EvalTS benchmark, comprising 10 tasks across three difficulty levels, from fundamental temporal pattern recognition to complex real-world reasoning, to evaluate models under more challenging and realistic scenarios. We also propose TimeSense, a multimodal framework that makes LLMs proficient in time-series analysis by balancing textual reasoning with a preserved temporal sense. TimeSense incorporates a Temporal Sense module that reconstructs the input time-series within the model's context, ensuring that textual reasoning is grounded in the time-series dynamics. Moreover, to enhance spatial understanding of time-series data, we explicitly incorporate coordinate-based positional embeddings, which provide each time point with spatial context and enable the model to capture structural dependencies more effectively. Experimental results demonstrate that TimeSense achieves state-of-the-art performance across multiple tasks, and it particularly outperforms existing methods on complex multi-dimensional time-series reasoning tasks.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
PEACE: Empowering Geologic Map Holistic Understanding with MLLMs
Jan 10, 2025



Geologic map, as a fundamental diagram in geology science, provides critical insights into the structure and composition of Earth's subsurface and surface. These maps are indispensable in various fields, including disaster detection, resource exploration, and civil engineering. Despite their significance, current Multimodal Large Language Models (MLLMs) often fall short in geologic map understanding. This gap is primarily due to the challenging nature of cartographic generalization, which involves handling high-resolution map, managing multiple associated components, and requiring domain-specific knowledge. To quantify this gap, we construct GeoMap-Bench, the first-ever benchmark for evaluating MLLMs in geologic map understanding, which assesses the full-scale abilities in extracting, referring, grounding, reasoning, and analyzing. To bridge this gap, we introduce GeoMap-Agent, the inaugural agent designed for geologic map understanding, which features three modules: Hierarchical Information Extraction (HIE), Domain Knowledge Injection (DKI), and Prompt-enhanced Question Answering (PEQA). Inspired by the interdisciplinary collaboration among human scientists, an AI expert group acts as consultants, utilizing a diverse tool pool to comprehensively analyze questions. Through comprehensive experiments, GeoMap-Agent achieves an overall score of 0.811 on GeoMap-Bench, significantly outperforming 0.369 of GPT-4o. Our work, emPowering gEologic mAp holistiC undErstanding (PEACE) with MLLMs, paves the way for advanced AI applications in geology, enhancing the efficiency and accuracy of geological investigations.
Dual-Modality Vehicle Anomaly Detection via Bilateral Trajectory Tracing
Jun 09, 2021
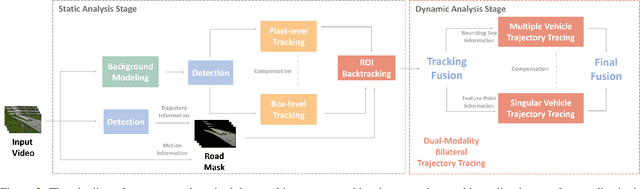
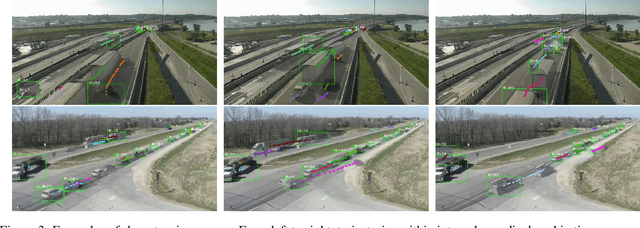
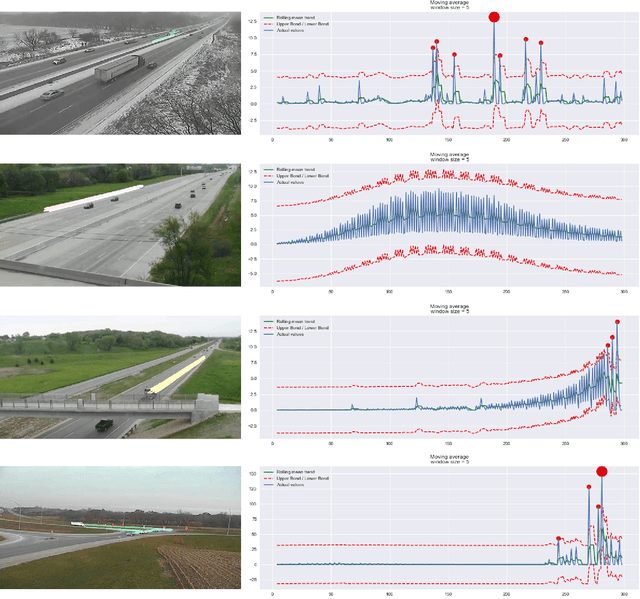
Traffic anomaly detection has played a crucial role in Intelligent Transportation System (ITS). The main challenges of this task lie in the highly diversified anomaly scenes and variational lighting conditions. Although much work has managed to identify the anomaly in homogenous weather and scene, few resolved to cope with complex ones. In this paper, we proposed a dual-modality modularized methodology for the robust detection of abnormal vehicles. We introduced an integrated anomaly detection framework comprising the following modules: background modeling, vehicle tracking with detection, mask construction, Region of Interest (ROI) backtracking, and dual-modality tracing. Concretely, we employed background modeling to filter the motion information and left the static information for later vehicle detection. For the vehicle detection and tracking module, we adopted YOLOv5 and multi-scale tracking to localize the anomalies. Besides, we utilized the frame difference and tracking results to identify the road and obtain the mask. In addition, we introduced multiple similarity estimation metrics to refine the anomaly period via backtracking. Finally, we proposed a dual-modality bilateral tracing module to refine the time further. The experiments conducted on the Track 4 testset of the NVIDIA 2021 AI City Challenge yielded a result of 0.9302 F1-Score and 3.4039 root mean square error (RMSE), indicating the effectiveness of our framework.