 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Can Frontier LLMs Pass a Standardized Office Proficiency Exam?
Jun 09, 2026The deployment of Large Language Model (LLM) agents for computer automation is accelerating, yet their ability to navigate complex, professional-grade productivity software is largely untested. We argue that Office automation is an ideal environment for benchmarking document-automation capability, as it requires long-horizon planning and reasoning, precise parameter configuration, and multi-application integration. To quantify this capability, we introduce an evaluation based on China's National Computer Rank Examination (NCRE), featuring 200 comprehensive practical-operation tasks across Word, Excel, and PowerPoint. Each task is scored on a 100-point rubric scale using 7,118 machine-gradable criteria, and Score Rate (SR) denotes the mean percentage of rubric points earned across these tasks. We benchmark 7 frontier LLMs and observe stark limitations: single-turn models score a maximum of 36.6%. A stronger agentic system with execution feedback, iterative repair, and broader Office automation access reaches 68.8%, but remains below the 95.5% community-reference score used as a scoring sanity check. Ultimately, our experiments demonstrate that despite recent advancements in code generation, achieving reliable fine-grained Office document automation remains a significant challenge for current code-generating LLM and agent systems.
Scaling Data Difficulty: Improving Coding Models via Reinforcement Learning on Fresh and Challenging Problems
Mar 08, 2026Training next-generation code generation models requires high-quality datasets, yet existing datasets face difficulty imbalance, format inconsistency, and data quality problems. We address these challenges through systematic data processing and difficulty scaling. We introduce a four-stage Data Processing Framework encompassing collection, processing, filtering, and verification, incorporating Automatic Difficulty Filtering via an LLM-based predict-calibrate-select framework that leverages multi-dimensional difficulty metrics across five weighted dimensions to retain challenging problems while removing simplistic ones. The resulting MicroCoder dataset comprises tens of thousands of curated real competitive programming problems from diverse platforms, emphasizing recency and difficulty. Evaluations on strictly unseen LiveCodeBench demonstrate that MicroCoder achieves 3x larger performance gains within 300 training steps compared to widely-used baseline datasets of comparable size, with consistent advantages under both GRPO and its variant training algorithms. The MicroCoder dataset delivers obvious improvements on medium and hard problems across different model sizes, achieving up to 17.2% relative gains in overall performance where model capabilities are most stretched. These results validate that difficulty-aware data curation improves model performance on challenging tasks, providing multiple insights for dataset creation in code generation.
Geometric-Mean Policy Optimization
Jul 28, 2025Recent advancements, such as Group Relative Policy Optimization (GRPO), have enhanced the reasoning capabilities of large language models by optimizing the arithmetic mean of token-level rewards. However, GRPO suffers from unstable policy updates when processing tokens with outlier importance-weighted rewards, which manifests as extreme importance sampling ratios during training, i.e., the ratio between the sampling probabilities assigned to a token by the current and old policies. In this work, we propose Geometric-Mean Policy Optimization (GMPO), a stabilized variant of GRPO. Instead of optimizing the arithmetic mean, GMPO maximizes the geometric mean of token-level rewards, which is inherently less sensitive to outliers and maintains a more stable range of importance sampling ratio. In addition, we provide comprehensive theoretical and experimental analysis to justify the design and stability benefits of GMPO. Beyond improved stability, GMPO-7B outperforms GRPO by an average of 4.1% on multiple mathematical benchmarks and 1.4% on multimodal reasoning benchmark, including AIME24, AMC, MATH500, OlympiadBench, Minerva, and Geometry3K. Code is available at https://github.com/callsys/GMPO.
Think Only When You Need with Large Hybrid-Reasoning Models
May 21, 2025Recent Large Reasoning Models (LRMs) have shown substantially improved reasoning capabilities over traditional Large Language Models (LLMs) by incorporating extended thinking processes prior to producing final responses. However, excessively lengthy thinking introduces substantial overhead in terms of token consumption and latency, which is particularly unnecessary for simple queries. In this work, we introduce Large Hybrid-Reasoning Models (LHRMs), the first kind of model capable of adaptively determining whether to perform thinking based on the contextual information of user queries. To achieve this, we propose a two-stage training pipeline comprising Hybrid Fine-Tuning (HFT) as a cold start, followed by online reinforcement learning with the proposed Hybrid Group Policy Optimization (HGPO) to implicitly learn to select the appropriate thinking mode. Furthermore, we introduce a metric called Hybrid Accuracy to quantitatively assess the model's capability for hybrid thinking. Extensive experimental results show that LHRMs can adaptively perform hybrid thinking on queries of varying difficulty and type. It outperforms existing LRMs and LLMs in reasoning and general capabilities while significantly improving efficiency. Together, our work advocates for a reconsideration of the appropriate use of extended thinking processes and provides a solid starting point for building hybrid thinking systems.
Model as a Game: On Numerical and Spatial Consistency for Generative Games
Mar 27, 2025Recent advances in generative models have significantly impacted game generation. However, despite producing high-quality graphics and adequately receiving player input, existing models often fail to maintain fundamental game properties such as numerical and spatial consistency. Numerical consistency ensures gameplay mechanics correctly reflect score changes and other quantitative elements, while spatial consistency prevents jarring scene transitions, providing seamless player experiences. In this paper, we revisit the paradigm of generative games to explore what truly constitutes a Model as a Game (MaaG) with a well-developed mechanism. We begin with an empirical study on ``Traveler'', a 2D game created by an LLM featuring minimalist rules yet challenging generative models in maintaining consistency. Based on the DiT architecture, we design two specialized modules: (1) a numerical module that integrates a LogicNet to determine event triggers, with calculations processed externally as conditions for image generation; and (2) a spatial module that maintains a map of explored areas, retrieving location-specific information during generation and linking new observations to ensure continuity. Experiments across three games demonstrate that our integrated modules significantly enhance performance on consistency metrics compared to baselines, while incurring minimal time overhead during inference.
PEACE: Empowering Geologic Map Holistic Understanding with MLLMs
Jan 10, 2025



Geologic map, as a fundamental diagram in geology science, provides critical insights into the structure and composition of Earth's subsurface and surface. These maps are indispensable in various fields, including disaster detection, resource exploration, and civil engineering. Despite their significance, current Multimodal Large Language Models (MLLMs) often fall short in geologic map understanding. This gap is primarily due to the challenging nature of cartographic generalization, which involves handling high-resolution map, managing multiple associated components, and requiring domain-specific knowledge. To quantify this gap, we construct GeoMap-Bench, the first-ever benchmark for evaluating MLLMs in geologic map understanding, which assesses the full-scale abilities in extracting, referring, grounding, reasoning, and analyzing. To bridge this gap, we introduce GeoMap-Agent, the inaugural agent designed for geologic map understanding, which features three modules: Hierarchical Information Extraction (HIE), Domain Knowledge Injection (DKI), and Prompt-enhanced Question Answering (PEQA). Inspired by the interdisciplinary collaboration among human scientists, an AI expert group acts as consultants, utilizing a diverse tool pool to comprehensively analyze questions. Through comprehensive experiments, GeoMap-Agent achieves an overall score of 0.811 on GeoMap-Bench, significantly outperforming 0.369 of GPT-4o. Our work, emPowering gEologic mAp holistiC undErstanding (PEACE) with MLLMs, paves the way for advanced AI applications in geology, enhancing the efficiency and accuracy of geological investigations.
MMLU-CF: A Contamination-free Multi-task Language Understanding Benchmark
Dec 19, 2024



Multiple-choice question (MCQ) datasets like Massive Multitask Language Understanding (MMLU) are widely used to evaluate the commonsense, understanding, and problem-solving abilities of large language models (LLMs). However, the open-source nature of these benchmarks and the broad sources of training data for LLMs have inevitably led to benchmark contamination, resulting in unreliable evaluation results. To alleviate this issue, we propose a contamination-free and more challenging MCQ benchmark called MMLU-CF. This benchmark reassesses LLMs' understanding of world knowledge by averting both unintentional and malicious data leakage. To avoid unintentional data leakage, we source data from a broader domain and design three decontamination rules. To prevent malicious data leakage, we divide the benchmark into validation and test sets with similar difficulty and subject distributions. The test set remains closed-source to ensure reliable results, while the validation set is publicly available to promote transparency and facilitate independent verification. Our evaluation of mainstream LLMs reveals that the powerful GPT-4o achieves merely a 5-shot score of 73.4% and a 0-shot score of 71.9% on the test set, which indicates the effectiveness of our approach in creating a more rigorous and contamination-free evaluation standard. The GitHub repository is available at https://github.com/microsoft/MMLU-CF and the dataset refers to https://huggingface.co/datasets/microsoft/MMLU-CF.
RedStone: Curating General, Code, Math, and QA Data for Large Language Models
Dec 04, 2024
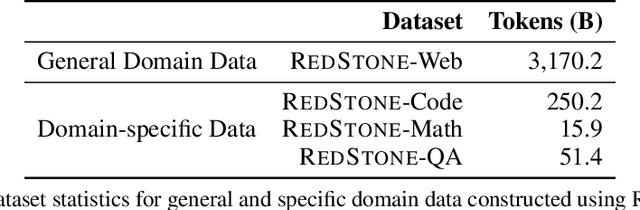
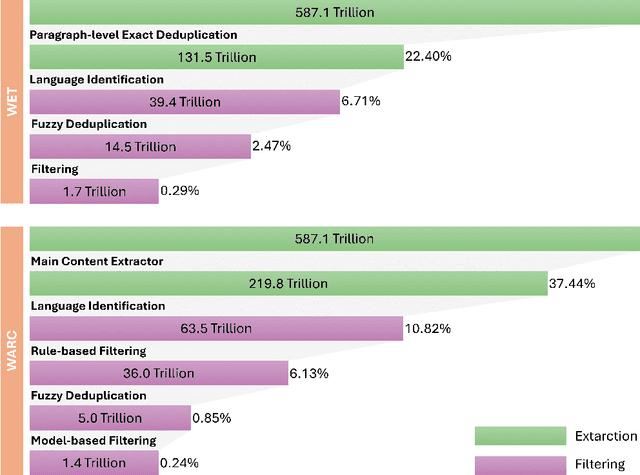
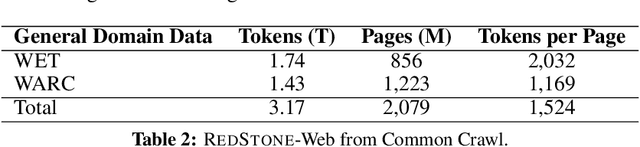
Pre-training Large Language Models (LLMs) on high-quality, meticulously curated datasets is widely recognized as critical for enhancing their performance and generalization capabilities. This study explores the untapped potential of Common Crawl as a comprehensive and flexible resource for pre-training LLMs, addressing both general-purpose language understanding and specialized domain knowledge. We introduce RedStone, an innovative and scalable pipeline engineered to extract and process data from Common Crawl, facilitating the creation of extensive and varied pre-training datasets. Unlike traditional datasets, which often require expensive curation and domain-specific expertise, RedStone leverages the breadth of Common Crawl to deliver datasets tailored to a wide array of domains. In this work, we exemplify its capability by constructing pre-training datasets across multiple fields, including general language understanding, code, mathematics, and question-answering tasks. The flexibility of RedStone allows for easy adaptation to other specialized domains, significantly lowering the barrier to creating valuable domain-specific datasets. Our findings demonstrate that Common Crawl, when harnessed through effective pipelines like RedStone, can serve as a rich, renewable source of pre-training data, unlocking new avenues for domain adaptation and knowledge discovery in LLMs. This work also underscores the importance of innovative data acquisition strategies and highlights the role of web-scale data as a powerful resource in the continued evolution of LLMs. RedStone code and data samples will be publicly available at \url{https://aka.ms/redstone}.
TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering
Nov 28, 2023
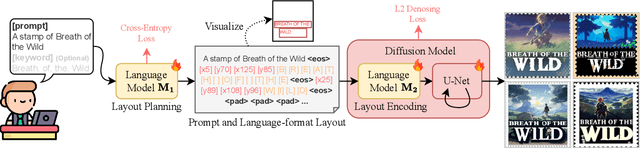
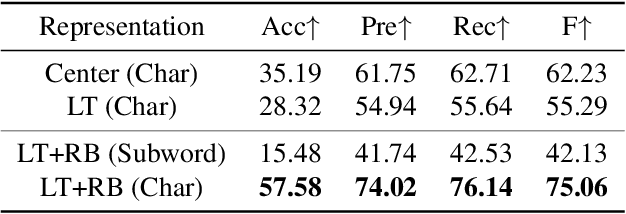
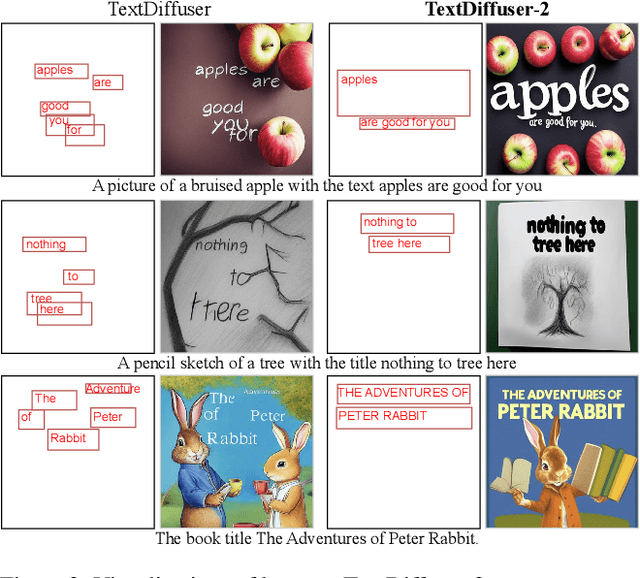
The diffusion model has been proven a powerful generative model in recent years, yet remains a challenge in generating visual text. Several methods alleviated this issue by incorporating explicit text position and content as guidance on where and what text to render. However, these methods still suffer from several drawbacks, such as limited flexibility and automation, constrained capability of layout prediction, and restricted style diversity. In this paper, we present TextDiffuser-2, aiming to unleash the power of language models for text rendering. Firstly, we fine-tune a large language model for layout planning. The large language model is capable of automatically generating keywords for text rendering and also supports layout modification through chatting. Secondly, we utilize the language model within the diffusion model to encode the position and texts at the line level. Unlike previous methods that employed tight character-level guidance, this approach generates more diverse text images. We conduct extensive experiments and incorporate user studies involving human participants as well as GPT-4V, validating TextDiffuser-2's capacity to achieve a more rational text layout and generation with enhanced diversity. The code and model will be available at \url{https://aka.ms/textdiffuser-2}.
Kosmos-2.5: A Multimodal Literate Model
Sep 20, 2023



We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.